

In this post I will talk about the in-built refactoring support in SSDT – the language is slightly different from my normal style as originally it was going to be published else but rest assured it is written by myself
What is refactoring?
In programming , the term ‘refactoring’ essentially means taking some code and improving it without adding features and without breaking the code. When we refactor code we ideally want to make small improvements over time, using an IDE that automates as many of the tasks as possible for us.
While SQL Server Data Tools (SSDT) cannot guarantee that we do not break any code it helps us make small improvements and, as an IDE, it offer us some refactoring abilities that do not exist in either SQL Server Management Studio (SSMS) or Notepad.
Just so we don’t get distracted by some of the third-party add-ins that give more comprehensive support for refactoring in SSDT or SSMS, this article will talk only about what is out-of-the-box with SSDT.
What refactoring support does SSDT have?
SSDT helps us to refactor code by automating the actions of:
- Expanding wildcards
- Fully qualifying object names
- Moving objects to a different schema
- Renaming objects
Aside from this list SSDT also, of course, helps us to refactor code manually with its general editing facilities.
Expand Wildcards
SSDT allows you to highlight a “*" from a SELECT statement and have it replace the “*" with a comma-delimited list of the column names in the table. As an example if we take these table definitions:
CREATE SCHEMA hr
GO
CREATE TABLE dbo.person
( person_id INT NOT NULL IDENTITY(1, 1) PRIMARY KEY CLUSTERED,
first_nmae VARCHAR(25) NOT NULL, --typo is on purpose!
last_name VARCHAR(25) NOT NULL
)
CREATE TABLE hr.departments
( id INT NOT NULL IDENTITY(1, 1) PRIMARY KEY CLUSTERED,
funny_name_ha_ha_I_am_so_cool_my_last_day_is_tomorrow VARCHAR(25) NOT NULL
)
CREATE TABLE hr.department
( person_id INT,
department_id INT
)
And the following stored procedures:
CREATE PROCEDURE hr.get_employee ( @employee_id INT )
AS
SELECT *
FROM person p
JOIN hr.department dep ON p.person_id = dep.person_id
JOIN hr.departments deps ON dep.department_id = deps.id;
GO
CREATE PROCEDURE prod_test
AS
EXEC hr.get_employee 1480;
GO
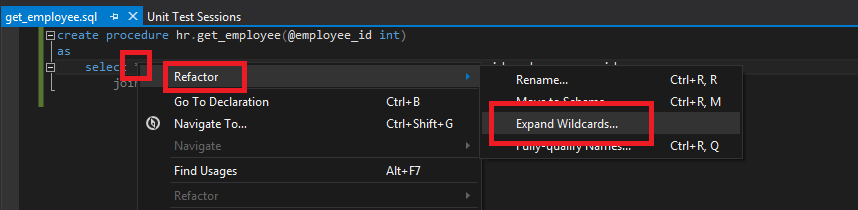
