

By Steve Bolton
…………Imagine how empowering it would be to quantify what you don’t know. Even an inaccurate measure might be helpful in making better decisions in any area of life, but particularly in the business world, where change is the only certainty. This is where a program of “uncertainty management” can come in handy and fuzzy set techniques find one of their most useful applications. Fuzzy sets don’t introduce new information, but they do conserve and put to good use some information left over after ordinary “crisp” sets are defined – particularly when it would be helpful to model ordinal categories on continuous number scales. As I pointed out at the beginning of this series, uncertainty reduction is akin to Stephen King’s adage that monsters are less fearsome once some scale of measurement can be applied to them; knowing that a bug is 10 feet tall is at least reassuring, in the sense that we now know that it is not 100 or 1,000 feet tall.[1] Uncertainty reduction can also be put to obvious uses in data mining activities like prediction and clustering. Another potential use is in simplification of data, so that information loss is minimized.[2] In today’s article I’ll shine a little light on the Hartley function, a tried and true method of quantifying one particular category of uncertainty that has been used since 1928 to simplify and demystify datasets of all kinds and could easily be extended to SQL Server data.
George J. Klir and Bo Yuan, the authors of my favorite resource for fuzzy set equations, note that data models must take uncertainty into account, along with complexity and credibility. Later in the book, they go onto subdivide uncertainty into three types that sprawl across possibility theory, stochastics, information theory, fuzzy sets and Dempster-Shafer Evidence Theory:
“The relationship is not as yet fully understood…Although usually (but not always) undesirable when considered alone, uncertainty becomes very valuable when considered in connection to the other characteristics of systems models; in general, allowing more uncertainty tends to reduce complexity and increase credibility of the resulting model. Our challenge in systems modelling is to develop methods by which an optimal level of allowable uncertainty can be estimated for each modelling problem…”[3]
“…Three types of uncertainty are now recognized in the five theories, in which measurement of uncertainty is currently well established. These three uncertainty types are: nonspecificity (or imprecision), which is connected with sizes (cardinalities) of relevant sets of alternatives; fuzziness (or vagueness), which results from imprecise boundaries of fuzzy sets; and strife (or discord), which expresses conflicts among the various sets of alternatives.
“It is conceivable that other types of uncertainty will be discovered when the investigation of uncertainty extends to additional theories of uncertainty.”[4]
…………Some authors also include “ambiguity (lack of information),”[5] which Klir and Yuan define as a parent class of both discord and nonspecificity in an excellent diagram I wish I could reprint.[6] Probabilities probably also ought to be included as well.[7]As soon as I introduced to the concept of uncertainty partitioning, I was intrigued by the possibility of defining human free will as an alternative form of uncertainty, but that raises many thorny philosophical questions. Among them is the contention that it doesn’t even exist, which is a disturbing tenet of many popular philosophies, like materialistic determinism and certain forms of theological predestination. I’d dispute that with evidence that would be hard to debunk and raise the possibility that it may not be possible to quantify it at all, by definition; the ability to assign values to it would certainly be helpful in academic fields like economics and psychology, where human behavior is the crux of the matter. This topic integrates quite nicely with the contention of authors like Lofti A. Zadeh, the father of fuzzy set theory, that it might be helpful to apply fuzzy techniques in these fields to model “humanistic systems.”[8] Other controversial candidates for new categories of uncertainty include the notion that reality is somewhat subjective (which I would argue is fraught with risk, since it is a key component of many forms of madness) and the contention that some events (particularly at the quantum level) can be truly random, in the sense of being indeterminate or “uncaused.” Albert Einstein drove home the point that uncertainty is deeply rooted in all we see in his famous quote from a lecture at the Prussian Academy of Sciences in 1921, in which he seemed to extend it right into the heart of mathematics itself: “…as far as the propositions of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality.”[9]
Partitioning Uncertainty
The first step is to develop a habit of explicitly recognizing which type of uncertainty is under discussion, then partitioning it off using the appropriate type of fuzzy set. For example, whenever we need to cram continuous scales into finite data types like float, decimal and numeric, we end up creating measurement uncertainty about whatever values come after the precision we’ve chosen.[10] Like other types of measurement uncertainty, this is best addressed by fuzzy sets without any special probabilistic, possibilistic or evidence theory connotations attached to them. Incidentally, some theoreticians say that if we’re trying to quantify the uncertainty of a measurement, membership functions based on the normal distribution (i.e. the bell curve) are usually the best choice (based on empirical evidence from the aerospace industry).[11] If we were uncertain about the likelihood of an event occurring, we’d assign a probability value instead; if we were unsure of the logical necessity of an event, we’d use a possibility distribution, as explained in the last installment of this series. In the next installment, I’ll explain how Dempster-Shafer Theory can be used to judge the certainty and credibility of evidence, by assigning grades of membership in the set of true statements.
