

By Steve Bolton
…………Early on in this series, we learned how the imprecision in natural language statements like “the weather is hot” can be modeled using fuzzy sets. Ordinarily, the membership grades assigned to fuzzy sets are not to be interpreted as probabilities, even though they’re both implemented on continuous scales between 0 and 1; the exception to this rule is when a probabilistic meaning is consciously assigned to the type of fuzziness. A couple of articles ago we saw how membership scores can be interpreted as assessing the logical possibility of the associated statements; the possibility distributions this nuance gives rise to quantifies whether or not an event can occur, whereas a probability distribution assesses whether it will actually occur. The two scales are independent except at the maximum and minimum values, where possibility values acts as caps on probabilities, since an event must be possible if it is to have a non-zero probability. The possibility and necessity measures that factor into possibility distributions are actually special cases of the plausibility and belief measures used in Dempster-Shafer Evidence Theory, which has a related shade of meaning: instead of gauging whether or not an event can or will happen, plausibility and belief work together to grade the credibility of the associated evidence. If we were sifting through user stories in a Behavior-Driven Development (BDD) process, we wouldn’t use evidence theory for fuzzy terms like “the weather is hot,” or questions like “the weather could be cold” or “the weather is probably mild,”[1] which might be candidates for possibilistic or stochastic modeling. “As far as I can tell, the weather will be hot,” might be fair game, since the subject of the sentence is the trustworthiness of the associated statement. The clearest example I’ve yet run across in the literature occurs in George J. Klir and Bo Yuan’s Fuzzy Sets and Fuzzy Logic: Theory and Applications, which I’ve used as my go-to resource throughout this series for the heavy math formulas:
“Consider, however, the jury members for a criminal trial who are uncertain about the guilt or innocence of the defendant. The uncertainty in this situation seems to be of a different type; the set of people who are guilty of the crime and the set of innocent people are assumed to have very distinct boundaries. The concern, therefore, is not with the degree to which the defendant is guilty, but with the degree to which the evidence proves his membership in either the crisp set of guilty people or the crisp set of innocent people.”[2]
In the last article, I gave a monologue on how organizations can benefit from uncertainty management programs, which begins with partitioning uncertainty into various types, like probabilities, nonspecificity, fuzziness and conflicting information; these in turn stretch across five mathematical subtopics, information theory, stochastics, possibility theory, fuzzy sets and evidence theory. The last of these has its own corresponding formulas for measures like nonspecificity, but is particularly useful for quantifying the degree of conflict between pieces of information. For this reason, it is widely used to aggregate disparate sources of information, which in turn integrates seamlessly with Decision Theory; for example, one of its most common implementations is sensor fusion.[3] Klir and Yuan also provide a concise list of possible use cases in various fields:
“For instance, suppose we are trying to diagnose an ill patient. In simplified terms, we may be trying to determine whether the patient belongs to the set of people with, say, pneumonia, bronchitis, emphysema, or a common cold. A physical examination may provide us with helpful yet inconclusive evidence. For example, we might assign a high value, say 0.75, to our best guess, bronchitis, and a lower value to the other possibilities, such as 0.45 for the set consisting of pneumonia and emphysema and 0 for a common cold. These values reflect the degree to which the patient’s symptoms provide evidence for the individual diseases or sets of diseases; their collection constitutes a fuzzy measure representing the uncertainty associated with several well-defined alternatives; It is important to realize that this type of uncertainty, which results from information deficiency, is fundamentally different from fuzziness, which arises from the lack of sharp boundaries.”[4]
…………Thankfully, a sturdy mathematical scaffolding to model these types of evidence-based uncertainty already exists, although it isn’t being tested much these days in the relational database, data warehousing and data mining fields. The modeling process is akin to the one I introduced a few weeks ago for possibility distributions, but a tad more complicated. A continuous data type like float, numeric or decimal is required for probability values, but possibility theory also calls for the addition of a bit column, which is often assigned to the Necessity measure. In the theory developed independently by statisticians Glenn Shafer and Arthur Dempster, we need three measures: a Probability Mass Assignment (often denoted by a lower case m) that tells us the strength of the evidence that a record belongs just to one set; a Belief measure that measures the same, plus the evidence for belonging to its subsets; and a Plausibility measure, which covers both of those, as well as “the additional evidence or belief associated with sets that overlap with A.”[5] The easy part is that all three are measured on scale of 0 to 1, the same as fuzzy sets, probabilities, possibilities and the like; the complexity arises from the fact that they measure evidence at different levels. This leads to nested bodies of evidence, which alpha cuts (a-cuts) are ideal for modeling, as explained a couple of articles ago; I saved this topic for the next-to-last article precisely because it unites many of the concepts introduced throughout the series, like a-cuts, fuzzy unions, intersections and complements.
