

Quite often people will use, or will recommend using, a binary Collation (one ending in “_BIN” or “_BIN2“) when wanting to do a case-sensitive operation. While in many cases it appears to behave as expected, it is best to not use a binary Collation for this purpose. The problem with using binary Collations to achieve case-sensitivity is that they have no concept of linguistic rules and cannot equate different versions of characters that should be considered equal. And the reason why using a binary Collation often appears to work correctly is simply the result of working with a set of characters that has no accents or other versions. One such character set (a common one, hence the confusion), is US English (i.e. “A” – “Z” and “a” – “z”; values 65 – 90 and 97 – 122, respectively). However, there are a few areas where binary collations don’t behave as many (most, perhaps?) people expect them to.
Combining Characters
Combining characters are marks added to base characters for various reasons, such as adding accent marks. For more information on these, and to see groups of them, please see:
- Combining Diacritical Marks 0300—036F
- Combining Diacritical Marks Supplement 1DC0—1DFF
- Combining Diacritical Marks for Symbols 20D0—20FF
Unicode includes both the ability to create accented characters as well as the original accented characters from the various 8-bit code pages where the character is a pre-combined base letter with the accent mark. The query below shows that Unicode Code Point U+00DC (decimal value = 220) is the pre-combined character, whereas Code Point U+0308 is merely the two dots that go above some letters (a.k.a. diaeresis) that combines with a regular, non-accented “U” to form the same accented character represented by Code Point U+00DC.
SELECT NCHAR(252) AS [NCHAR(252)], -- 0x00FC -- ü
NCHAR(220) AS [NCHAR(220)], -- 0x00DC -- Ü
NCHAR(0x0308) AS [NCHAR(0x0308)], -- ¨ (combining diaeresis)
N'U' + NCHAR(0x0308) AS ; -- U¨

Outside of the slight font difference in the above output, the two capital Ü’s really are the same character. Users do not care if that accented U is a single Code Point or two Code Points or 32 Code Points (if that were even possible). If a user is searching for text and enters in Code Point U+00DC, then if a string containing “U” and then Code Point U+0308 isn’t returned, that would appear to be a bug. If the filter is supposed to be case-insensitive, then the user submitting a pre-combined lower-case “u” with the accent needs to also return that same “U” followed by Code Point U+0308, as the following example shows:
SELECT NCHAR(0x00FC) + N' vs. U' + NCHAR(0x0308) AS ,
CASE
WHEN NCHAR(0x00FC) = N'U' + NCHAR(0x0308)
COLLATE Latin1_General_100_CI_AS THEN 'Same!'
ELSE 'Different'
END AS [Case-INsensitive];

But, if the filter is case-sensitive, then that pre-combined lower-case “u” with the accent shouldn’t match a “U” followed by Code Point U+0308, as the following example shows:
SELECT NCHAR(0x00FC) + N' vs. U' + NCHAR(0x0308) AS ,
CASE
WHEN NCHAR(0x00FC) = N'U' + NCHAR(0x0308)
COLLATE Latin1_General_100_CS_AS THEN 'Same!'
ELSE 'Different'
END AS [Case-Sensitive];

Of course, if the filter is case-sensitive then the user submitting the pre-combined upper-case “U” with the accent needs to match a “U” followed by Code Point U+0308, as the following example shows:
SELECT NCHAR(0x00DC) + N' vs. U' + NCHAR(0x0308) AS ,
CASE
WHEN NCHAR(0x00DC) = N'U' + NCHAR(0x0308)
COLLATE Latin1_General_100_CS_AS THEN 'Same!'
ELSE 'Different'
END AS [Case-Sensitive];

