

Views help our query writing by simplifying writing the same sentences and/or aggregations over and over again, but it has a drawback, the views just store our query definition, but the performance is not improved by using them.
Since SQL Server 2008, the option to create an index over a view was introduced, of course, there are some limitations, but if your view can use them, the performance improvement could be great!
I will show you how to create a simple index over a view
Base query
I have created a test table called Aggregate_tbl1 with over 12,000,000 rows of random "money" data and random texts as well, as you can see in the following images:
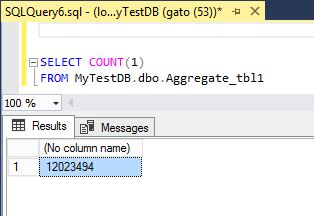
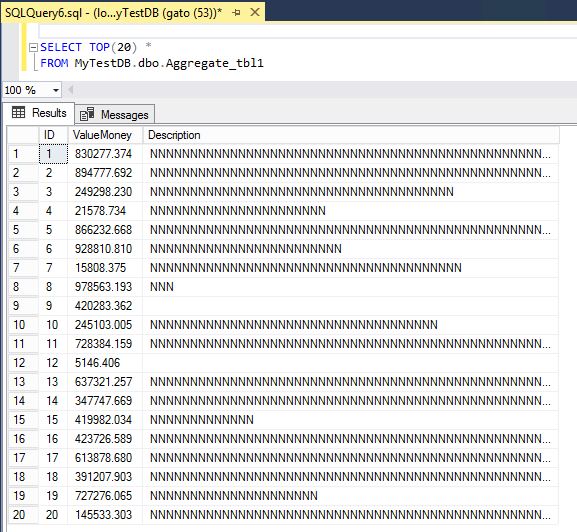
with this table, let us proceed to make a simple aggregation query and create it inside a view:
CREATE VIEW [dbo].[Aggregate_tbl1_VI]
AS
SELECT
SUM(ValueMoney) AS total,
[Description] AS descr
FROM dbo.Aggregate_tbl1
GROUP BY [Description]
GO
If we execute this view with a single where and check the execution plan we will see something like this (no indexes):
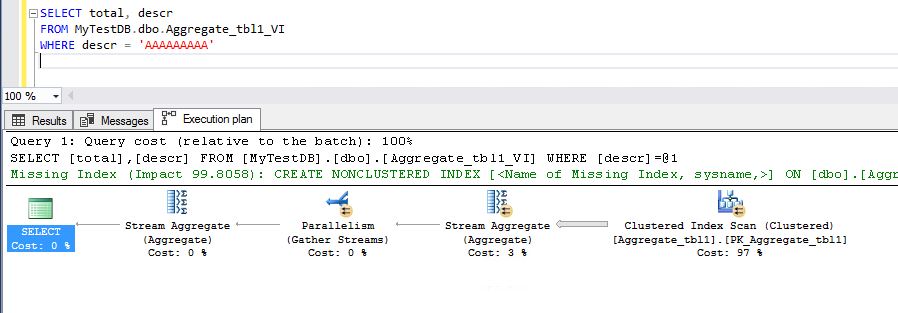
we can see that an index scan and some computes are performed, so what happens if we just add a simple index in the base table over description and include the valueMoney field?
If we execute the query again, we can see some improvement, and index seek is performed now, but still, there is an aggregation operation costing 7% of the total operation and please take a look on how many rows are read (22397) to compute the total

Creating the view and the related index
We proceed to create an index over the view we created previously, of course, we have to drop it first, and then recreate it with the SCHEMABINDING option, and since we are using a GROUP BY, we also must include the COUNT_BIG(*) sentence:
DROP VIEW [dbo].[Aggregate_tbl1_VI]
GO
CREATE VIEW [dbo].[Aggregate_tbl1_VI]
WITH SCHEMABINDING
AS
SELECT
COUNT_BIG(*) as [count_rows],
SUM(ValueMoney) AS total,
[Description] AS descr
FROM dbo.Aggregate_tbl1
GROUP BY [Description]
GO
Now we proceed to create an index over the view (as any other index)
Just note that the index must be a unique clustered one, that is because a group by is used in our example, to guarantee the uniqueness of the rows of the view:
CREATE UNIQUE CLUSTERED INDEX IX_IV_Aggregate_tbl1_VI_DESCR
ON [dbo].[Aggregate_tbl1_VI] (descr)
GO
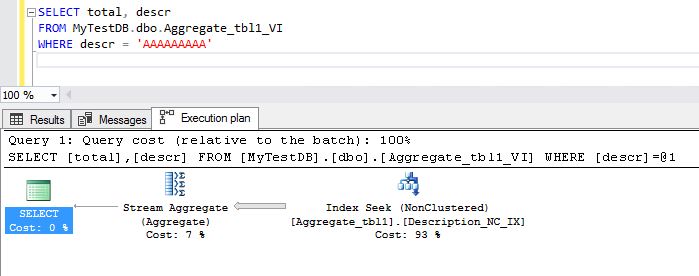
Now, let us proceed to execute the query again and see how it behaves:
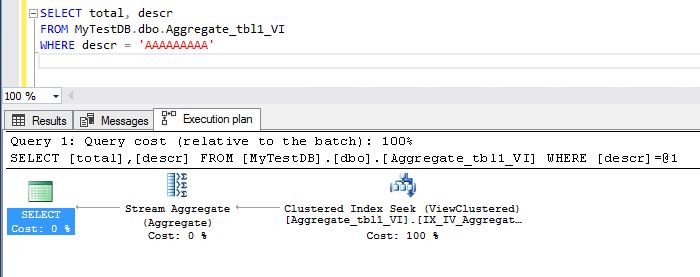
We can see that now the newly created index is executed, and the aggregation operation lowered its cost, and from reading 22397 rows it decreased to 1 row, as we can see in the details:

With this simple example, we could see that we had a big improvement on the performance of the query, but as I always tell you, test any change on a dev server first!
If you need more information about the special requirements to create an index over a view, please visit the Microsoft official documentation here
