

By Steve Bolton
…………The sample T-SQL I posted in the last article wasn’t as difficult as it looked, considering that it merely implemented the same code on the same data we used in Information Measurement with SQL Server, Part 2.1: The Uses and Abuses of Shannon’s Entropy, except for two columns rather than one. A little more logic was required to calculate Joint Entropy from them, but a GROUP BY CUBE and some GROUPING_IDs took care of that. That sample code was basically a two-for-one deal, because we merely need to tack the practically effortless code from this article onto it. Once we’ve derived measures like Conditional and Joint Entropy, it is child’s play to derive Mutual Information, which is one of the most widely used metrics in information theory. There are many equivalent ways of deriving it, all of which involve simple subtraction and addition operations on various combinations of the Joint Entropy, @ConditionalEntropyOfBGivenA, @ConditionalEntropyOfAGivenB and the Shannon’s Entropies for Column1 and Column2.[1] All of these were already calculated in last week’s code (which I’ll omit here for the sake of brevity) so this week’s installment should be a breeze. As is often the case in information theory, the difficulties consist chiefly in interpreting Mutual Information and some of the kindred metrics depicted in Figures 1 and 2.
…………Mutual Information functions as a kind of two-way version of Conditional Entropy, so that we can gauge how much “how much knowing one of these variables reduces uncertainty about the other,”[2] rather than just about one variable given a value for the other. The interpretation is pretty much the same though: if the two variables are perfectly dependent on one another the value will be zero, but as their degree of independence rises, so does their Mutual Information. In this way, Mutual Information can be harnessed to complement standard measures of association like covariance and correlation. In coding theory it can be interpreted as the information transferred before and after receiving a signal, which can be adapted to our purposes by interpreting it as the information transferred before and after a particular event is observed and added to our records.[3] The information-carrying capacity and other properties of communication channels also play a part in determining whether or not particular messages affect the Mutual Information of a code[4], which can be interpreted in terms of the frequency of values in database tables and cubes. Daniel P. Palomar and Sergio Verdí, the reinventors of an up-and-coming alternative known as Lautum Information[5], sum up the many uses for Mutual Information quite succinctly: “Mutual information has also proven a popular measure of statistical dependence in many experimental applications such as neurobiology, genetics, machine learning, medical imaging, linguistics, artificial intelligence, authentication, and signal processing.”[6]
…………Palomar and Verdí’s measure has been lauded as replacement for Mutual Information in certain contexts based on various mathematical properties, but I had a difficult time wading through the notation in their original paper from 2008, so I had to rely on the formula given by chemist Gavin E. Crooks in a handy .pdf guide to measures of entropy.[7] As I mentioned in the last article, there are several equivalent methods of calculating Joint Entropy, so I selected the one I wagered would be easiest to incorporate in the T-SQL I had already written for Shannon’s Entropy. Among these is a formula for computing it using a division operation, which we simply need to invert to derive Lautum Information; the name is apparently an anadrome of “mutual” chosen because it means “elegant” in Latin, so it too is an inversion of sorts.[8] It may be possible to simplify Figure 1 to calculate Lautum Information inside the same INSERT that Joint Entropy is derived in (which is not included here, for the sake of brevity), or at least derive it from Joint Entropy after the fact through simpler means than a complete pass over the whole @EntropyTable table variable. Surprisingly, the convoluted solution in the fourth SELECT adds next to nothing to the performance costs, despite the fact that the @EntropyTable contains more than 9,119,674 distinct combinations for Column1 and Column2, out of the 11 million rows in the Higgs Boson dataset I’ve been using for practice data for the last few self-tutorial series.[9] It was simpler to code Shared Information Distance, another metric that has apparently gained in popularity in recent years, which has been used in cutting-edge fields like information geometry and applications like plagiarism detection.[10] Its advantages over the better-established Mutual Information metric include the fact that it obeys the triangle inequality (a transitive property related to subadditivity, that separates true “metrics” from ordinary distance measures) and that it may qualify as a “universal metric,” so “that if any other distance measure two items close-by, then the variation of information will also judge them close.”[11] The Shared Information Distance is really easy to compute[12] once we have Joint Entropy and a Conditional Entropy, which in Figure 1 is calculated via the Shannon’s Entropy for Column 1.
