

What is Residual Predicate?
Lets say one gets a query to fine tune. While checking the execution plan, if there is a Index seek, it is common for DBAs to think that the query performance is good and acceptable. Though in most of the scenarios, the idea of looking for index seeks is acceptable, there are quite a few scenarios where index seeks simply doesn't mean optimal performance. One such scenario is explained below. Consider the following query
SELECT *
FROM [Production].[TransactionHistory]
WHERE Productid = 801
AND TransactionID % 3 = 0
Table has a non clustered index on "ProductID" and clustered Index on "TransactionID".

Lets say one gets a query to fine tune. While checking the execution plan, if there is a Index seek, it is common for DBAs to think that the query performance is good and acceptable. Though in most of the scenarios, the idea of looking for index seeks is acceptable, there are quite a few scenarios where index seeks simply doesn't mean optimal performance. One such scenario is explained below. Consider the following query
SELECT *
FROM [Production].[TransactionHistory]
WHERE Productid = 801
AND TransactionID % 3 = 0
Table has a non clustered index on "ProductID" and clustered Index on "TransactionID".
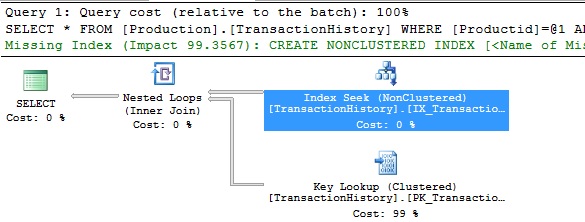
The picture above as expected indicates an Index seek.
?
Screenshot of Index Seek Operator's details provided above. The seek predicate section at the bottom indicates that "Index Seek" operator was used for "ProductID = 801" filter alone.
Observe the section marked in red. "Predicate" section shows
"[Production].[TransactionHistory].TransactionID % 3 = 0 ".
What it implies is the index seek filtered only for "ProductID = 801" filter condition. Additional filtering (outside the index) had to be done for "TransactionID % 3 = 0", after the Index seek operation. This additional filters for the rows that are extracted from "Index Seek" are termed as "Residual Predicates". If the work done by residual predicate is too high then it implies that the Index is not effective.
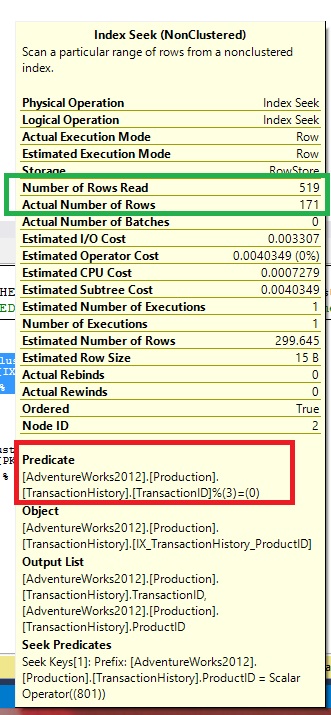
"Number of Rows Read" n "Residual Predicates"
On the last post, I wrote about "Number of Rows Read". Just to recap, "Number of Rows Read" indicates the number of read by the operator. "Actual Number of Rows" is the rows returned by the operator. Observe the section highlighted in Green in picture above.
Number of Rows Read: 519
Actual Number of Rows:171
The above numbers imply that Index seek operator's seek predicate ( "ProductID = 801" ) filtered 519 rows. The additional filter " "TransactionID % 3 = 0" filtered it further to 171 rows.
The difference in "Number of Rows Read" and "Actual Number of Rows" is due to the additional rows filtered for "Residual Predicate". "Number of Rows Read" information on execution plans has made it much easier to track the additional costs incurred due to "Residual Predicates"
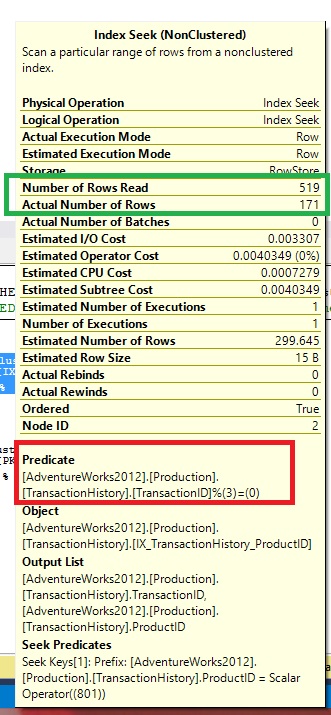
On the last post, I wrote about "Number of Rows Read". Just to recap, "Number of Rows Read" indicates the number of read by the operator. "Actual Number of Rows" is the rows returned by the operator. Observe the section highlighted in Green in picture above.
Number of Rows Read: 519
Actual Number of Rows:171
The above numbers imply that Index seek operator's seek predicate ( "ProductID = 801" ) filtered 519 rows. The additional filter " "TransactionID % 3 = 0" filtered it further to 171 rows.
The difference in "Number of Rows Read" and "Actual Number of Rows" is due to the additional rows filtered for "Residual Predicate". "Number of Rows Read" information on execution plans has made it much easier to track the additional costs incurred due to "Residual Predicates"
![]()

{kind=link}