…………These relationships also give rise to various mathematical properties, some of which are similar to those used in possibility distributions. For example, just as Necessity is equal to 1 minus the complement of Possibility, so too is Plausibility equal to 1 minus the complement of the Belief measure. Plausibility must be greater than or equal to the Belief, since it models evidence at a higher scope. These “fuzzy measures” have weakened forms of properties like monotonicity, continuity and additivity than probabilities do.[6] Belief measures are superadditive, which means that if you sum them together across the subsets, the result must be greater than or equal to the Belief function for the whole set. For example, the Belief function for the whole set can be a figure less than 1, say 0.97, but the individual measures of each subset can be assigned degrees of belief like 0.5, 0.87, 0.3, etc. which together sum to 1.67, which is valid because it’s greater than 0.97. In contrast, probabilities must always sum to 1 across a dataset, including the probability mass assignments used in evidence theory. Plausibility is subadditive, which signifies the opposite relationship, so that the measures taken across the subsets must sum to the at least the Plausibility for the whole set. In short, they act as maximums rather than sums. This all sounds weird, but it’s a necessary logical consequence of the nesting of evidence. As explained in the discussion on a-cuts a couple of articles ago, this signifies that records can belong to multiple hierarchical partitions of a set, which is an unfamiliar situation in the relational world (despite the fact that it is easily modeled using set-theoretic relational technology). The good news is that this web of interrelationships makes the three evidence theory measures reconstructible from each other; this makes it possible to validate the values using queries like the samples in Figure 2.
Two Common Illustrations of Dempster-Shafer Evidence Theory in Action
The Wikipedia article on Dempster-Shafer Theory has comprehensible examples of how these three measures work together, beginning with a sensor that detects whether a cat concealed in a box is in a Dead or Alive state. The value for Either obviously reaches the maximum value of 1 for both Belief and Plausibility, since it must be one of the two by logical necessity (that is, unless our cat happens to belong to Erwin Schröedinger or was buried in Pet Sematary). It is thus an instance of a “universal hypothesis,” which encompasses the whole dataset. Yet the probability mass assignment for the Either state is only 0.3, which signifies the fact that we don’t have solid information on its status; the probability figure for the whole dataset still sums to 1 though, once the stats for Alive and Dead are factored in. The probability value for the universal hypothesis thus constitutes a measure of the uncertainty remaining in the data, once the probability, Belief and Plausibility measures have partitioned it off. Since Dead and Alive are discrete states without fuzzy intervals, the Wikipedia example assigns them Belief figures equal to their probability masses – which when added to the value of 1 for the Either state, means that the total Belief for the whole dataset is greater than 1, unlike the probability mass. The Plausibility can then be reconstructed using the inverse of the complement of the Belief.
…………The tricky part is that the Belief measures must sum to 1 for each subset, which calls for looking at our data in an unfamiliar way. I initially thought that the existence of these subsets meant that we could simply model this by applying the appropriate normal form, but that’s not the case. The second example in the Wikipedia article has examples of states like Red, Yellow, Green which are mutually exclusive, as well as some that carry a bit of measurement uncertainty, like “Red or Yellow” and “Red or Green.” In this situation, the Belief figures for Red, Yellow and “Red or Yellow” must sum to 1, as must the Belief figures for Red, Green and “Red or Green,” since there are two overlapping subsets. Red, Yellow and Green are all members of more than one subset, but not the same ones. This leads to an odd predicament where each state is discrete and thus difficult to denormalize, yet the associated column still represents subsets; this is one situation where the presence of logical OR statements is not a hint that the design requires normalization. Since we can’t be certain how many other state descriptions a child could be related to, a single self-referencing ParentID column won’t do the job either. The next best thing is an interleaved solution, in which a separate table with two foreign keys pointing to the primary key of the table holding the Belief measures to keep track of which subsets each record belongs to. To aggregate the Belief figures for each subset in the parent table, we just inspect the interleaved table for all of the categories a record can belong to.