Figure 1: Sample T-SQL for Four Entropic Information Measures
DECLARE @MutualInformation float,
@LautumInformation float,
@SharedInformationDistance float,
@ConditionalEntropyOfBGivenA float,
@ConditionalEntropyOfAGivenB float
SELECT @ConditionalEntropyOfBGivenA = @JointEntropy – @ShannonsEntropy1,
@ConditionalEntropyOfAGivenB = @JointEntropy – @ShannonsEntropy2
SELECT @MutualInformation = @ShannonsEntropy1 + @ShannonsEntropy2 – @JointEntropy
SELECT @SharedInformationDistance = 1 – (@ShannonsEntropy1 – @ConditionalEntropyOfAGivenB) / @JointEntropy
SELECT @LautumInformation = SUM(JointProportion * Log(@JointEntropy / JointProportion))
FROM @EntropyTable
SELECT @ShannonsEntropy1 AS ShannonsEntropyForX, @ShannonsEntropy2 AS ShannonsEntropyForY, @JointEntropy AS JointEntropy,
@ShannonsEntropy1 + @ShannonsEntropy2 AS SumOfIndividualShannonEntropies,
@ConditionalEntropyOfBGivenA AS ConditionalEntropyOfBGivenA, @ConditionalEntropyOfAGivenB AS ConditionalEntropyOfAGivenB,
@MutualInformation AS MutualInformation, @LautumInformation AS LautumInformation, @SharedInformationDistance AS SharedInformationDistance
Figure 2: Self-Information and Rate Calculations
— Information and Entropy Rates
SELECT @ShannonsEntropy1 / CAST (@Count1 as float) AS EntropyRateForColumn1, @ShannonsEntropy2 / CAST (@Count2 as float) AS EntropyRateForColumn2, @JointEntropy / CAST (@JointCount as float) AS JointEntropyRate, @MutualInformation / @JointCount AS InformationRate
— Self-Information
SELECT DISTINCT Value1, –1 * Log(Proportion1, @LogarithmBase) AS SelfInformation
FROM @EntropyTable
WHERE Proportion1 IS NOT NULL
ORDER BY Value1
OFFSET 0 ROWS FETCH FIRST 100 ROWS ONLY
Figure 3: Results from the First Two Float Columns of the Higgs Boson Dataset (Click to enlarge)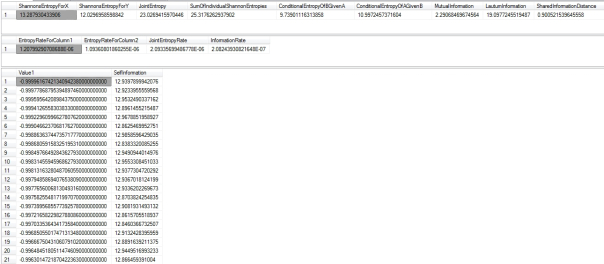
…………The routine clocked in at 1:46, four seconds faster than the sample T-SQL from the last article, despite the fact that it’s identical except for the extra routines I appended. I expected the Table Scan required for my brute force calculation of Lautum Information to add significantly to the performance costs, but it accounted for less than 1 percent of the query batch; otherwise, the execution plan was pretty much indistinguishable to the one from the last post. Note that the results also contain a sample of the first 100 Self-Information values for the first float column, as defined in Figure 2. In a nutshell, this trivial calculation[13] tells us the entropy for each individual record. This can be used to identify, partition and cluster records that offer greater potential for information gain, among other things. Like many other information metrics, it has multiple layers of meaning. At the most fundamental level, Self-Information quantifies the question, “How much can we learn when this particular event occurs?” Another subtle implication is that it may constitute another means of quantifying “surprise” in addition to the possibilistic one I mentioned in Implementing Fuzzy Sets in SQL Server, Part 8: Possibility Theory and Alpha Cuts. Rare events are surprising by definition, but also more informative in the same specific sense of all information theory entropies, which tell us how “newsworthy” specific values can be. For example, it is really rare to see spectacular lenticular, anvil or Undulatus Asperatus clouds. Their presence can tell us a lot more about the weather than ordinary patterns though, since they require specific atmospheric conditions to produce them; I don’t know what their specific entropy values would be a weather model, but I’d wager that they’d be astronomically high. In the same way, the observation of rare events with high self-information values can be a clue that some extraordinary and often highly specific underlying process is at work.
