

By Steve Bolton
…………Taking the dive into fuzzy sets immediately elicits the obvious question: just how fuzzy is the data we’re operating on? As discussed in the first two installment of this amateur series of self-tutorials, the raison d’etre of fuzzy set theory is to model imprecise data that is typically expressible in nebulous terms in everyday speech; it addresses a class of data that is represented in ordinals (i.e. categories with orders) but for which it would be helpful to at least approximate with a continuous number scale. It essentially amounts to taking the information left over after we’ve defined ordinary (i.e. “crisp’) sets and putting it to at least some good use, just as recycled aluminum and cork shavings can be used in less lucrative products like paint and corkboard. Of course, once we’ve used some of the procedures outlined in the last two articles to define them using graded membership functions, it’s natural to try to quantify the imprecision we’re modeling in some way. It at least sets a sort of outer boundary to the uncertainty we’re modeling where none existed previously, even if that barrier is not completely accurate; it is the first baby step towards a program of Uncertainty Management. The ability to apply at least some yardstick to previously unquantifiable data is useful for the same reason that the unknown is invariably certain to scare readers of horror fiction. As Stephen King puts it so well,
“You approach the door in the old, deserted house, and you hear something scratching at it. The audience holds its breath along with the protagonist as she/he (more often she) approaches that door. The protagonist throws it open, and there is a ten-foot-tall bug. The audience screams, but this particular scream has an oddly relieved sound to it. ‘A bug ten feet tall is pretty horrible,’ the audience thinks, ‘but I can deal with a ten-foot-tall bug. I was afraid it might be a hundred feet tall.’”
…………A good horror writer will of course maximize the unknown in order to scare their customers, but the object of relational database management and data mining is to minimize it, to reassure end users. We know that bugs of an entirely different kind may arise whenever uncertainty is innately woven into the tapestry of the problems software engineers, DBAs and analysts seek to solve, but these underused precision modeling tools include a yardstick with which to measure our gremlins: the fuzzy complement, which allows us to assign a ballpark figure to the amount of fuzz involved. Complements are also one of the simplest types of set relations, which can serve as a bridge into discussion of more complicated topics like fuzzy intersections, unions and joins between two sets.
…………Another single-set operation that is useful in fuzzy set theory is a partitioning method known as the alpha cut, but I’ll delay discussion of them since they’re more applicable to higher-level topics like possibility theory. Fuzzy complements and a-cuts both lead to peculiar nested subsets, albeit in different ways. In the latter case, it is because they assign to records to multiple, progressively larger subsets within the original fuzzy set, in tandem with the decrease in membership grade; in the former, it is because the various types encompass ever-wider sets of records, depending on what fuzzy complement we choose to apply and how generalized its definition is. As discussed in the taxonomy of fuzzy set types in the last article, the simplicity of these techniques quickly give rise to complexity because there are so many ways of combining these concepts; just as the difficulty in using membership functions consists mainly in the fact that there are so many we can choose from, so too does the challenge with fuzzy complements consist mostly of choosing the right type. This complexity is not an issue in ordinary crisp sets, which can be viewed as highly specific cases of fuzzy set theory. There’s no need to specify their membership functions in code because they either do or do not belong, which amounts to Boolean membership grades of 0 and 1 if we put it in fuzzy set terms. Likewise, there is only one type of complement in ordinary crisp sets, i.e. the sets of all records that don’t belong to them.
Involutive and Non-Involutive Complements
…………The whole point of membership functions is to define “belonging” in terms of a grade on a continuous scale, so by logical necessity the concept of “not belonging” that defines complements also has to be a assigned a grade on a continuous scale. The most obvious way to do this is to simply subtract a membership score from 1, assuming that we’re defining our grades on a range of 0 to 1, as is almost always the case in fuzzy set theory. This is known as the standard complement, but we’re not limited to that single choice. The injection of membership grades into set theory raises the possibility of performing further operations to alter them when we perform the inversion operation, which opens up the door to a whole class of new complements that aren’t possible in crisp sets. In fact, we’re only limited by our imagination and the restrictions that the inversion functions must be strictly increasing or strictly decreasing, i.e. the values must move in only one direction, with no repeats. A violation of this principle would appear in a Reporting Services line chart as a flat segment.
