

Recently I got a hold of my Untappd data. For those who don’t know the app, it’s a rating app for beers. You can check-in a beer each time you drink one (by scanning the barcode for example), and then rate it, assign flavors et cetera. I did a GDPR request to get all my personal data from the app, and they sent me a nice CSV file.

I loaded the data into a table in Azure SQL DB. For demo purposes, I want to transfer this data from a SQL table to a container in Azure Cosmos DB (with the NoSQL API). There are plenty of resources on the web on how to transfer a simple relational table to Cosmos DB, but I have some additional complexity. One column – flavor profiles – contains a list of flavors that is assigned to a beer.

In a decently normalized database, this would have been stored in a separate table (hence the title of this blog post). This means that in the resulting JSON document in Cosmos DB, the flavor profiles are a nested array. Unfortunately, the Copy Data activity in Azure Data Factory doesn’t support this when you try to map your SQL Server columns with the document structure.
A work around is to do the data load in two steps:
- First we create a JSON document for each row of the table using the FOR JSON clause. The result is stored in a single JSON file in Azure Blob Storage.
- Next, we import this JSON file and write it to Azure Cosmos DB.
With the following SQL query, we can transform the relational data into JSON documents:
SELECT [value]
FROM OPENJSON(
(SELECT
[beer.beer_name] = beer_name
,[beer.beer_type] = beer_type
,[beer.beer_ibu] = beer_ibu
,[beer.beer_abv] = beer_abv
,[beer.beer_url] = beer_url
,comment
,[venue.venue_name] = venue_name
,[venue.venue_city] = venue_city
,[venue.venue_state] = venue_state
,[venue.venue_country] = venue_country
,[venue.venue_lat] = venue_lat
,[venue.venue_lng] = venue_lng
,rating_score
,created_at
,checkin_url
,[brewery.bid] = bid
,[brewery.brewery_id] = brewery_id
,[brewery.brewery_name] = brewery_name
,[brewery.brewery_url] = brewery_url
,[brewery.brewery_country] = brewery_country
,[brewery.brewery_city] = brewery_city
,[brewery.brewery_state] = brewery_state