…………Figure 2 also includes code for the Information Rate, which is even more trivial than Self-Information to compute once we have Mutual Information out of the way. The term is sometimes applied to the ordinary Entropy Rate, so I differentiated it in the code by referring to it as the MutualInformationRate. Both are merely averages over different quantities, the Mutual Information and Shannon’s Entropy; I should note though that there is a supremum symbol in the equations I found for the Information Rate[14], which may mean that I need to incorporate a MAX operation somewhere in there. My usual disclaimer is always lurking in the background: I’m posting code in these tutorial series in order to absorb the material faster, not because I know what I’m doing, so check my code over before putting into production if accuracy is of paramount concern. Also keep in mind that the interpretation and calculation of both may be affected by the properties of the underlying data, such as whether or not they can modeled as irreducible or aperiodic Markov chains.[15] Further nuances can be added for calculating entropy per message in cases where the input is unknown and the Conditional Entropy “per message if the input is known,” which indicates the presence of noise if the value is non-zero.[16] Erroneous data leaves the former rate unchanged but increases the second at a steady rate dependent on the maximum probability.[17]
…………Just as with simply statistical building blocks like averages and standard deviation, the sky’s the limit when it comes to the combinations and variations we can build out of Shannon’s Entropy and its relatives. Information theory is a vast field, which was birthed in the ‘40s out of a desire to send clearer communication signals, but now extends its tendrils into fields as diverse as cryptography, data compression, Internet search algorithms and quantum physics. Modern Man is perpetually surrounded by technology that relies on the principles of information theory, regardless of whether they were introduced to the term as late in life as I was. My only concern in this series is to focus on the actual metrics used in information theory, particularly those that might be of benefit to SQL Server users in DIY data mining. In the future I might revisit these entropic measures, once I have a better understanding of which variants might be beneficial in such applications; for instance, I’m allured by the tantalizing possibility of calculating the channel capacity of neural nets, although I’m not yet sure how to go about it. I’ll cross those bridges when I come to them, but for now it would be more beneficial to shift our focus to other classes of information metrics, which calls for a whole lengthy segment on various distance and divergence measures. Shared Information Distance implies some share in that group by its very name, but it is also intimately related to Kolmogorov Complexity, a fascinating topic I hope to take up in a later segment on minimum information length metrics. Lautum Information has also apparently been referred to as the “reverse Kullback-Leibler Divergence,”[18] which links it to one of the most important distance measures used in data mining and knowledge discovery. The KL-Divergence is also known by the alias “Relative Entropy,” which has its own associated Relative Entropy Rate.[19] Mutual Information is likewise an important building block in many other information metrics, including Pointwise Mutual Information (PMI), which is used in Internet search engines; I’ll have to save PMI and related topics for a much later segment on semantic information metrics, which are rather advanced and often difficult to calculate and interpret. New information measures are being churned out by theoreticians much faster than the analytics marketplace can keep up with them; after skimming the literature over the last few years, I doubt that the gap will be crossed anytime soon, because it yawns as wide as the Valles Marineris. No single software package is going to be capable of implementing all of the worthwhile algorithms and metrics for a long time to come, which makes DIY data mining skills worthwhile to acquire. To that end, it would make sense to become familiar with certain rudimentary measures of existing knowledge, to complement entropic measures that tell us how much we don’t know about our data. To that end, next time around I’ll kick off another segment of this meandering mistutorial series with an introduction to Bayes Factors. These are fairly easily to calculate and may serve as bridges to Bayesian probability – a topic I know little about, but which makes use of Conditional Entropy – and Fisher Information, which is of vital importance in fields like data mining and information geometry. As the series progresses, metrics like these will allow us to box in the remaining uncertainty in our datasets little by little, as each new piece of the information puzzle sheds new light on our data from fresh directions.
