Scary Scalar Functions series overview
- Part One: Parallelism
- Part Two: Performance
- Part Three: The Cure
Foreword
In the first two parts, we have seen why the Scalar functions (UDFs) are a problem for the performance. So how do we deal with it now that we know it’s a problem?
There is only one solution:
I say we take off and nuke the entire site from orbit. It’s the only way to be sure.
— Ellen Ripley
That might have been a hyperbole (or was it)? But the best solution is to eliminate UDFs as much as possible. I’ll show you some ways how to do that safely.
Minimizing the impact
If you’re not ready to go scorched earth on the UDFs, there are some ways to optimize them.
Make them deterministic
Adding SCHEMABINDING to a Scalar UDF is necessary to make it deterministic.
Taken from the documentation
Deterministic functions must be schema-bound. Use the SCHEMABINDING clause when creating a deterministic function.
And be sure to check this great answer as well.
Determinism can positively impact performance and it’s easily implemented as well.
I always add SCHEMABINDING to a function that doesn’t access data because it’s a free win.
Otherwise, it can be a double-edged sword. The SCHEMABINDING will unsurprisingly prevent changes to a schema, so deployments and refactorings might be more complex.
Return NULL on NULL input
Taken from the documentation (emphasis mine)
If RETURNS NULL ON NULL INPUT is specified in a CLR function, it indicates that SQL Server can return NULL when any of the arguments it receives is NULL, without actually invoking the body of the function.
Skipping the NULL rows means it won’t be Row-by-agonizing-row (RBAR) anymore, but it will be row-by-agonizing-not-null-row (RBANNR) - which is slightly better.
It’s hard to test all the code paths a UDF might have to see if this makes sense. But if the Scalar UDF has only one parameter, this snippet will help you construct the queries to check for the easy wins.
; -- Previous statement must be properly terminated
WITH singleParamObjects
AS
(
SELECT
p.object_id
FROM sys.parameters AS p
WHERE p.name <> N''
GROUP BY p.object_id
HAVING COUNT(1) = 1
)
SELECT
o.object_id AS objId
, OBJECT_SCHEMA_NAME(o.object_id) AS schName
, o.name AS objName
, p.name AS paramName
, CONCAT
(
'SELECT '
, ''''
, ca.FullName
, ''''
, ' AS FnName, '
, ca.FullName
, '(NULL) AS FnResult;'
) AS DynamicExecute
FROM sys.objects AS o
JOIN sys.parameters AS p
ON p.object_id = o.object_id
AND p.name <> N''
JOIN singleParamObjects AS spp
ON spp.object_id = p.object_id
CROSS APPLY
(
VALUES
(
CONCAT
(
QUOTENAME(OBJECT_SCHEMA_NAME(o.object_id))
, '.'
, QUOTENAME(o.name)
)
)
) AS ca (FullName)
WHERE o.type = 'FN'
Constants when working with sets
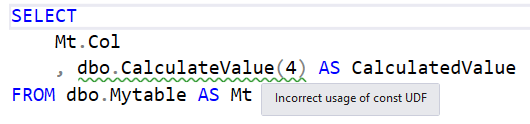
I sometimes see this antipattern:
SELECT
Mt.Col
, dbo.CalculateValue(4) AS CalculatedValue
FROM dbo.Mytable AS Mt
The Scalar UDF in the SELECT clause has a constant for a parameter. A constant in a function means a constant return value. Therefore, there is no point in invoking it for every row.
SQL Prompt’s Code Analysis also warns about this.
An easy fix is to move the constant into a variable - like this:
DECLARE @CalculatedValue int = dbo.CalculateValue(4)
SELECT
Mt.Col
, @CalculatedValue AS CalculatedValue
FROM dbo.Mytable AS Mt
Removing the Scalar UDFs
Scalar UDFs are a disease, a cancer of this product. It’s a plague, and inlining is the cure.
— Agent Smith (probably)
Apart from the DROP statement, the standard way to fix Scalar UDFs is inlining. Inlining is sometimes referred to as a View with parameters.
Automatic Scalar UDF Inlining
If you are on SQL Server 2019 (Compatibility level 150), you have access to Scalar UDF Inlining - codename Froid.
The upside is that you don’t have to change the interface.
The downside is that it has 20+ requirements, as documented here
I’ve picked a few examples
- The UDF doesn’t invoke any intrinsic function that is either time-dependent (such as GETDATE()) or has side effects 3 (such as NEWSEQUENTIALID())
- The UDF doesn’t reference table variables or table-valued parameters.
- The UDF isn’t used in a computed column or a check constraint definition.
- The UDF doesn’t contain references to Common Table Expressions (CTEs)
- The query invoking the UDF doesn’t have Common Table Expressions (CTEs)
Also, there is a list of fixed inlining bugs since its release.
Unfortunately, it’s pretty long, which doesn’t inspire confidence.