To improve this code the first thing we will do is to change the “SELECT *" in the hr.get_employee procedure to specify just those columns that we need. If we open the stored procedure in SSDT and right click the “*" we can choose ‘refactor’ and then ‘expand wildcards’:
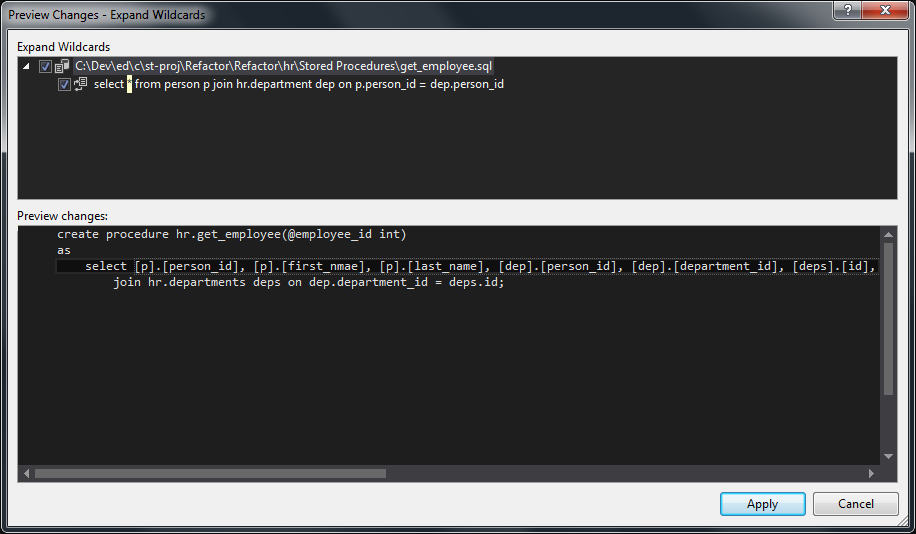
We are then given a preview of what will change, and we can either cancel or accept this:
Now that we have the actual columns, we can remove the ones we do not need, save and check-in our changes. The procedure should look like:
CREATE PROCEDURE hr.get_employee ( @employee_id INT )
AS
SELECT [p].[first_nmae], [p].[last_name], [deps].[funny_name_ha_ha_I_am_so_cool_my_last_day_is_tomorrow]
FROM person p
JOIN hr.department dep ON p.person_id = dep.person_id
JOIN hr.departments deps ON dep.department_id = deps.id;
GO
Fully qualify object names
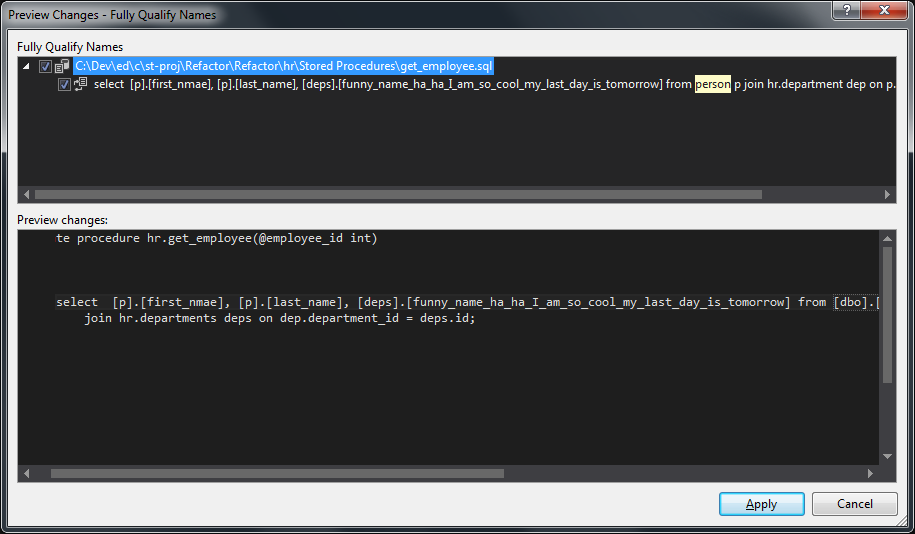
We need to make sure that our SQL Code uses fully qualified object names. This is because …. In this example, the get_employee stored procedure references the person table without a schema which means that the user must have dbo as their default schema. To fix this we right click anywhere in the stored procedure and choose Refactor and then ‘Fully-qualify names’, we could also use the default shortcut of ctrl+r and then q. Again get a preview window:
If we accept the preview, then we end up with the following code:
CREATE PROCEDURE hr.get_employee ( @employee_id INT )
AS
SELECT select [p].[first_nmae], [p].[last_name], [deps].[funny_name_ha_ha_I_am_so_cool_my_last_day_is_tomorrow]
FROM [dbo].person p
JOIN hr.department dep ON p.person_id = dep.person_id
JOIN hr.departments deps ON dep.department_id = deps.id;
GO
This doesn’t seem like a massive deal as we could just have written ‘dbo.’ but if we had a more than one to update or a number of different tables then it would have saved more work for us.
The ‘fully qualify object names’ goes further than just table names, it will fill in tables in join statements and also columns where it is needed.
For example if I had the following query:
SELECT first_nmae
FROM [dbo].[person] p
JOIN hr.department d ON department_id = p.person_id
When using the refactoring we are offered the chance to fully qualify first_nmae and the department_id in the join:
If we decided we did not want to apply the refactoring to one or the other we could uncheck them in the dialog and only apply the ones that we actually required.