And that brings us to one of the problems with binary Collations: they naturally only look at each individual byte (or Code Point) and have no concept that some combinations Code Points really should equate to one or more other Code Points. The following example shows that was has been considered the same is now seen as different:
SELECT NCHAR(0x00DC) + N' vs. U' + NCHAR(0x0308) AS ,
CASE
WHEN NCHAR(0x00DC) = N'U' + NCHAR(0x0308)
COLLATE Latin1_General_100_BIN2 THEN 'Same!'
ELSE 'Different'
END AS [Binary];
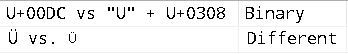
Fullwidth Characters
In Unicode and at least some (maybe all) double-byte character sets, the US English alphabet (26 letters, both upper- and lower- case) is duplicated, along with 0 – 9 and some punctuation, so that each one can take up twice as much space (side-to-side; height is still the same) and thereby align better with certain East Asian characters. For example:
SELECT tab.[col], LEN(tab.[col]) AS [Length]
FROM (VALUES (N'=oo=') /* 2 standard "o"s */,
(N'=o=') /* 1 full width "o" */) tab(col);
returns:
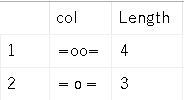
As you can see, the fullwidth “o” takes up twice as much horizontal space as the regular / normal / standard “o”. You can read more about them and see the entire Unicode block here: Halfwidth and Fullwidth Forms.
One note before proceeding: not all fonts have the fullwidth characters, and some that do have these characters do not have the combining characters. The following list of fonts are the ones that I found to have both.
- MS Gothic
- Unifont
- Yu Gothic
- Yu Gothic UI
- Yu Mincho
The Unifont font had to be downloaded and installed, but the others, I assume, came with Windows 10. For the fullwidth characters, I am using the “Yu Gothic” font. The font used for all other examples on this page used the “Noto Sans” font, but it didn’t contain the fullwidth characters so I needed something else. Unifont, while a very cool project to represent all assigned Code Points in the Unicode Basic Multilingual Plane (BMP), has a rather poor implementation of the fullwidth characters.
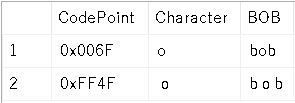
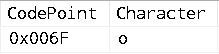
The following query shows that a lower-case regular “o” also matches the fullwidth lower-case “o”, but not the upper-case regular or fullwidth “O”s as it is a case-sensitive Collation:
SELECT tab.[CodePoint], NCHAR(tab.[CodePoint]) AS [Character],
N'b' + NCHAR(tab.[CodePoint]) + N'b' AS [BOB]
FROM (VALUES (0x004F) /* O */, (0xFF2F) /* O */, (0x006F) /* o */,
(0xFF4F) /* o */) tab(CodePoint)
WHERE NCHAR(tab.[CodePoint]) = NCHAR(0x006F) COLLATE Latin1_General_100_CS_AS;
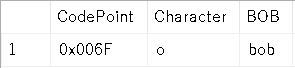
The following query shows that a lower-case regular “o” only matches itself, and not the fullwidth lower-case “o”, when using a binary Collation, since they are two different Code Points (even if that difference is only for display purposes):
SELECT tab.[CodePoint], NCHAR(tab.[CodePoint]) AS [Character],
N'b' + NCHAR(tab.[CodePoint]) + N'b' AS [BOB]
FROM (VALUES (0x004F) /* O */, (0xFF2F) /* O */, (0x006F) /* o */,
(0xFF4F) /* o */) tab(CodePoint)
WHERE NCHAR(tab.[CodePoint]) = NCHAR(0x006F) COLLATE Latin1_General_100_BIN2;
Of course, there are times when one needs to distinguish between regular and fullwidth characters. In such situations, you should first consider using the width-sensitive version of your Collation (i.e. it will have _WS in its name). Given that we are already using Latin1_General_100_CS_AS, we can just change that to be Latin1_General_100_CS_AS_WS and it will, for the simple examples above, return the same single row that the binary Collation does. However, unlike the binary Collation, it can still work correctly with combining characters, and it will work in the case-insensitive versions of that collation (e.g. “o” matches “o” and “O” but not the fullwidth versions of them).
Accent Insensitivity
In SQL Server it is possible to use a case-sensitive yet accent-insensitive Collation. The following query shows that when using such a Collation, several characters match a lower-case “o” yet the upper-case versions of them do not:
SELECT tab.[CodePoint], NCHAR(tab.[CodePoint]) AS [Character]
FROM (VALUES (0x006F) /* o */, (0x00F4) /* ô */, (0x00F8) /* ø */,
(0x014F) /* o */, (0x01A3) /* ? */, (0x022D) /* ? */,
(0x0277) /* ? */, (0x1E53) /* ? */, (0x24AA) /* ? */,
(0x24DE) /* ? */, (0x00D4) /* Ô */) tab(CodePoint)
WHERE NCHAR(tab.[CodePoint]) = NCHAR(0x006F) COLLATE Latin1_General_100_CS_AI;