Let’s repeat the UDF function in a SELECT clause from Part 1
First, we need to reenable the Database scoped configuration and then run the code
USE ScalarFunction;
GO
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON
GO
SELECT TOP (10000)
n.Id
, n.Filler
, dbo.DoNothing(n.Id) AS ScalarId
FROM dbo.Nums AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
ORDER BY n.Id
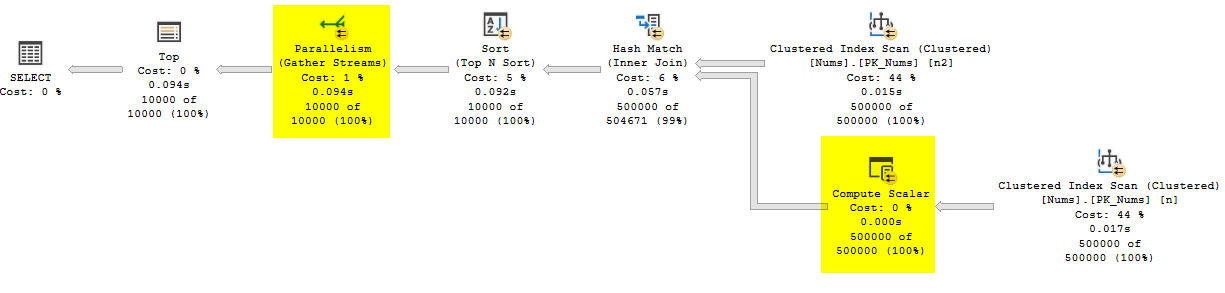
The previous plan for comparison
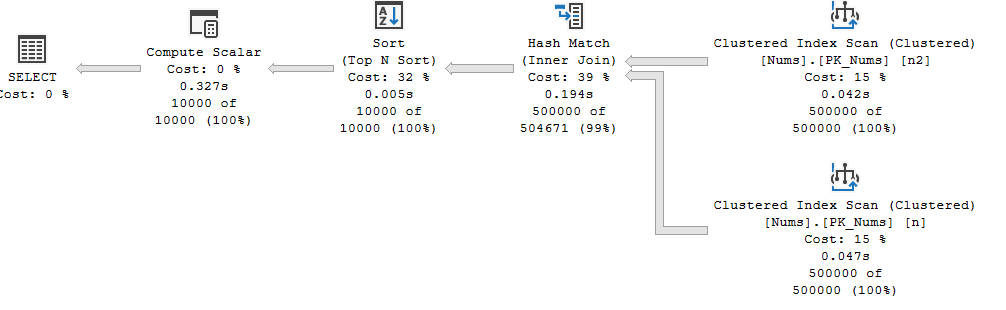
The actual execution plan XML also contains the attribute ContainsInlineScalarTsqlUdfs="true".
<QueryPlan
DegreeOfParallelism="4"
MemoryGrant="403720"
CachedPlanSize="64"
CompileTime="4"
CompileCPU="3"
CompileMemory="504"
ContainsInlineScalarTsqlUdfs="true"
>
Please note that every reference is evaluated separately based on context.
If I were to rewrite that query to use a CTE:
; -- Previous statement must be properly terminated
WITH cte
AS
(
SELECT
n.Id
, n.Filler
FROM dbo.Nums AS n
)
SELECT TOP (10000)
n.Id
, n.Filler
, dbo.DoNothing(n.Id) AS ScalarId
FROM cte AS n
JOIN dbo.Nums AS n2
ON n.Filler = n2.Filler
ORDER BY n.Id
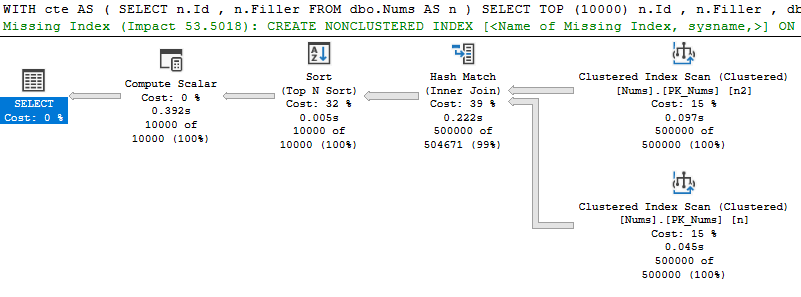
The query is not inlined because of the CTE requirement mentioned earlier. The same would apply to a CHECK constraint or a Computed column.
You can check which Scalar UDFs are eligible for inlining with this code.
SELECT
o.object_id AS objId
, OBJECT_SCHEMA_NAME(o.object_id) AS schName
, o.name AS objName
, sm.is_inlineable
FROM
sys.sql_modules AS sm
JOIN sys.objects AS o
ON sm.object_id = o.object_id
WHERE
o.type = 'FN'
AND sm.is_inlineable = 1
Manual Scalar inlining
It’s what it says on the box - you must rewrite it yourself to an Inline Table-Valued Function (ITVF).
It would be nice if the Automatic inlining had a way of providing the inlined code to make it easier, but here we are.
ITVF is a single-statement function that returns a table.
-- Transact-SQL Inline Table-Valued Function Syntax
CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ = default ] [ READONLY ] }
[ ,...n ]
]
)
RETURNS TABLE
[ WITH <function_option> [ ,...n ] ]
[ AS ]
RETURN [ ( ] select_stmt [ ) ]
[ ; ]
Since we are replacing a Scalar UDF, our table should always return one row.
