

Recently I was asked how to parse text out of an HTML fragment stored in SQL Server.
Over the next few seconds my brain processed the following ideas:
- SQL Server is not meant for parsing HTML. Parse the data with something else.
- T-SQL does have functions like REPLACE, CHARINDEX, and SUBSTRING though, perfect for searching for tags and returning just the values between them.
- CLRs could do it, probably using some kind of HTML shredding library. You also might be able to use XMLReader to do something with it…
- Wait a minute, SQL Server has XML parsing functions built in!
Maybe you see where this is going.
WARNING – this is a terrible idea
Parsing HTML with T-SQL is not a great idea. It’s dirty, it’s prone to breaking, and it will make your server’s CPUs cry that they aren’t being used for some nobler cause. If you can parse your HTML somewhere outside of SQL Server, then DO IT THERE.
With that said, if you absolutely need to parse HTML on SQL Server, the best solution is probably to write a CLR.
However, if you are stuck in a bind and plain old T-SQL is the only option available to you, then you might be able to use SQL Server’s XML datatype and functions to get this done. I’ve been there before and can sympathize.
So anyway, here goes nothing:
Using XML to parse HTML
Let’s say we have the following fragment of HTML (copied from a bootstrap example template):
DECLARE @html xml = '
<div class="container">
<div class="card-deck mb-3 text-center">
<div class="card-body">
<h1 class="card-title pricing-card-title">$15 <small class="text-muted">/ mo</small></h1>
<ul class="list-unstyled mt-3 mb-4">
<li>20 users included</li>
<li>10 GB of storage</li>
<li>Priority email support</li>
<li>Help center access</li>
</ul>
<button type="button" class="btn btn-lg btn-block btn-primary">Get started</button>
</div>
</div>
</div>
'; If we wanted to say extract all of the text from this HTML (to allow text mining without all of the tags getting in the way) we could easily do this using the XML nodes() and value() methods:
-- Get all text values from elements
SELECT
T.C.value('.','varchar(max)') AS AllText
FROM
@html.nodes('/') T(C);
If we want to only extract the items from the list elements, we can write some XQuery to select only those elements:
-- Get a fragment of HTML
SELECT
T.C.value('.','varchar(100)') AS ListValues
FROM
@html.nodes('//*[local-name()=("li")]') T(C); 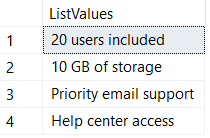
Finally, we can also do things like select HTML fragments based on an attribute to parse further in subsequent steps. If I want to select the div with a class of “card-body”, I can write:
-- Get the text from within certain elements
SELECT
T.C.query('.') AS CardBody
FROM
@html.nodes('//div[@class="card-body"]') T(C); 
Yuck
To reiterate – you don’t want to do any of the above unless you have no other choice.
The XML parsing functions will not parse all HTML, so you may need to do some pre-processing on your HTML data first (removing invalid HTML, closing tags, etc…).
It works beautifully in the above example but your results may very. Good luck!