…………Once the appropriate method of uncertainty modeling has been selected, we can then apply its associated formulas to compute figures for nonspecificity, imprecision, discord and the like. The good news is that we already dispensed with the main means of computing fuzziness, back in Implementing Fuzzy Sets in SQL Server, Part 2: Measuring Imprecision with Fuzzy Complements. In the remainder of this article, I’ll provide sample T-SQL for implementing two of the three main methods for calculating the “U-Uncertainty,” a.k.a. the nonspecificity. Like many other authors I consulted for this series, Klir and Yuan stress that nonspecificity and fuzziness are completely independent stats, since they measure two distinct and unrelated types of uncertainty.[12] The former is dictated by the number of possible distinct states that a set can take on, whereas the latter quantifies imprecision in class boundaries.[13] A set can have many possible arrangements, yet still be entirely crisp; there’s no mistaking what a Lego or Lincoln Log is, but there’s apparently no end to the crazy things that can be built with either one. Sets with few arrangements but really fuzzy boundaries are also possible. That is why fuzzy sets sans any additional meaning like probability, possibility and credibility scores have both fuzziness and nonspecificity measures attached to them.
…………Possibility theory, the topic of the last blog post in this amateur series of self-tutorials, has a form of nonspecificity that is easier to specify (pun intended) than the ordinary fuzzy set version, so I’ll introduce that first. The SELECT in Figure 1 is performed on a column of muscular dystrophy data I downloaded from the Vanderbilt University’s Department of Biostatistics and added to a sham DataMiningProjects database a few tutorial series ago. The PossibilityScore was assigned by a random number generator in the last article and tacked onto the table definition, for the sake of convenience. It’s time for my usual disclaimer: I’m writing this in order to learn this topic, not because I know it well, so it is a good idea to check over my T-SQL samples before putting them to serious use. This is especially true of this SELECT, where I may be applying a Lead where there should be a Lag; in contrast to the topics I post on in previous series, examples with sample data are few and far between in the fuzzy set literature, which makes validation difficult. Furthermore, there is apparently a more compact version available for specific situations, but I’ll omit it for now because I’m still unclear on what mathematical prerequisites are needed.[14]
Figure 1: Possibilistic Nonspecificity for the LactateDehydrogenase Column
SELECT SUM(PossiblityDifference * Log(RN, 2)) AS PossibilisticUUncertainty
FROM (SELECT ROW_NUMBER() OVER (ORDER BY ID) AS RN, PossibilityScore – Lead(PossibilityScore, 1, 0) OVER (ORDER BY ID) AS PossiblityDifference
FROM Health.DuchennesTable) AS T1
…………The SELECT returns a single value of 4.28638426128113, which measures that amount of uncertainty in bits; the greater the number of possible state descriptions, the higher the U-Uncertainty will be. The same relationship applies to the procedure below, which returns a value of 7.30278910848746 bits; the difference is that one measures uncertainty about the number of possible values the LactateDehydrogenase column can have, while the other measures lack of certainty about the number of membership function scores a row can be assigned. Figure 2 is practically identical to the sample code I’ve posted throughout this series, at least as far as the UPDATE; all I’m doing is running the stored procedure from Outlier Detection with SQL Server, part 2.1: Z-Scores on the DuchennesTable and storing the results in a table variable, then transforming them to a scale of 0 to 1 using the @Rescaling variables and ReversedZScores column. The GroupRank column can be safely ignored, as usual. The first SELECT with the AlphaCutLeftBound and AlphaCutRightBound columns is only provided to illustrate the how the nonspecificity figure is arrived at in the last SELECT. What we’re basically doing is partitioning the dataset into nested levels, using the alpha cut (a-cut) technique I introduced in the last article, then applying a Base-2 LOG and summing the results across the hierarchy.[15] The tricky part is that with a-cuts, records can belong to more than one subset, as I pontificated on in my last post; the levels are widest at the bottom of the dataset, but narrowest at the top, where the MembershipScore values approach the maximum of 1.This calls for thinking about the data in an odd way, given that in most relational operations records are assigned to only a single subset.