,[flavor_profiles] = ( SELECT s.value AS flavor
FROM STRING_SPLIT(j.flavor_profiles,',') s
FOR JSON PATH
)
,purchase_venue
,serving_type
,checkin_id
,photo_url
,global_rating_score
,global_weighted_rating_score
,tagged_friends = ( SELECT s.value AS tag
FROM STRING_SPLIT(j.tagged_friends,',') s
FOR JSON PATH
)
,total_toasts
,total_comments
FROM dbo.untappd j
FOR JSON PATH)
);For the flavor profiles (and any friends that were tagged), a subquery is used to create the nested array. If your data is stored in different tables, you can use the FOR JSON clause to create the inner arrays, then join this against the base table.
The properties for the beer, brewery and venue are grouped together in objects. An example of a single JSON document:
{
"beer": {
"beer_name": "Duvel",
"beer_type": "Belgian Strong Golden Ale",
"beer_ibu": "33",
"beer_abv": "8.5",
},
"comment": "Bij den Ellis Burger in Leuven",
"venue": {
"venue_name": "Ellis Gourmet Burger",
"venue_city": "Leuven",
"venue_state": "Vlaams-Brabant",
"venue_country": "Belgium",
"venue_lat": "50.8784",
"venue_lng": "4.70091"
},
"rating_score": "5",
"created_at": "2021-05-29T16:47:15",
"brewery": {
"brewery_id": 167,
"brewery_name": "Duvel Moortgat",
"brewery_country": "Belgium",
"brewery_city": "Puurs",
"brewery_state": "Vlaanderen"
},
"flavor_profiles": [
{
"flavor": "strong"
},
{
"flavor": "smooth"
}
],
"serving_type": "Bottle",
"checkin_id": "1033328633",
"global_rating_score": "3.73",
"global_weighted_rating_score": "3.73",
"total_toasts": 1,
"total_comments": 0
}In Azure Data Factory (ADF), we add a pipeline with a Copy data activity. As the source, we specify a SQL dataset containing the query mentioned above:
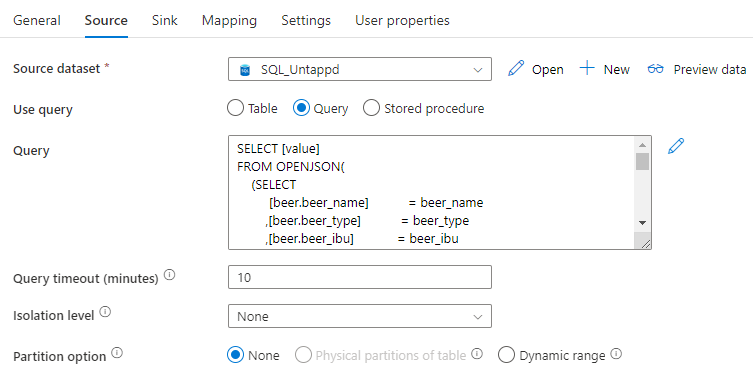
As the sink, we use a CSV file on Azure Blob Storage:
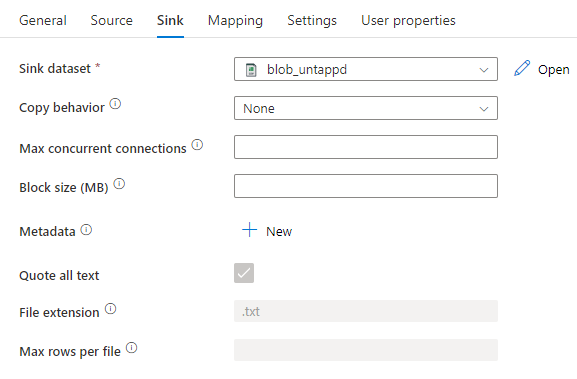
Important is that in the dataset settings, we don’t specify an escape or a quote character. As the delimiter, we choose a character which should not appear in the data and there’s no header.
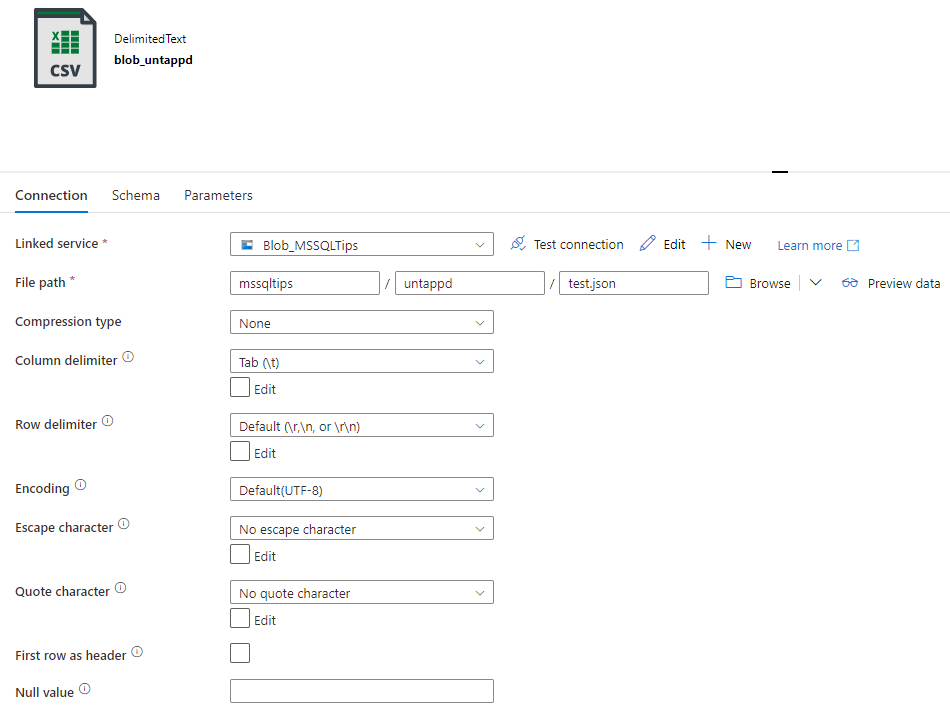
The mapping is left blank. When we run this Copy data activity, we get a JSON file that contains one JSON document per line:

Next, we add another Copy data activity to the pipeline. As the source, we use the same JSON file that was created in the previous activity. However, now we don’t use a CSV dataset, but a JSON dataset (but they’re both pointing to the same file).
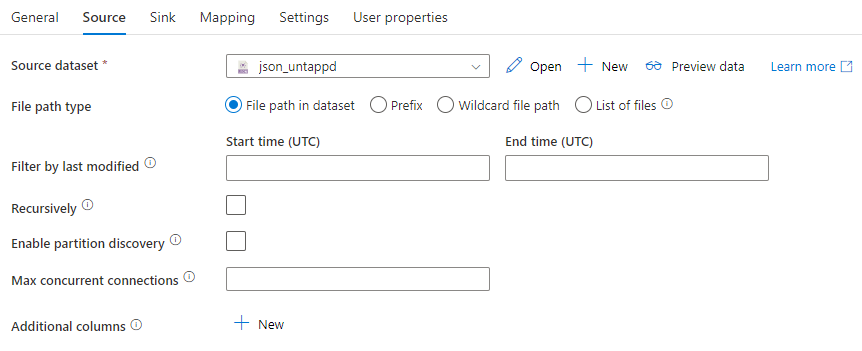
As the sink, we configure our Azure Cosmos DB container.

Again, we don’t specify a mapping. Running this activity will insert all those JSON documents as separate items in the container.
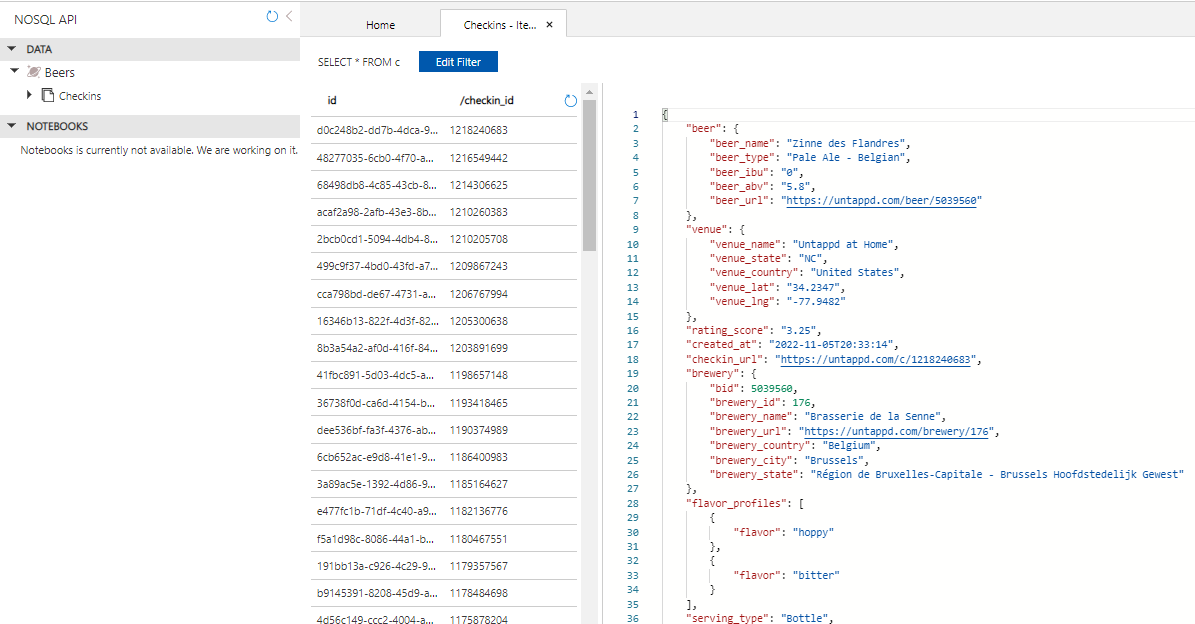
In contrast with some other tools, we don’t need to specify the clustering key of the container in ADF. As you can see from the screenshot, the objects and arrays are preserved when imported into Cosmos DB.
The post How to Store Normalized SQL Server Data into Azure Cosmos DB first appeared on Under the kover of business intelligence.