
(2021-Mar-15) While watching the first MiB movie with my family, it was quite clear that the character played by Will Smith at first didn’t have a clear idea about what the “galaxy is on Orion's belt” phrase really meant, {spoiler alert} only then to understand that a galaxy could be as small as a marble, containing billions of stars.
A similar idea in a database, where one table column could contain a whole universe of another subset of data, can also expand your unrestrained horizons to help you to see the potential volume of structured (or less structured) information.
I remember back in the early 2000s where an XML column type was introduced to the SQL Server, many battles were thought to discourage such idea of a complex data type within a table, where one of the main arguments was a slow performance to read/write this data.
With JSON data type (or actually a more complex text column, and in SQL Server interpretation it could be defined as VARCHAR(MAX)), I don’t have a desire to start another argument, but just try to imagine how much text data could be stored in a single column of possible 2Gb in size. It is just like a whole database in a single line of a record, isn't this exciting 🙂
Recently, Microsoft Azure Data Factory (ADF) product team delivered a new Parse transformation that can be used both for complex JSON and text delimited data: https://docs.microsoft.com/en-us/azure/data-factory/data-flow-parse. So, I decided before using it in a real project to give it try and test on a simple JSON data set, and that’s why I named my post this way.
The original JSON sample data set has been found here: https://opensource.adobe.com/Spry/samples/data_region/JSONDataSetSample.html
I have already used it in my attempt to expand/flatten/explode a JSON dataset with the help of Flatten data transformation, now it’s time to see what I can do with the Parsing ADF capability: http://datanrg.blogspot.com/2020/03/transforming-json-to-csv-with-help-of.html.

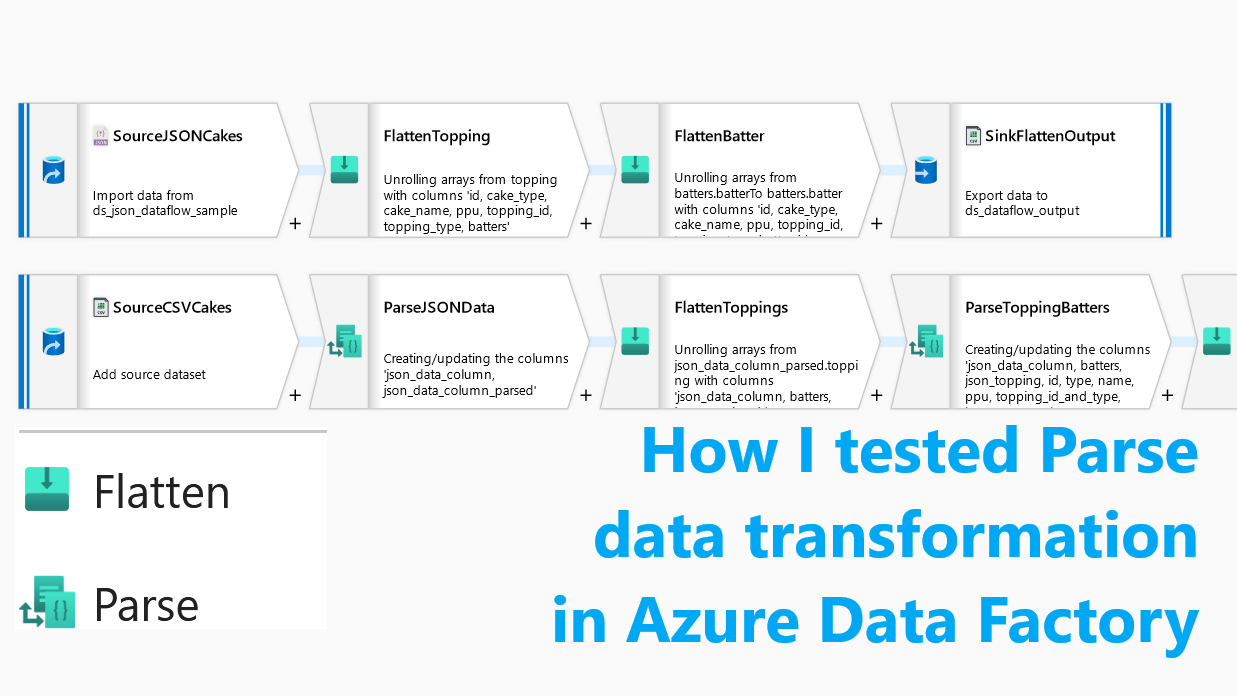
Originally, if a sourcing dataset is interpreted (or presented) for ADF as JSON data, then this dataset could be easily flattened into a table with two steps to (1) Flatten JSON Toppings first and then (2) Flatten more complex JSON Batters data element, as well carrying other regular id, type, name, and ppu data attributes.
When you push your data workload and its dataset is not entirely JSON formatted (e.g. a regular table, with one or more JSON formatted columns), then this new Parse data transformation becomes very practical.
Looking at the same JSON data as a text column we would need to make a few more additional steps: (1) Parse this JSON data column, then (2) expand the Toppings by Flatten transformation, (3) Parse JSON Topping and Batters, (4) Flatten JSON array of batter and then finally (5) Parse the expanded JSON batter set of attributes. It looks easy, let’s see how it works in reality.
(1) Parse JSON data column
Transformation settings
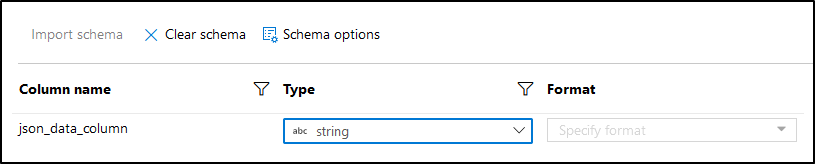

