

Microsoft usually has some interesting announcements at the PASS Summit, and this year was no exception. I’m writing a set of blogs covering the major announcements. Next up is the PolyBase enhancements.
PolyBase is a technology that accesses and combines both non-relational and relational data, all from within SQL Server. It allows you to run queries on external data in Hadoop or Azure blob storage. The queries are optimized to push computation to Hadoop via MapReduce jobs.
By simply using Transact-SQL (T-SQL) statements, you an import and export data back and forth between relational tables in SQL Server and non-relational data stored in Hadoop or Azure Blob Storage. You can also query the external data from within a T-SQL query and join it with relational data.
The major use cases for PolyBase are:
- Load data: Use Hadoop as an ETL tool to cleanse data before loading to data warehouse with PolyBase
- Interactively Query: Analyze relational data with semi-structured data using split-based query processing
- Age-out Data: Age-out data to HDFS and use it as ‘cold’ but query-able storage
The main benefits of PolyBase are:
- New business insights across your data lake
- Leverage existing skillsets and BI tools
- Faster time to insights and simplified ETL process
PolyBase supports the following file formats: Delimited text (UTF-8), Hive RCFile, Hive ORC, Parquet, gzip, zlib, Snappy compressed files.
For more details see: Introduction to PolyBase presentation, PolyBase Guide, and the list of supported data sources here.
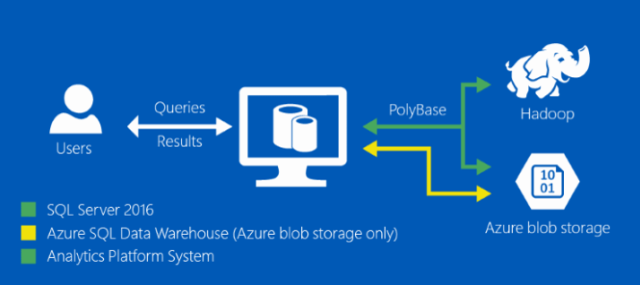
Polybase was first made available in Analytics Platform System in March 2013, and then in SQL Server 2016. The announcement at the PASS Summit was that by preview early next year, in addition to Hadoop and Azure blob storage, PolyBase will support Teradata, Oracle, SQL Server, and MongoDB in SQL Server 2016. And the Azure Data Lake Store will be supported in Azure SQL Data Warehouse PolyBase.
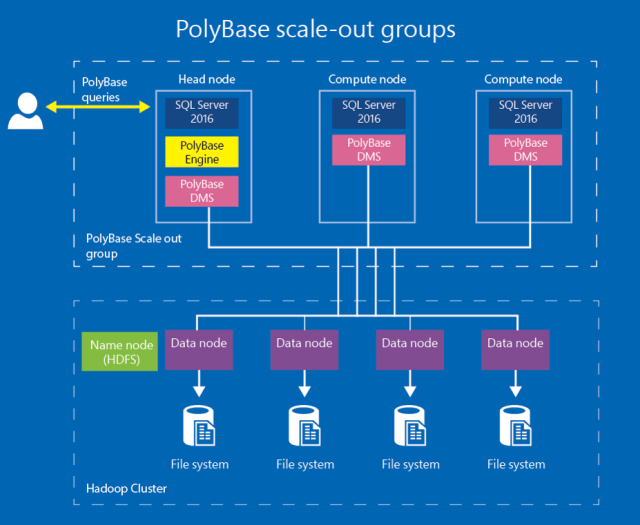
With SQL Server 2016, you can create a cluster of SQL Server instances to process large data sets from external data sources in a scale-out fashion for better query performance (see PolyBase scale-out groups):
In summary, the main reasons to use PolyBase:
- Ability to integrate SQL Server with data stored in HDFS or Windows Azure Storage BLOB
- Commodity hardware and storage are cheap, easily distributed on HDFS; increases data reliability at a low cost
- Increasing number of different types of data; structured, unstructured, semi-structured (Can have them stored on the best system suitable and queried in one place)
- Increasing size of data and strong aversion to data deletion due to company culture or restrictions
More info:
Integrating Big Data and SQL Server 2016
PolyBase in SQL Server 2016 video
Polybase in SQL Server – Big Data Queried with T-SQL video

![]()
