


In last week's post, we went over how one of best ways to improve query performance was to reduce the number of reads that your query has to do.
Less reads typically means faster query performance - so how can you reduce the number of reads SQL Server is required to make?
Watch this week's video on YouTube
Write more selective queries
Writing more selective queries can be done in a few different ways.
For starters, if you don't need every column of data, don't use SELECT *. Depending on the size of your rows, providing only the columns you need might allow SQL Server to use an index that is narrower and/or denser. An index that is narrow (fewer columns) or dense (more records per page) allows SQL Server to return the same amount of data you need in fewer pages.
The same thing goes for being more selective in your ON and WHERE clauses. If you specify no WHERE conditions, SQL Server will return every single page in your table. If you can filter down the data to exactly what you need, SQL Server can return only the data you need. This reduces logical reads and improves speed.
-- Read 1,000,000 pages
SELECT * FROM Products
-- Read 10,000 pages by being more selective in your SELECT and WHERE
SELECT ProductName FROM Products WHERE CreateDate > '2015-01-01'
Finally, do you have large object (LOB) data (eg. varchar(max), image, etc..) on the tables in your query? Do you actually need it in your final result set? No? Then don't include it as part of your reads! This could mean creating an index on the columns you do need or putting your LOB data in a separate table and only joining to it when you need it.
-- Read 1,000,000 pages because your Products table has a LOB field and nothing besides a clustered index
SELECT ProductName FROM Products WHERE CreateDate > '2017-08-01'
-- Read in 1000 pages only because you put your lob column on a separate table.
-- Or you created an index that contains ProductName and not your LOB column.
-- Same query, better performance!
SELECT ProductName FROM Products WHERE CreateDate > '2017-08-01'
-- Need that LOB data? Just join in the separate table. Reads are large here, but at least you only are reading when you truly need that LOB data.
SELECT
p.ProductName,
pe.ProductExtendedProperties -- this is nvarchar(max)
FROM
Products p
INNER JOIN ProductLOBs pe
ON p.ProductId = pe.ProductId
Fix suboptimal execution plans
It's possible that your query is already as selective as it can be. Maybe you are getting too many reads because SQL Server is generating and using a suboptimal execution plan.
A big tip off that this might be happening is if your cardinality estimates are out of whack a.k.a. the estimated vs. actual row counts have a large difference between them:
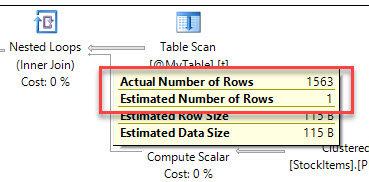
If SQL Server thinks it only is going to read 1 row of data, but instead needs to read way more rows of data, it might choose a poor execution plan which results in more reads.
You might get a suboptimal execution plan like above for a variety of reasons, but here are the most common ones I see:
- Parameter sniffing
- Use of table variables (via Brent Ozar)
- Outdated statistics (via Kimberly L. Tripp)
If you had a query that previously ran fine but doesn't anymore, you might be able to utilize Query Store to help identify why SQL Server started generating suboptimal plans.
The key is to get a good execution plan so that you aren't performing unnecessary reads.
But what if you aren't encountering any of the problems above and performance is still slow due to high numbers of reads? Simply...
Add an index
 A cup of coffee and a shot of espresso might have the same caffeine content - espresso is just more caffeine dense, just like the data stored in a narrow index. Photo by Mike Marquez on Unsplash
A cup of coffee and a shot of espresso might have the same caffeine content - espresso is just more caffeine dense, just like the data stored in a narrow index. Photo by Mike Marquez on Unsplash
If you have an existing table that has many columns and you only need a subset of them for your query, then consider adding an index for those columns.
Indexes are copies of your data stored in a different order with generally fewer columns. If SQL Server is able to get all of the information it needs from a narrow index, it will do that instead of reading the full table/clustered index.
A copy of the data that has fewer columns will have greater page density (or the amount of data that fits on each page). If SQL Server can get all of the data it needs by reading fewer, denser pages then your query will run faster.
Don't just go adding indexes willy nilly though. You may already have an index that almost contains all of the columns your query needs. Look at a table's existing indexes first and see if any of them are close to what you need. Usually, you'll be better off adding an included column or two to an existing index instead creating a whole brand new index. And you'll save on disk space by not creating duplicate indexes either.
Reduce index fragmentation
So indexes are great for reducing reads because they allow us to store only the data that is needed for a specific query (both as key columns and included columns). Fewer columns = greater density = fewer reads necessary.
However, indexes can become fragmented. There's internal fragmentation, which causes less data to be stored on a page than what is possible, and external fragmentation which causes the pages to be stored out of logical order on the disk.
Internal fragmentation is problematic because it reduces page density, causing SQL Server to have to read more pages in order to get all of the data it needs.
External fragmentation is problematic, especially for spinning disk hard drives, because SQL Server needs to read from all over the disk to get the data it needs.
In general, reorganizing or rebuilding an index are the typical ways you want to fix a fragmented index.
To slow down future fragmentation, you can test out different fill factors to try and prevent page splits from fragmenting your indexes.