

One of the common source data files that every ETL Developer/Architect will have to grapple with every now and then is XML source files. This is even truer given how common distributed systems have become and the need for applications from different sources and protocols to share data and communicate.
In this article, I will be showing how to use the SSIS Script Component to consume XML files.
Business Problem and Requirement
I recently got involved in a data warehouse project and one key requirement on the ETL implementation, was loading and processing very large XML source data feeds daily (About 50 files , each with averages sizes between 7-10GB) .
Performance of this process had deteriorated over time and one of the project deliverables was to ensure that job run as fast as possible, extract certain fields from the XML document and ignore the rest.
The Solution
Thankfully there are a number of approaches like say the XML Task/Source component and shredding XML data with SQL that can be used in consuming XML files and as with most things in Data Warehousing the answer to which option to use in solving a particular problem is “It depends”. Thus given the business problem and requirements at hand, I would like to share with you an approach I used in solving this problem. Although this approach involved some custom coding, it gives the developer full control of the way the required fields are extracted.
To address the business problem, I used a design pattern that uses
- Script Component.
- LINQ to XML
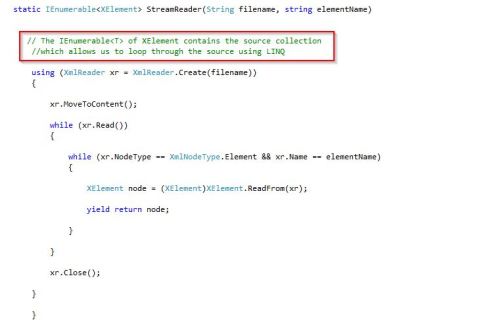
- The XMLReader .NET class to stream the XML documents
So, dear reader, please roll up your sleeves and let’s get started.
To simulate the process, I am using a sample Books. XML file which can be downloaded from here
- Start by opening up SQL Server Data Tools for Visual Studio (SSDT).
- Use the default package or create a new one, giving it a meaningful name.
- Drag and drop a Data Flow Task (DFT) onto the Control Flow pane of the package used in Step 2 and rename it to something meaningful.