…………It is possible to define a really broad set of “non-involutive” fuzzy complements if we don’t require that the inversion function return us to the original value when applied twice[ii], but I won’t expend much time on these “since involutive fuzzy complements play by far the most important role in practical applications.”[iii] Fuzzy Sets and Fuzzy Logic: Theory and Applications, the classic resource George J. Klir and Bo Yuan I’ll be depending upon for much of the math formulas in this series, contains an elegant illustration of how the standard fuzzy complement is contained within the set of involutive complements, which is in turn nested within the set of non-involutives, which are likewise a subset of all possible continuous complements and then to the set of all fuzzy complements, without any restrictions.[iv]
Coding the Sugeno and Yager Complements
To demonstrate how these types of complements lead to different values, I calculated the complements in Figure 1 on a column in the Duchennes muscular dystrophy data I downloaded a few tutorial series ago from Vanderbilt University’s Department of Biostatistics. As in my last article, I’ll recycle the stored procedure I wrote for Outlier Detection with SQL Server, part 2.1: Z-Scores for double-duty as my membership function, but keep in mind that fuzzy sets have nothing to do with Z-Scores or probability in general – unless you specifically add that meaning, as I have done here to essentially turn it into a fuzzy outlier detection method. To illustrate the possibility of combining membership functions in myriad ways, I retrieved Z-Scores for two columns and multiplied them together, but this sample code is much simpler since we’re only acting on one column. The results of the stored procedure are plugged into a table variable identical to the one we used last time around, except for the addition of four columns to hold the complements we’re experimenting with (the GroupRank is part of the original procedure and required for the INSERT EXEC operation, but can be safely ignored). The same @RescalingMax, @RescalingMin and @RescalingRange values are used in conjunction with the ReversedZScore column to normalize the MembershipScores within ranges of 0 to 1.
…………The key difference is the addition of the @Pi, @LambdaParameter and @OmegaParameter variables, which are needed in the second UPDATE to calculate the non-involutive example[v] and the Sugeno and Yager Complements, which are the two most commonly mentioned ones in the literature. These two are useful when the problem at hand calls for bowing the number line between 0 and 1 in various arcs. When the @LambdaParameter is set to 0, the Sugeno Complement ought to be equal to the standard complement, while the Yager Complement ought to equal the same when its @OmegaParameter is set to 1. As the @LambdaParameter surpasses 0 the line bows towards lower values of both the complement and the membership grade, but at negative values it bows towards higher values of both. The Yager Complement moves in the opposite direction as its parameter is changed, but in different proportions.[vi] Although I have yet to do so in practice, these properties can be leveraged to fit different use cases – perhaps in curve or distribution fitting, sensitivity adjustments or instances where an object carries less imprecision than its negation. In essence, the act of parameterization turns them both into whole families of functions that can be adapted as needed.
Figure 1: Four Examples of Fuzzy Complements
DECLARE @RescalingMax decimal(38,6), @RescalingMin decimal(38,6), @RescalingRange decimal(38,6)
DECLARE @LambdaParameter float = 1,
@OmegaParameter float = 1, — ?