[1] The Wikipedia page “Mutual Information” at http://en.wikipedia.org/wiki/Mutual_information is a handy reference for these formulas, but they’re readily available in many information theory texts, such as p. 16, Jones, D.S., 1979, Elementary Information Theory. Oxford University Press: New York and pp. 49-62, Mansuripur, Masud, 1987, Introduction to Information Theory. Prentice-Hall: Englewood Cliffs, N.J.
[2] See the Wikipedia page “Mutual Information” at http://en.wikipedia.org/wiki/Mutual_information. It may be a free resource and quoting from it may be frowned upon, but sometimes the contributing writers word things particularly well or provide really succinct explanations that you can’t find in professional texts in various fields.
[3] pp. 126-127, Moser, Stefan M. and Po-Ning, Chen, 2012, A Student’s Guide to Coding and Information Theory. Cambridge University Press: New York.
[4] p. 64, Mansuripur.
[5] Which was originally mentioned in a 1945 paper by renowned Hungarian statistican Abraham Wald, the inventor of the well-known Wald Test. p. 964, Palomar, Daniel P, and Verdí, Sergio, 2008, “Lautum Information,” pp. 964-975 in IEEE Transactions on Information Theory, March 2008. Vol. 54, No. 3.
[6] IBID.
[7] p. 3, Crooks, Gavin E., 2015, , “On Measures of Entropy and Information,” monograph published Jan. 22, 2015 at the ThreePlusOne.com web address http://threeplusone.com/info
[8] p. 964, Palomar and Verdí.
[9] The original source was the University of California at Irvine’s Machine Learning Repository. I converted it ages ago to a SQL Server table, which now takes up about 5 gigabytes of space in a sham DataMiningProjects database.
[10] For the latter, see Kleiman, Alan Bustos and Kowaltowski, Tomasz, 2009, Qualitative Analysis and Comparison of Plagiarism-Detection Systems in Student Programs. Technical Report available in pdf format at the Universidade Estadual de Campinas web address http://www.ic.unicamp.br/~reltech/2009/09-08.pdf
[11] See the Wikipedia page “Variation of Information” at http://en.wikipedia.org/wiki/Variation_of_information
[12] p. 3, Li, Ming, 2006, “Information Distance and Its Applications,” pp. 1-9 in Implementation and Application of Automata: 11th International Conference, CIAA 2006. Taipei, Taiwan, August 2006 Proceedings. Ibarra, Oscar H. ed. Springer-Verlag: Berlin.
[13] See p. 16, Jones and the Wikipedia article “Self-Information” at http://en.wikipedia.org/wiki/Self-information
[14] p. 219, Gray, Robert M., 2011, Entropy and Information Theory. Springer: New York.
[15] See the Wikipedia page “Entropy Rate ” at http://en.wikipedia.org/wiki/Entropy_rate
[16] p. 47-48, Goldman, Stanford, 1953, Information Theory. Prentice-Hall: New York.
[17] IBID.
[18] See Sarwate, Anand, 2013, “C.R. Rao and Information Geometry,” posted on April 13, 2013 at The Ergodic Walk web address http://ergodicity.net/2013/04/13/c-r-rao-and-information-geometry/
[19] p. 45, Goldman, Stanford, 1953, Information Theory. Prentice-Hall: New York.