Server States: A SQL Server-Specific Example
Let me give an example that might be more intuitive and relevant to SQL Server users: the state_desc column of sys.databases will assign one of seven mutually exclusive states to each database: Online, Offline, Restoring, Recovering; Recovery Pending, Suspect and Emergency. As far as I know, these states do not rule out which user modes a database can be, which range from SINGLE_USER to RESTRICTED_USER to MULTI_USER. Nevertheless, many combinations would be improbable, so each unique pair of descriptions requires a probability assignment that will probably differ from other pairs of state_desc and user mode values. Now let’s pretend we have a sensor that guesses which of pair of states a server is in at any given moment, perhaps based on I/O data or network bandwidth usage. If it can tell us the user mode plus whether we’re in one of the three recovery states, but can’t differentiate between them accurately, then we’re dealing with a fuzzy interval-valued set. From the point of view of the sensor, “Restoring | Recovering | Recovery Pending” is a discrete state and ought to be recorded as such in the database table. Nevertheless, to derive the Belief we must sum together all of the probabilities for the subsets it gives rise to, while the Plausibility equals one minus the sum of the probability assignments in the subsets it does not participate in. We could create a separate category like “Unknown” for situations where the sensor went offline or was otherwise unable to return accurate data – or better yet, establish a universal hypothesis like “Any State” with the Belief and Plausibility both set to 1 and we add all of its possible subsets. Subtracting the sum of the probabilities of all known states from that of the universal hypothesis would allow us to measure one type of uncertainty associated with the table. In order to measure the uncertainty inherent in the interval-valued fuzzy subsets that the Belief and Plausibility measures are attached to, we’d have to use a measure of fuzziness tailored to evidence theory. In the same vein, the count of possible state descriptions could be used to derive a measure of nonspecificity, albeit through a different formula than the ones introduced in the last article. In addition, we can define measures of uncertainty based on how much
…………It is easier to illustrate all of this with T-SQL code samples, beginning with the easiest part, a simple snapshot of a table with probability mass, Belief and Plausibility measures defined on it. Degrees of Belief are usually derived from some kind of input method, akin to fuzzy set membership functions – except that subjective ratings tend to be more common in evidence theory. It is no surprise that Bayesian methods are often applied in deriving Belief functions, given that they actually represent a more specific subset of evidence theory measures. Instead of complicating the topic any further, I’ve derived the values in Figure 1 by creating an artificial category in the Duchennes muscular dystrophy data I’ve been using for practice data for the last few tutorial series[7], then simply assigned probability mass assignments based on the frequency of the values for the LactateDehydrogenase column. From there, I derived the Belief measures, then constructed the Plausibility measures from those. I used the float data type for all three of the columns that associate measured with the LactateDehydrogenaseState column, an ordinal category; this represents yet another use of fuzzy sets to model ordinals on continuous scales, except at a more advanced level where three columns are required.
Figure 1: Simple Evidence Theory Measures Defined on the LactateDehydrogenase Column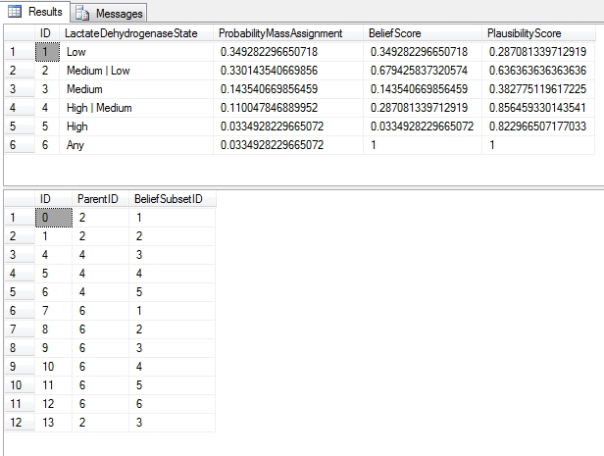
Figure 2: Sample Validation Code for the Relationships Between the Three Evidence Theory Measures
— verifying the Belief via the ProbabilityMassAssignment mass assignment
SELECT ID, LactateDehydrogenaseState, ProbabilityMassAssignment, BeliefScore, PlausibilityScore,
CASE WHEN IntervalProbabilityMassAssignmentSum IS NOT NULL THEN IntervalProbabilityMassAssignmentSum ELSE ProbabilityMassAssignment END
AS BeliefReconstructedFromProbabilityMass
FROM Health.DuchennesEvidenceTheoryTable AS T3
LEFT JOIN (SELECT ParentID, SUM(ProbabilityMassAssignment) AS IntervalProbabilityMassAssignmentSum
FROM Health.DuchennesEvidenceTheoryTable AS T1