If we apply both of the ‘refactorings’, we end up with:
SELECT [p].first_nmae
FROM [dbo].[person] p
JOIN hr.department d ON [d].department_id = p.person_id
Move objects to a different schema
We can refactor the schema that an object belongs to. This is a three-stage process that:
- 1.Changes the schema that the object belongs to
- 2.Changes all references to the original object to specify the new schema
- 3.Adds an entry to the refactorlog.refactorlog to help the deployment process
If we want to move the person table from the dbo schema into the hr schema, we can simply right-click the table and then choose ‘refactor’ and then ‘move schema’:
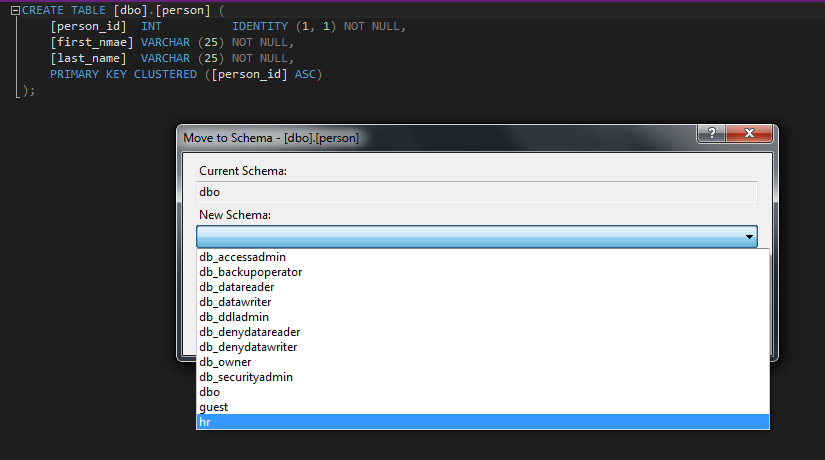
If we look at the preview we can see that, as well as changing the schema on the object itself, it is also going to change the references to the table everywhere else in the database:
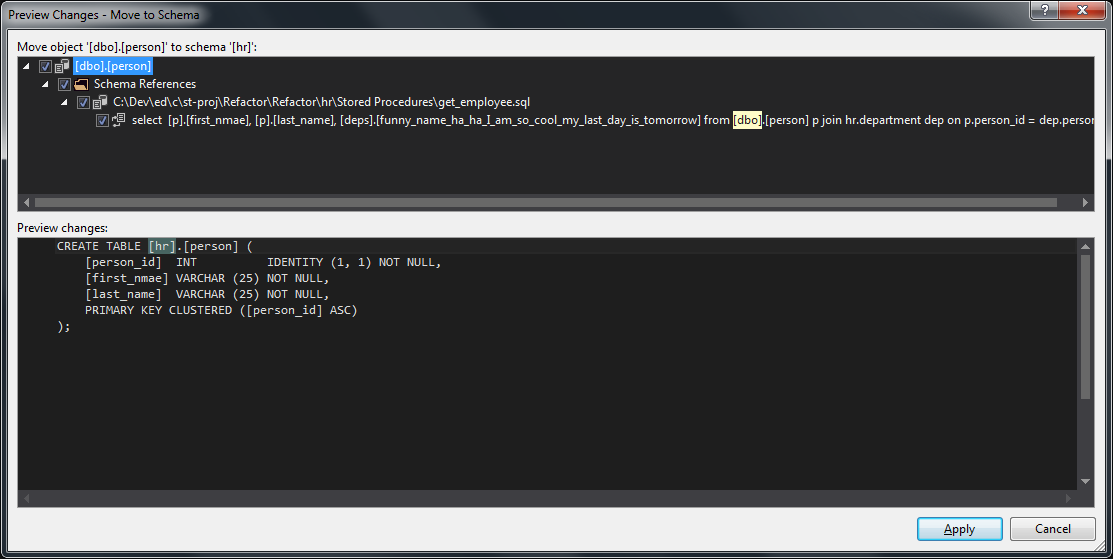
This refactoring also adds a new file to our SSDT project, the Refactor.refactorlog file in order to assist in a correct deployment of the change that preserves the data in the table. Inside the refactorlog is some xml:
<?xml version="1.0" encoding="utf-8"?>
<Operations Version="1.0" xmlns="http://schemas.microsoft.com/sqlserver/dac/Serialization/2012/02">
<Operation Name="Move Schema" Key="5df06a6f-936a-4111-a488-efa0c7f66576" ChangeDateTime="11/10/2015 07:10:39">
<Property Name="ElementName" Value="[dbo].[person]" />
<Property Name="ElementType" Value="SqlTable" />
<Property Name="NewSchema" Value="hr" />
<Property Name="IsNewSchemaExternal" Value="False" />
</Operation>
</Operations>
</code>
What this does is to save the fact that an object has changed from one schema to another. SSDT reads the refactorlog when generating a deployment script. Without the refactorlog, SSDT would look at the source dacpac and the target database and drop the table ‘dbo.person’, deleting all its’ data, and create a new empty ‘hr.person’ as they are different objects. Because of the refactorlog, SSDT generates a schema transfer rather than a drop / create:

SSDT stops the change happening again by recording, in the target database, that the refactor key has been run so you could create a new table called hr.people and it would not get transferred as well:

Renaming Objects
The final type of built-in refactoring is to rename objects, this works similar to the move schema object but it allows us to rename any object such as a procedure, table, view or column. SSDT renames all the references for us:
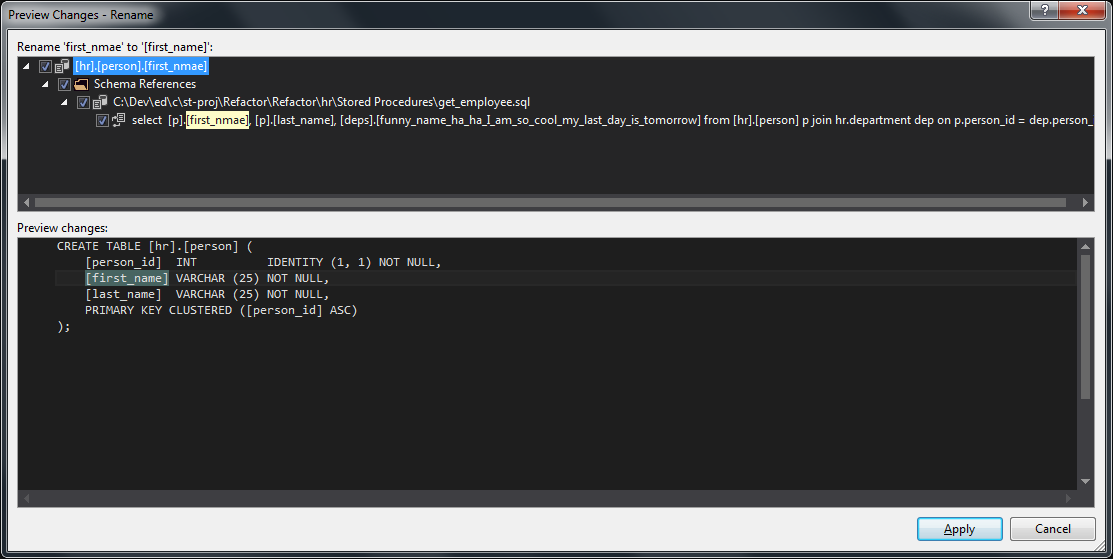
SSDT also adds an entry into the refactorlog:

And finally generates a “sp_rename" as part of the deployment rather than a drop/create:

Renaming objects really becomes pretty simple and safe so you can go though and correct small mistakes like spelling mistakes or consistency mistakes. Without SSDT or another IDE to do it for you it is really difficult to rename objects as part of a quick refactoring session.
Other ways SSDT helps to refactor
Aside from the in-built refactors that SSDT has it helps us to refactor because it allows us to find where we have references to an object. For example if you wanted to add a column to a table but did not know whether there were stored procedures that did a select * from the table and then did something that would be broken by adding a new table you could right click on the table name and do “Find All References":

We can also do the same thing for column names and so we can really easily get a picture of how and where objects are used before we change them.
General advice on refactoring SQL Server databases
Refactoring SQL Server databases is really helped by using SSDT but there are two things that you can do which really give you the freedom to refactor your code as you go along:
- Use stored procedures / views rather than access tables directly
- Have a suite of unit/integration tests
- Use stored procedures / views rather than access tables directly
If you access your data from your application using the base tables it means you cannot change anything in your tables without also changing the application. It also makes it really hard to find references to your objects to know where they are used. Instead you should use stored procedures as an API to expose your data. If you do this then instead of having to manually find references you simply need to find the places where the stored procedure is called.
Have a suite of unit/integration tests
If you have both unit and integration tests then, as well has having a tool that helps you to refactor your code, you also get the confidence of knowing that you can make changes without breaking anything else. Without these test suites it is hard to known whether you have broken that year-end critical task that is so easily forgotten about.
Conclusion
SQL Server Data Tools have the basics of refactoring tools, but it isn’t really what one comes to expect from a SQL IDE. What about a tool to automatically insert a semi-colon after every statement, if there is none? Why is there nothing that changes the case of keywords according to SQL Conventions? One looks in vain for a way of reformatting code correctly. One could be more ambitious and ask for ways of finding variables that aren’t used, splitting tables, encapsulating code within a stored procedure, or checking for invalid objects. Fortunately, there a number of add-ins that fill the gap, and in the next article we take a look at SQL Prompt, which is the leading
![]()