Figure 2: Code for Hartley Nonspecificity
DECLARE @RescalingMax decimal(38,6), @RescalingMin decimal(38,6), @RescalingRange decimal(38,6)
DECLARE @ZScoreTable table
(PrimaryKey sql_variant,
Value decimal(38,6),
ZScore decimal(38,6),
ReversedZScore as CAST(1 as decimal(38,6)) – ABS(ZScore),
MembershipScore decimal(38,6),
GroupRank bigint
)
INSERT INTO @ZScoreTable
(PrimaryKey, Value, ZScore, GroupRank)
EXEC Calculations.ZScoreSP
@DatabaseName = N’DataMiningProjects‘,
@SchemaName = N’Health‘,
@TableName = N’DuchennesTable‘,
@ColumnName = N’LactateDehydrogenase‘,
@PrimaryKeyName = N’ID’,
@DecimalPrecision = ’38,32′,
@OrderByCode = 8
— RESCALING
SELECT @RescalingMax = Max(ReversedZScore), @RescalingMin= Min(ReversedZScore) FROM @ZScoreTable
SELECT @RescalingRange = @RescalingMax – @RescalingMin
UPDATE @ZScoreTable
SET MembershipScore = (ReversedZScore – @RescalingMin) / @RescalingRange
SELECT AlphaCutBound AS AlphaCutLeftBound, Lag(AlphaCutBound, 1, 0) OVER (ORDER BY AlphaCutBound) AS AlphaCutRightBound,
AlphaCutBound – Lag(AlphaCutBound, 1, 0) OVER (ORDER BY AlphaCutBound) AS AlphaCutBoundaryChange, Log(AlphaCutCount, 2) AS IndividualLogValue
FROM (SELECT Count(*) AS AlphaCutCount, AlphaCutBound
FROM @ZScoreTable AS T1
INNER JOIN (SELECT DISTINCT MembershipScore AS AlphaCutBound
FROM @ZScoreTable) AS T2
ON MembershipScore >= AlphaCutBound
GROUP BY AlphaCutBound) AS T3
SELECT SUM(AlphaCutBoundaryChange * Log(AlphaCutCount, 2)) AS FuzzySetNonspecificityInBits
FROM (SELECT AlphaCutCount, AlphaCutBound – Lag(AlphaCutBound, 1, 0) OVER (ORDER BY AlphaCutBound) AS AlphaCutBoundaryChange
FROM (SELECT Count(*) AS AlphaCutCount, AlphaCutBound
FROM @ZScoreTable AS T1
INNER JOIN (SELECT DISTINCT MembershipScore AS AlphaCutBound
FROM @ZScoreTable) AS T2
ON MembershipScore >= AlphaCutBound
GROUP BY AlphaCutBound) AS T3) AS T4
Figure 3: Results for the Hartley Nonspecificity Example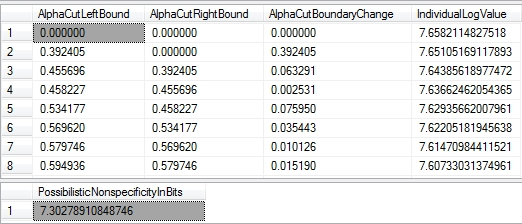
…………The point of using the a-cuts is to chop the dataset up into combinations of possible state descriptions, which is problematic with fuzzy sets because the boundaries between states are less clear. The interpretation depends entirely on the meaning of the fuzzy attribute; as Klir and Yuan note, it can reflect an “an unsettled historical question” in the case of retrodiction, possible future states in the case of prediction, prescriptive uncertainty in the case of policies, diagnostic uncertainty in the case of medical information and so forth.[16] In the same vein, we can interpret my sample above as measuring 7.30278910848746 bits of uncertainty about a record’s place within the range of Z-Scores, which can in turn be used as a form of outlier detection. The smaller the range of possible values, the smaller the number of possible state descriptions becomes, which means that the cardinality of the a-cuts and the value of the final statistic decline as well.