- Double Click the DFT to open up the Data Flow page.
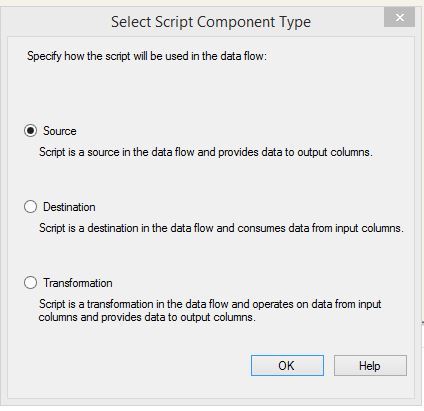
- Drag and drop the Script Component transform (I renamed this to “Load XML data”) on the data flow canvass and select “Source” from the Script Component type dialog.
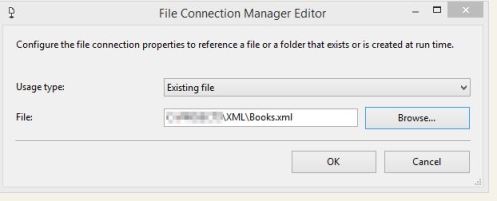
- Add a file connection manager to your package.
- Set Usage Type to Existing File and set the path to our XML source file.
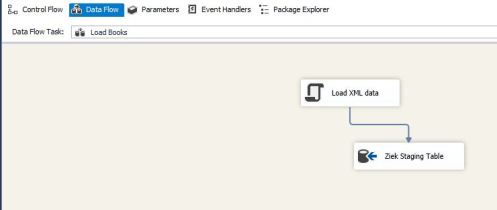
- In this article, I will just be extracting the required fields and load them into a staging using an OLE DB destination (I renamed to “Ziek Staging table”). However you can perform other transformations as required prior to loading your staging tables.
- Double-click the script component to open up the editor.
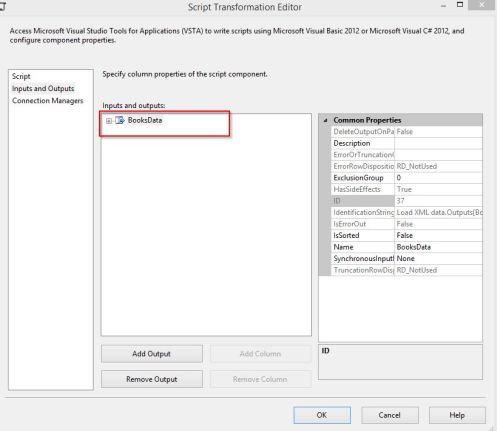
- Click the Inputs and Outputs page.
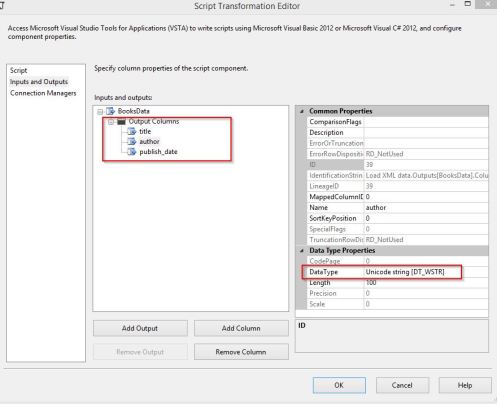
- Rename your output from Output 0 to something more meaningful. I renamed this to “BooksData” since my sample data is a collection of Books.
- Expand the “BooksData” node, click on the “Output Columns” folder and use the “Add Column” button the add the required output fields and ensure each field is set to the appropriate data type. In this demonstration I am outputting only three fields (Title, Author and Publish_Date).
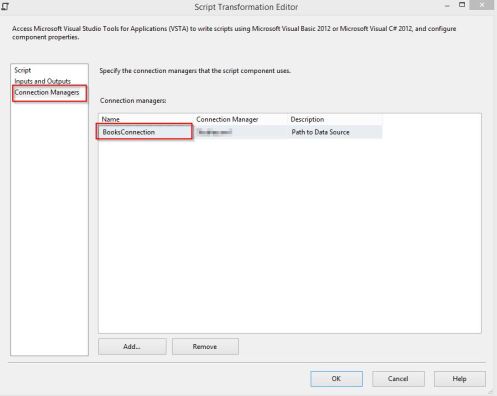
- On the Connection Managers page and add a reference to the file connection manager created in step 6 and give the connection manager a meaningful name. Example “BooksConnection”.
- Next go the Script page and click the “Edit Script” button to launch the VSTA script editor. Now this is where we’ll writing the custom code and making use of the powerful .NET classes I mentioned earlier. For the uninitiated, this can be a bit daunting but please follow me as we go through this journey.
- To keep this simple for now, I will be adding custom code to the “CreateNewOutputRows” method of the ScriptMain class and override the “AcquireConnection” method from the base class. Before continuing let me briefly explain, perhaps in a layman’s terms, what Overriding and base classes in C# parlance are. Overriding and base classes are concepts of object-oriented programming that allows one to re-use existing code (in a base class) and override an existing code in the base class with your own or custom implementation for that code. You can find further reading here and at this place too.
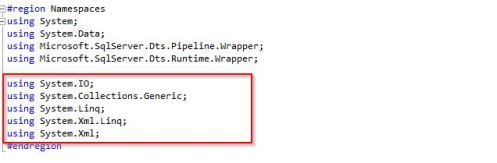
- Once in the script editor, in order to process the XML data with XmlReader and LINQ to XML, we firstly have to import the highlighted namespaces.
- To add missing/non-existing References;- In the Code editor, right click the Reference node- Click On “Add Reference”
– Then select the references from the reference manager dialog.
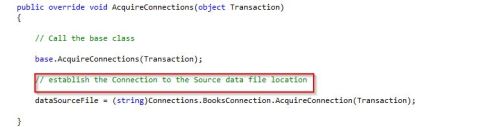
- The “AcquireConnection” method will retrieve the path to our XML file from the connection manager configured in step 13. The code is shown below;
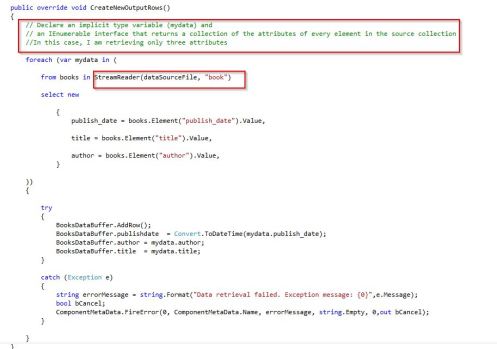
- The “CreateNewOutputRows” method is where the majority of the work will happen i.e. extracting the required fields and sending them down to the data flow. I have highlighted some of the comments in red boxes and please note that the “BooksDataBuffer” object is used as a “store” from where the data is sent through to its destination.
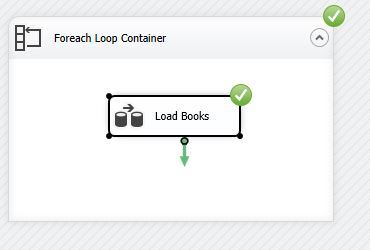
- For a simple test case in this article, I used the ForEach loop container to dynamically load two sample XML files (I will expand on this a future post) and as shown below the data load succeeded.

Conclusion
In this article, I have shared how I was able to re-factor an XML data loading job to have it run in an acceptable and perform better. Although there are several other methods to load XML files, I recommend that if you are not “scared” of writing .NET code, please do consider this approach especially if you need more control over how the XML is parsed, need to process large XML files as fast as possible and performance is of prime importance.
In a future post, I will show how to check if a XML file exists, validate it using its XSD schema before processing. Thanks for reading and as always, any comments or suggestions are welcome.
.
