

Indexes are a vast subject and well documented elsewhere on the web. But, it is still a very commonly asked topic. In order to improve your queries (applications) and databases performance, we create indexes.
But those created indexes may not be very useful over the period because of your application requirement changes, the queries against the data change, the structure of the database and tables changes, the data in the table change. Sooner or later you will find that Indexes that once helped performance now they are not so effective because of change in applications and databases.
Ultimately, SQL Server will start recommending you to create more indexes (missing indexes) to get the blazing performance of the queries.
There could be other scenarios like – your company is expanding the business/sites, they want to launch a couple of new applications, and those applications need more indexes on the table. Again you may end up with having more indexes.
Considering above the scenarios – if you don’t understand how to leverage the existing indexes by aligning them, you may end-up with over-indexing on the tables and an OLTP data tier.
How can over-indexing hurt your SQL server performance?
The reason that having too many indexes is a bad thing because it dramatically increases the amount of writing that needs to be done to the table.
Demonstrate the impact
- I am going to use AdventureworksDW2016CTP3 database table [Production].[TransactionHistory]. It already has three indexes on it.

- Now, I am going to create five more indexes on the table such IX_Redundant 1, IX_Redundant 2, IX_Redundant 3, IX_Redundant 4, and IX_Redundant 5.
USE [AdventureworksDW2016CTP3] GO CREATE NONCLUSTERED INDEX [IX_Redundant1] ON [Sales].[SalesOrderDetail] ( [CarrierTrackingNumber] ASC, [OrderQty] ASC, [rowguid] ASC ) CREATE NONCLUSTERED INDEX [IX_Redundant2] ON [Sales].[SalesOrderDetail] ( [CarrierTrackingNumber] ASC, [OrderQty] ASC ) CREATE NONCLUSTERED INDEX [IX_Redundant3] ON [Sales].[SalesOrderDetail] ( [rowguid] ASC ) CREATE NONCLUSTERED INDEX [IX_Redundant4] ON [Sales].[SalesOrderDetail] ( [UnitPriceDiscount] ASC, [LineTotal] ASC ) CREATE NONCLUSTERED INDEX [IX_Redundant5] ON [Sales].[SalesOrderDetail] ( [ProductID] ASC )
Verify the created indexes
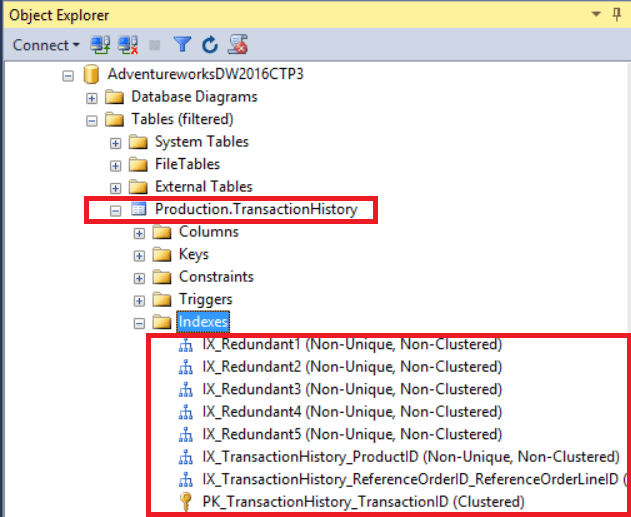
- Let’s execute sp_helpindex against the table [Production].[TransactionHistory] and see which all the indexes are associated with the table.
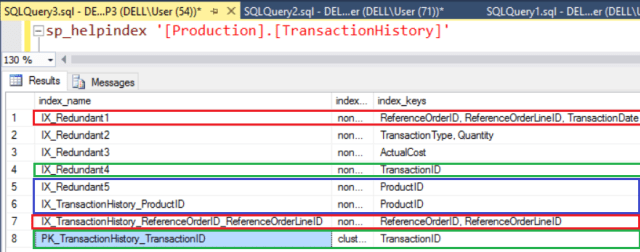
Now, we have eight different indexes and notice that there is overlap;
We have two-two indexes on “TranscationID” column and “ProductID” column. They are absolute duplicates indexes. When you have absolute duplicates, I would recommend you to drop one of the duplicate indexes.
Now look at indexes “IX_Redundant1” & “IX_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID”, they have trail in columns. I would again recommend you to remove the index “IX_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID” so that query optimizer can use the second index “IX_Redundant1”.
Note: you might have several different indexes that might be beneficial to your select queries or other workloads, but they might also be slowing down your data modification (DML) operation.
Warning: Before you delete any index in production, kindly make sure that the index is a waste.
- Let’s do an insert operation against the table [Production].[TransactionHistory]. I’m going to enable “SET STATISTICS IO ON” and “NO COUNT ON” and going to insert TOP 50 rows into the table from the table [Production].[TransactionHistory]
USE [AdventureworksDW2016CTP3]
GO
SET NOCOUNT ON
SET STATISTICS IO ON
INSERT INTO [Production].[TransactionHistory]
([ProductID]
,[ReferenceOrderID]
,[ReferenceOrderLineID]
,[TransactionDate]
,[TransactionType]
,[Quantity]
,[ActualCost]
,[ModifiedDate])
SELECT TOP 50
[ProductID]
,[ReferenceOrderID]
,[ReferenceOrderLineID]
,[TransactionDate]
,[TransactionType]
,[Quantity]
,[ActualCost]
,[ModifiedDate]
FROM [Production].[TransactionHistory]
SET STATISTICS IO OFF- Once the insert operation completed successfully, the statistics details will show you that SQL Server did 1623 logical reads on the table [Production].[TransactionHistory]

