

Bottlenecks in your testing tools, infrastructure, or methodology might just hurt your load test results, and the results can skew your metrics.
For example…
A few weeks ago we were running an iperf load test to see what improvements (if any) could be made to the configuration of a Windows Server networking stack. Setting up iperf for maximum throughput testing is easy.


The base test proved pretty fast, too!
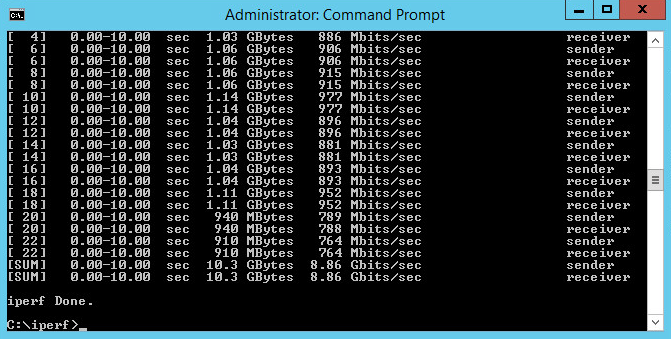
This testing was performed on our new 10GbE lab environment without jumbo frames enabled in the guest. We’ve got a Cisco Nexus 5k underneath this environment, so it is nice and fast.
We wanted to see the performance improvements with keeping this stream of data on the backplane of one physical server in our VM lab. We moved both of these VMs to the same host. Performing the same test should improve performance. I’ve seen upwards of a 16x performance improvement on a 1GbE network, so we should see at least a decent improvement on 10GbE, right?
The next test is after we moved them to the same host.
It’s virtually (no pun intended) identical.
OK. So, let’s try to make Windows a bit more efficient.

The results show a bit of improvement.
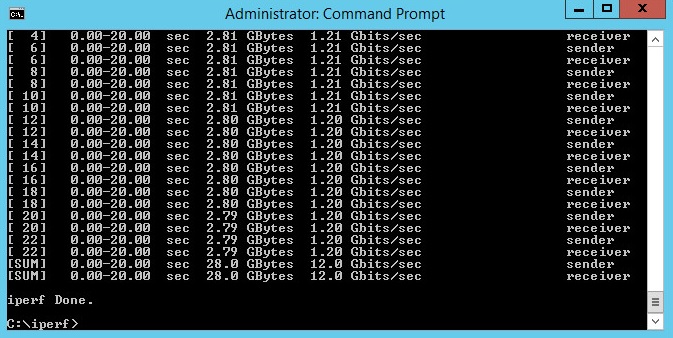
But… why did it stop there?
OK…
Looking at the system state showed us an instant bottleneck. One vCPU was maxed out, while the other was stagnant. This imbalance is one key reason why you should rarely trust a single CPU average metric coming from your monitoring tools.
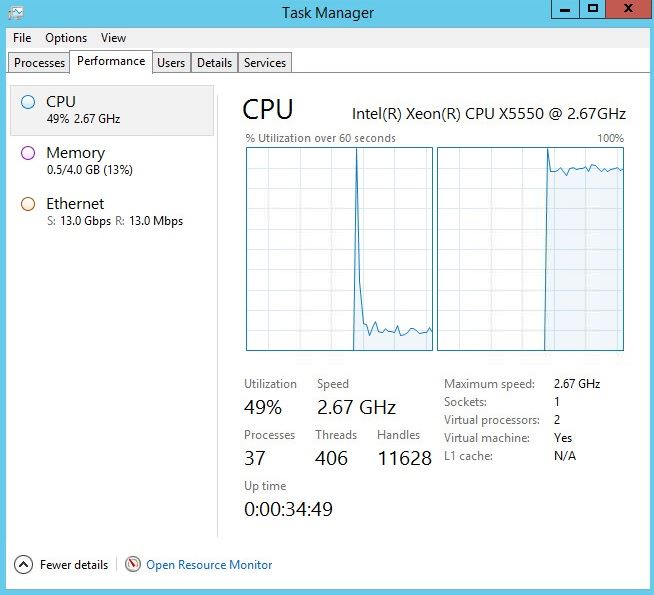
The load test utility had maxed out the compute resource that it had available, due to internal limitations within iperf itself. It’s a shame that this utility is not multi-threaded, because I think we could have a much greater result of improvement on this system.
Monitor the utilities that you’re using to do load testing, because limitations like this might skew your results!