The following query shows that the binary Collation does not allow for such matches:
SELECT tab.[CodePoint], NCHAR(tab.[CodePoint]) AS [Character]
FROM (VALUES (0x006F) /* o */, (0x00F4) /* ô */, (0x00F8) /* ø */,
(0x014F) /* o */, (0x01A3) /* ? */, (0x022D) /* ? */,
(0x0277) /* ? */, (0x1E53) /* ? */, (0x24AA) /* ? */,
(0x24DE) /* ? */, (0x00D4) /* Ô */) tab(CodePoint)
WHERE NCHAR(tab.[CodePoint]) = NCHAR(0x006F) COLLATE Latin1_General_100_BIN2;
Sorting
Binary collations are typically used for comparisons and not so much for sorting, and these examples illustrate why.
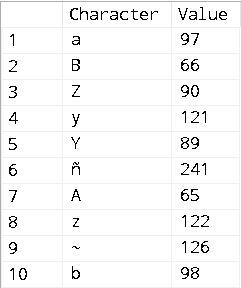
The following query, without any ORDER BY, most likely has the same order as it is defined in the VALUES list:
SELECT tab.col AS [Character], ASCII(tab.col) AS [Value]
FROM (VALUES ('a'), ('B'), ('Z'), ('y'), ('Y'), ('ñ'),
('A'), ('z'), ('~'), ('b')) tab(col);
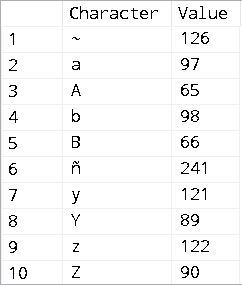
The following query uses a case-sensitive Windows Collation:
SELECT tab.col AS [Character], ASCII(tab.col) AS [Value]
FROM (VALUES ('a'), ('B'), ('Z'), ('y'), ('Y'), ('ñ'),
('A'), ('z'), ('~'), ('b')) tab(col)
ORDER BY tab.[col] COLLATE Latin1_General_100_CS_AS;
Please take note of the following from the results above:
- The tilde “~” sorts first.
- The letters — upper-case and lower-case versions — are grouped together.
- The lower-case versions of each letter sort before the upper-case versions.
- The “ñ” sorts in the middle.
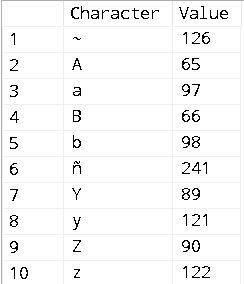
The following query uses a case-sensitive SQL Server Collation, which behaves slightly differently than the Windows Collation:
SELECT tab.col AS [Character], ASCII(tab.col) AS [Value]
FROM (VALUES ('a'), ('B'), ('Z'), ('y'), ('Y'), ('ñ'),
('A'), ('z'), ('~'), ('b')) tab(col)
ORDER BY tab.[col] COLLATE SQL_Latin1_General_CP1_CS_AS;
Please take note of the following from the results above:
- The tilde “~” sorts first.
- The letters — upper-case and lower-case versions — are grouped together.
- The upper-case versions of each letter sort before the lower-case versions.
- The “ñ” sorts in the middle.
#3 is different between the SQL Server Collation and the Windows Collation.
The following query uses a binary Collation, which again behaves differently, but even more so than the last one:
SELECT tab.col AS [Character], ASCII(tab.col) AS [Value]
FROM (VALUES ('a'), ('B'), ('Z'), ('y'), ('Y'), ('ñ'),
('A'), ('z'), ('~'), ('b')) tab(col)
ORDER BY tab.[col] COLLATE Latin1_General_100_BIN2;
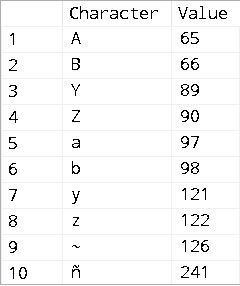
Please take note of the following from the results above:
- Unlike before, the tilde “~” now sorts after the US English letters, but before any other letters.
- Unlike before, the upper-case and lower-case versions are not grouped together.
- Unlike before, the “ñ” sorts last, not even mixed in with other letters of the same case.
All of the differences noted above are due to the ordering in a binary Collation being based entirely upon the value and nothing else.
Conclusion
While there are certainly scenarios in which a binary Collation is appropriate, or even necessary, if the desire is to have case-sensitivity, then your first attempt should be to use a case-sensitive Collation. Only use a binary Collation to achieve case-sensitivity if you encounter one of the few edge cases where a case-sensitive Collation doesn’t filter out everything that it should.