Our dbo.DoNothing function rewritten as an ITVF would look like this.
CREATE OR ALTER FUNCTION dbo.DoNothingITVF(@Id int)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT @Id AS SameValue
GO
- Instead of returning a data type, we are returning
TABLE - I add a
SCHEMABINDINGautomatically because the function doesn’t access any data. - There is no
BEGINorENDbecause it’s a single-statement function - The returning column has to be aliased
But the work doesn’t stop here. Several gotchas should be mentioned.
Manual rewrite challenges
There are a few things to keep in mind before you go on a rewriting spree.
Constraints and columns
Table-valued functions cannot be used in constraints and computed columns.
It doesn’t matter that you’ll pinky swear to SQL Server that you will always return one row - it cannot be done.
ALTER TABLE dbo.ComputedColumn
ADD ItvfColumn AS (SELECT TOP (1) SameValue FROM dbo.DoNothingITVF(Id))
Subqueries are not allowed in this context. Only scalar expressions are allowed.
To remove those Scalar UDFs, you need to move the logic elsewhere. For example, Application, CRUD Procedures or Triggers.
It’s not ideal, but you have to weigh the pros and cons; there is no silver bullet answer.
Different functions, different calls
Probably the biggest issue is that you cannot make an in-place upgrade to ITVF.
If I were to try to replace the existing Scalar UDF with an ITVF:
ALTER FUNCTION dbo.DoNothing(@Id int)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT @Id AS SameValue
GO
I would get this error:
Cannot perform alter on 'dbo.DoNothing' because it is an incompatible object type.
So we need to turn this:
SELECT
n.Id
, dbo.DoNothing(n.Id) AS Nothing /* Scalar */FROM dbo.Nums AS n
Into this:
SELECT
n.Id
, dni.SameValue AS Nothing
FROM dbo.Nums AS n
CROSS APPLY dbo.DoNothingITVF(n.Id) AS dni /* Table valued */The CROSS APPLY is safe in this case because if you want to match the logic of the Scalar UDF, you must return exactly one row.
Hence, never an empty result set and never multiple rows.
To replace the invocations safely opens up a door to another challenge:
Split logic
If you start replacing the references one by one (and usually you have to), you get into a situation when some code references the old Scalar UDF, and some are referencing the new ITVF.
You need to communicate this refactoring endeavour clearly and do it promptly. Otherwise, someone could change the old UDF, and the function behaviour would be inconsistent with the ITVF.
Clear communication and code reviews help, but it’s always a risk.
Permissions
Different types of functions have different types of permissions. For example, for Scalar UDFs, you GRANT EXECUTE permissions, and for ITVFs, it’s SELECT permissions.
Hopefully, with Ownership chaining, it won’t be a problem, but keep it in mind.
Same result set
You must always test that the new ITVF completely matches the logic of the old UDF.
For the quick and dirty test, I use the set operator - EXCEPT
/* Scalar EXCEPT ITVF */SELECT
n.Id
, dbo.DoNothing(n.Id) AS Nothing
FROM dbo.Nums AS n
EXCEPT
SELECT
n.Id
, dni.SameValue AS Nothing
FROM dbo.Nums AS n
CROSS APPLY dbo.DoNothingITVF(n.Id) AS dni
/* ITVF Scalar */SELECT
n.Id
, dni.SameValue AS Nothing
FROM dbo.Nums AS n
CROSS APPLY dbo.DoNothingITVF(n.Id) AS dni
EXCEPT
SELECT
n.Id
, dbo.DoNothing(n.Id) AS Nothing
FROM dbo.Nums AS n
You have to do both directions to see a difference.
If your UDF has more parameters, the combinations will snowball.
I sometimes introduce #temp tables to save the results instead of running the Scalar UDF over large result sets twice.
I use automatic tests to cover all the code paths for even more complex functions. My tool of choice is the tSQLt framework.
Correct data type
The Data type precedence and data type inference can sometimes introduce unexpected behaviour.
Therefore, one thing I always do is CAST/CONVERT the final result set to the data type of the original UDF.
Rewriting the function
My example of converting dbo.DoNothing to dbo.DoNothingITVF was to illustrate the concept with an easy example. But, of course, your production functions usually won’t be this simple.
You will have to use several tricks like CTEs or converting an empty result set to NULL with a MAX() function, etc.
The resulting ITVF won’t be as readable, but if you are after performance, it’s worth it.
Because a more complex example would significantly increase the scope of an already large post, I have a call to action:
Provide me with a Minimal, Complete, and Verifiable Example of your Scalar UDF (reasonably complex), and I will pick one and show you how to inline it as the last article in the series.
Recap
In this article, we’ve seen how to tweak existing Scalar UDFs to minimize their impact (where possible) and main two ways how to inline them along with the challenges it brings.
But still, the best cure is prevention - don’t write any new Scalar UDFs even if you plan to use them correctly. Someone will misuse them one day.
In the following article in the series, I’ll share code snippets on how to find the problematic UDFs in your environment and how to prioritize them.
Thank you for reading.