@Pi decimal(38,37) = 3.1415926535897932384626433832795028841 — from http://www.eveandersson.com/pi/digits/100
DECLARE @ZScoreTable table
(ID bigint IDENTITY (1,1),
PrimaryKey sql_variant,
Value decimal(38,6),
ZScore decimal(38,6),
ReversedZScore as CAST(1 as decimal(38,6)) – ABS(ZScore),
MembershipScore decimal(38,6),
RegularComplement float,
NonInvolutiveComplementExample float,
SugenoComplement float,
YagerComplement float,
GroupRank bigint
)
INSERT INTO @ZScoreTable
(PrimaryKey, Value, ZScore, GroupRank)
EXEC Calculations.ZScoreSP
@DatabaseName = N’DataMiningProjects‘,
@SchemaName = N’Health‘,
@TableName = N’DuchennesTable‘,
@ColumnName = N’LactateDehydrogenase‘,
@PrimaryKeyName = N’ID’,
@DecimalPrecision = ’38,32′,
@OrderByCode = 8
— RESCALING
SELECT @RescalingMax = Max(ReversedZScore), @RescalingMin= Min(ReversedZScore) FROM @ZScoreTable
SELECT @RescalingRange = @RescalingMax – @RescalingMin
UPDATE @ZScoreTable
SET MembershipScore = (ReversedZScore – @RescalingMin) / @RescalingRange
UPDATE @ZScoreTable
SET RegularComplement = 1 – MembershipScore,
NonInvolutiveComplementExample = 0.5 * (1 + Cos(@Pi * MembershipSCore)),
SugenoComplement = (1 – MembershipScore) / CAST(1 + (@LambdaParameter * MembershipScore) AS float),
YagerComplement = Power(1 – Power(MembershipScore, @OmegaParameter), 1 / CAST(@OmegaParameter AS float))
FROM @ZScoreTable
— RESULTS WITH EQUILIBRIA
DECLARE @StandardEquilibrium AS float = 0.5
DECLARE @SugenoEquilibrium AS float = (Power(1 + @LambdaParameter, 0.5) – 1) / @LambdaParameter
SELECT MembershipScore, RegularComplement, NonInvolutiveComplementExample, SugenoComplement, YagerComplement,
CASE WHEN MembershipScore – RegularComplement > @StandardEquilibrium THEN 1 ELSE 0 END AS IsGreaterThanStandardEquilibrium,
CASE WHEN MembershipScore – RegularComplement > @SugenoEquilibrium THEN 1 ELSE 0 END AS IsGreaterThanSugenoEquilibrium
FROM (SELECT MembershipScore, RegularComplement, NonInvolutiveComplementExample, SugenoComplement, YagerComplement
FROM @ZScoreTable
WHERE MembershipScore IS NOT NULL) AS T1
ORDER BY MembershipScore ASC
SELECT @StandardEquilibrium AS StandardEquilibrium, @SugenoEquilibrium AS SugenoEquilibrium
— MEASURE OF FUZZINESS
DECLARE @Count bigint
SELECT @Count=Count(*)
FROM @ZScoreTable
SELECT SUM(ABS(MembershipScore – YagerComplement)) / @Count AS SimpleMeasureOfFuzziness
FROM @ZScoreTable
WHERE MembershipScore IS NOT NULL
Figure 2: Sample Results from the Duchennes Table (click to enlarge)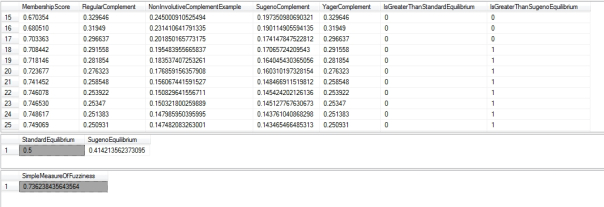
…………The concept of fuzzy complements also gives rise to two properties which are mentioned in Klir and Yuan, but for which I have yet to find a practical use: equilibria and dual points. An equilibrium represents the single value in any set where the subtraction of the complement equals zero, which is 0.5 in a standard complement but can vary from that in more advanced types of complements. The dual point is apparently an extension of equilibria to non-involutives, which are seldom used as mentioned above – so I’ll seldom mention them in this series.[vii] The sample data in Figure 1 did not contain any records where the complements values hit the equilibrium points, so I tried to illustrate the concept by declaring two variables to identify the standard and Sugeno equilibria (which requires plugging the @LambdaParameter into a simple math formula) and adding two CASE conditions to identify whether the corresponding complement was above or below its equilibrium point.