…………This is an adaptation of a function developed way back in 1928 by electronic pioneer Ralph Hartley[17]; since it serves as one of the foundations of information theory I’ll put off discussion of the crisp version until my long-delayed monster of a series, Information Measurement with SQL Server. We’ve got at least two more articles in the fuzzy set series to dispense with first, including an examination of Dempster-Shafer Theory in the next installment. Evidence theory also has its own brand of nonspecificity measure, also based on the Hartley function.[18] Measures like strife and discord are more relevant to that topic, since they deal with conflicts in evidence. Possibility theory has counterparts for both, but I’ll leave them out, given that Klir and Yuan counsel that “We may say that possibility theory is almost conflict-free. For large bodies of evidence, at least, these measures can be considered negligible when compared with the other type of uncertainty, nonspecificity. Neglecting strife (or discord), when justifiable, may substantially reduce computation complexity in dealing with large possibilistic bodies of evidence.”[19] Possibility theory is a useful springboard into the topic though, given that Belief and Plausibility measures are modeled in much the same way. In fact, Possibility and Necessity measures are just special cases of Belief and Plausibility, which should serve to decomplicate my introduction to Dempster-Shafer Theory a little.
[1] p. 114, King, Stephen, 1981, Stephen King’s Danse Macabre. Everest House: New York. I’m paraphrasing King, who in turn paraphrased an idea expressed to him by author William F. Nolan at the 1979 World Fantasy Convention.
[2] p. 269, Klir, George J. and Yuan, Bo, 1995, Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice Hall: Upper Saddle River, N.J.
[3] IBID., p. 3.
[4] IBID., p. 246.
[5] p. 2, Hinde, Chris .J. and Yang, Yingjie., 2009, “A New Extension of Fuzzy Sets Using Rough Sets: R-Fuzzy Sets,” pp. 354-365 in Information Sciences, Vol. 180, No. 3. Available online at the Loughborough University Institutional Repository web address https://dspace.lboro.ac.uk/dspace-jspui/bitstream/2134/13244/3/rough_m13.pdf
[6] p. 268, Klir and Yuan.
[7] IBID., p. 3.
[8] IBID., p. 451.
[9] Cited from the Common Mistakes in Using Statistics web address https://www.ma.utexas.edu/users/mks/statmistakes/uncertaintyquotes.html
[10] IBID., pp. 327-328.
[11] Kreinovich, Vladik; Quintana, Chris and Reznik, L.,1992, “Gaussian Membership Functions are Most Adequate in Representing Uncertainty in Measurements,” pp. 618-624 in Proceedings of the North American Fuzzy Information Processing Society Conference, Vol. 2. NASA Johnson Space Center: Houston. Available online at the University of Texas at El Paso web address www.cs.utep.edu/vladik/2014/tr14-30.pdf
[12] p. 258, Klir and Yuan.
[13] p. 2, Hinde and Yang.
[14] pp. 253, 269, Klir and Yuan.
[15] IBID., pp. 248-251.
[16] IBID., p. 247.
[17] See the Wikipedia articles “Hartley Function” and “Ralph Hartley” at http://en.wikipedia.org/wiki/Hartley_function and http://en.wikipedia.org/wiki/Ralph_Hartley respectively.
[18] pp. 259, Klir and Yuan.
[19] IBID., p. 264.

{kind=link}