INNER JOIN Health.DuchennesEvidenceTheoryIntervalTable AS T2
ON T1.ID = T2.BeliefSubsetID
GROUP BY ParentID) AS T4
ON T3.ID = T4.ParentID
SELECT ID, LactateDehydrogenaseState, BeliefScore, ProbabilityMassAssignment, ProbabilityMassAssignmentBySum,
CASE WHEN ProbabilityMassAssignmentBySum IS NULL THEN 1 ELSE ABS(1 – (ProbabilityMassAssignment+ ProbabilityMassAssignmentBySum)) END AS PlausibilityScoreReconstructedFromProbability
FROM (SELECT ID, LactateDehydrogenaseState, BeliefScore, ProbabilityMassAssignment
FROM Health.DuchennesEvidenceTheoryTable) AS T5
LEFT JOIN (SELECT BeliefSubsetID, SUM(ProbabilityMassAssignment) AS ProbabilityMassAssignmentBySum
FROM (SELECT DISTINCT T1.BeliefSubsetID, T2.ParentID
FROM Health.DuchennesEvidenceTheoryIntervalTable AS T1
INNER JOIN Health.DuchennesEvidenceTheoryIntervalTable AS T2
ON T1.ParentID = T2.BeliefSubsetID AND T1.BeliefSubsetID != T2.BeliefSubsetID) AS T4
INNER JOIN Health.DuchennesEvidenceTheoryTable AS T3
ON T4.ParentID = T3.ID
GROUP BY BeliefSubsetID) AS T6
ON T5.ID = T6.BeliefSubsetID
…………Note how the Belief is equal to the ProbabilityMassAssignment for Low, Medium and High, which is reflective of the fact that they have no substates; Medium or Low and High or Medium have BeliefScore values higher than their masses, precisely because we have to tack the values for Low, Medium and High onto them. The PlausibilityScore is in each case determined by adding together all of the ProbabilityMassAssignment values for the columns that aren’t among a record’s subsets, then taking an inverse, which is equivalent to subtracting the complement of the BeliefScore from 1. The second image depicts the Health.DuchennesEvidenceTheoryIntervalTable, in which the ParentID and BeliefSubsetID determine the linkages between subsets. For example, the records with ParentIDs of 4 tie together the Medium | Low, Medium and High | Medium values, so that we can aggregate the ProbabilityAssignments to derive the BeliefScore. The PlausibilityScore can be determined using the same table. Code similar to what I provided in Figure 2 can be used to validate the relationships between these fuzzy measures, with your own particular column and table names plugged in of course. The IS NULL condition is due to a bizarre problem in which setting the first condition in the CASE to BeliefScore = 1 THEN 1, or using NullIf, both led to NULL values. It is also possible to derive the ProbabilityMassAssignment values in reverse, but I’ll omit validation code for that scenario in the interest of brevity. To avoid pummeling readers with too much information all at once, I’ll also put off discussion of how to derive uncertainty measures like Strife and Discord from this crude example. In the next article, I’ll also mention some principles for interpreting the results that can in turn provide an important bridge to Information Theory. Among other things, the first table tells us that, “the belief that the Lactate Dehydrogenase values are Medium or Low is higher than that for Low alone, by a margin of 0.679425837320574 to 0.349282296650718. It is more plausible that the value is High than Low, by a margin of 0.822966507177033.” Once we define measures of fuzziness, nonspecificity and the like on top of them and apply some principles of inference drawn from Information Theory, we can partition the uncertainty further in order to glean additional valuable insights.
[1] Here in Western New York the natural language term “mild” has interesting shades of meaning (at least among local weathermen) which would be a challenge to model in terms of a fuzzy set. As winter approaches, “mild” means warmer than normal, but as the peak of summer comes, it means cooler than expected, so the meaning is inverted depending on the season. If we were to use an interval-valued set, we’d need a range ofvalues somewhere between 30 and 70 degrees – which is so imprecise that it borders on meaningless.
[2] p. 177, Klir, George J. and Yuan, Bo, 1995, Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice Hall: Upper Saddle River, N.J.
[3] See the Wikipedia article “Dempster Shafer Theory” at http://en.wikipedia.org/wiki/Dempster%E2%80%93Shafer_theory
[4] p. 179, Klir and Yuan.
[5] IBID., p. 181-182.
[6] IBID., p. 179-181.
[7] Which I downloaded from the Vanderbilt University’s Department of Biostatistics and converted into a SQL Server table in my sham DataMiningProjects database.