…………The end of the procedure contains an example of the most fundamental measure of fuzziness I could think of. As Klir and Yuan put it, “Another way of measuring fuzziness, which seems more practical as well as more general, is to view the fuzziness of a set in terms of the lack of distinction between the set and its complement. Indeed, it is precisely the lack of distinction between sets and their complements that distinguishes fuzzy sets from crisp sets. The less a set differs from its complement, the fuzzier it is.”[viii] In a later discussion on evidence theory, they give some clear examples of exactly what fuzziness measures:
“Observing attributes such as ‘a type of cloud formation’ in meteorology, ‘a characteristic posture of an animal’ in ethnology, or ‘a degree of defect in a tree’ in forestry clearly involves situations in which it is not practical to draw sharp boundaries; such observations or measurements are inherently fuzzy and consequently, their connection with the concept of the fuzzy set is suggestive. In most measurement in physics, on the other hand, such as the measurement of length, weight, electric current, or light intensity, we define classes with sharp boundaries.”[ix]
…………They go on to provide an example which uses the Hamming Distance to measure the difference between each membership grade and its complement, but I chose to go the even simpler route of devising a mere ratio of the differences to the overall count. Later in the series I’ll explain how partial set membership introduces many alternative definitions of cardinality and other statistics, but to stay on point I used a regular “crisp” count here. Note how we’ve added yet another layer of complexity here: we’re no longer dependent just on varied definitions of complements, but also of the measurement we choose to use. This leads to greater potential of getting lost in an endless sea of choices, but it can also empower us by letting us choose a distance measure that is best suited to the kind of fuzziness we’re trying to measure. It might be useful in one instance to use a simple Euclidean Distance, in another we might want to work in a Küllback-Leibler Divergence and in another, it might pay to figure out what the heck an Isaura-Saito Distance is and code it. In Figure 2, we can see that the Yager Complement leads to a fairly high measure of imprecision in this case, at 0.736238435643564, which would change in tandem with our parameter choices. Perhaps we don’t know what the ideal parameter choices would be, but this at least gets us on the board with a measure of imprecision where we had none whatsoever before.
…………In the next couple of articles I’ll show how these concepts can be extended in equally useful ways to fuzzy intersections, unions and common join types. These topics are a bit more complicated, since we’re using binary relations rather than simple reflexive ones like complements. If we want to store the values of set operations of this kind, the options are easier to choose from in the case of complements: 1) using indexed views with the parameter values baked into them, or 2) creating special tables to hold the values of the Sugeno, Yager, etc. parameters if we need to reuse them in other SQL statements. In the second modeling option, it might pay to store all of the complement parameters in a single table, possibly for a whole schema or database, with some sort of text key identifying the table/view and column they’re associated with. If we wanted to also store the row values derived from the Sugeno and Yager functions for later retrieval, we might create a ComplementValueTable with one foreign key on our ComplementTable and another leading to the primary key of whatever table the row belongs to. We wouldn’t be able to leverage a FOREIGN KEY REFERENCES to enforce these relationships unless we used multiple ComplementValueTable, each associated with a different table with fuzzy data. The issue of fuzzy set relation storage takes us in strange data modeling directions because there are so many different options with unions, joins and the like that simply aren’t available to us with crisp sets. We can at least rule out many-to-many join on a ComplementTable of any kind, because complements are a reflexive relationship. That is no longer true when we’re speaking of intersections and other binary relations that add another layer of both complexity and problem-solving potential, as we’ll see in two weeks.
p. 114, King, Stephen, 1981, Stephen King’s Danse Macabre. Everest House: New York. King said he was basically paraphrasing an idea expressed to him by author William F. Nolan at the 1979 World Fantasy Convention.
[ii] For the definition of the term, I consulted the Wikipedia page”Involution (Mathematics)” at http://en.wikipedia.org/wiki/Involution_(mathematics).
[iii] p . 59, Klir, George J. and Yuan, Bo, 1995, Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice Hall: Upper Saddle River, N.J.
[iv] IBID., p. 57.
[v] IBID. Adapted from a cosine-based formula on p. 54.
[vi] IBID., pp. 55-57.
[vii] IBID., pp. 57-59.
[viii] IBID., p. 255.
[ix] IBID., p. 179.

![]()