- Now, let’s remove the redundant indexes which we created.
USE [AdventureworksDW2016CTP3] GO DROP INDEX [IX_Redundant1] ON [Production].[TransactionHistory] GO DROP INDEX [IX_Redundant2] ON [Production].[TransactionHistory] GO DROP INDEX [IX_Redundant3] ON [Production].[TransactionHistory] GO DROP INDEX [IX_Redundant4] ON [Production].[TransactionHistory] GO DROP INDEX [IX_Redundant5] ON [Production].[TransactionHistory] GO
- Let’s insert TOP 50 rows again into the table [Production].[TransactionHistory].
USE [AdventureworksDW2016CTP3]
GO
SET NOCOUNT ON
SET STATISTICS IO ON
INSERT INTO [Production].[TransactionHistory]
([ProductID]
,[ReferenceOrderID]
,[ReferenceOrderLineID]
,[TransactionDate]
,[TransactionType]
,[Quantity]
,[ActualCost]
,[ModifiedDate])
SELECT TOP 50
[ProductID]
,[ReferenceOrderID]
,[ReferenceOrderLineID]
,[TransactionDate]
,[TransactionType]
,[Quantity]
,[ActualCost]
,[ModifiedDate]
FROM [Production].[TransactionHistory]
SET STATISTICS IO OFF- After completion of the insert operation, let’s verify the statistics details. Now, SQL Server did ONLY 389 logical reads on the table [Production].[TransactionHistory]

Conclusion:
From the above testing, we can see that the logical reads dramatically went down from 1623 to 389. Basically, we have improved the insert operation on the table 417%. So, when you are dealing with OLTP designs, it becomes imperative to make sure that you are not ending-up with over-indexing.
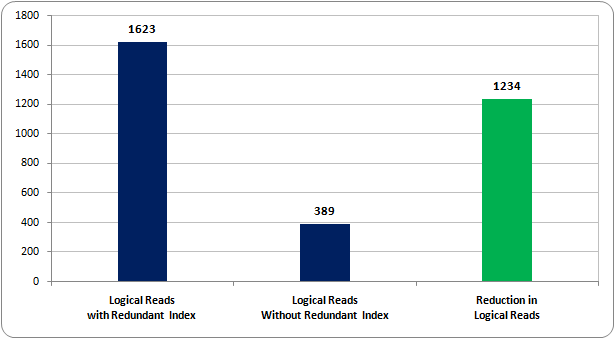
Just think you are dealing with an OLTP system where an application is doing 10,000 inserts every five minutes, and you find duplicate/unused/over indexes……
Hope, you enjoy learning over-indexing concept! Do share your input by commenting, if you have experienced this in your environment.
The post Over-Indexing can hurt your SQL Server performance appeared first on .