Then in the Parse settings, I have to configure my output column in this way:
Output dataset
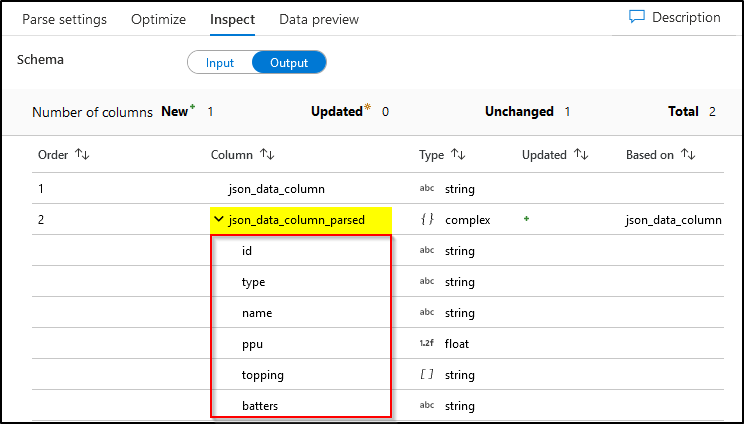
Data Preview

(2) Flatten Toppings
Transformation settings
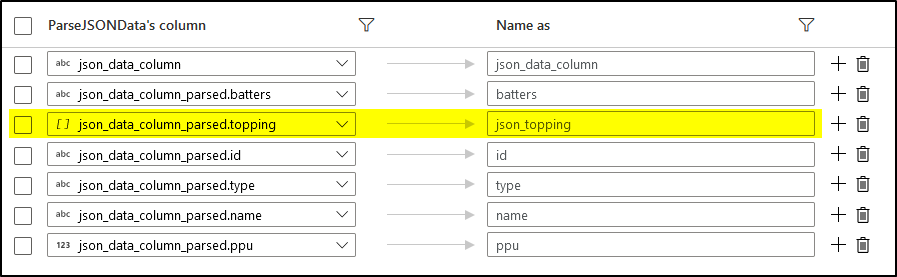
Output dataset
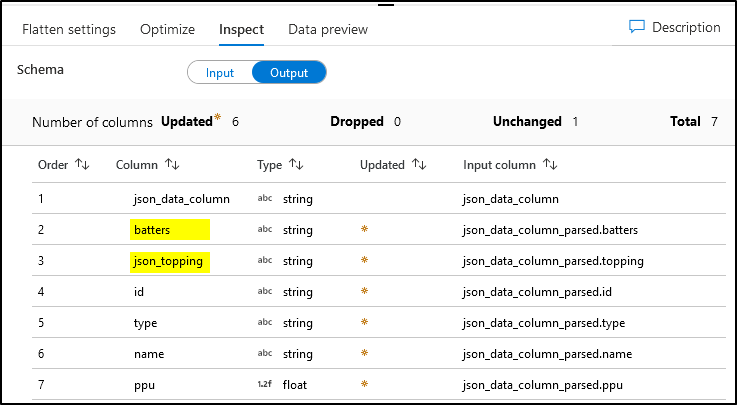
Data Preview
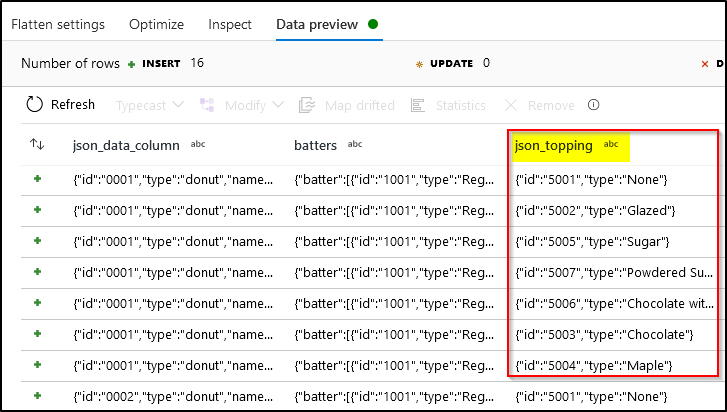
(3) Parse JSON Topping and Batters
Following the expansion (or flattening) of the json_topping, it was quite noticeable that I could use the same Parse transformation to get explicitly extract the id and type of my JSON topping construction. Since the Parse transformation allows me to chose multiple columns, there was nothing wrong to add the extraction of the batter JSON elements from its JSON batters parents as well.
Transformation settings
Output dataset
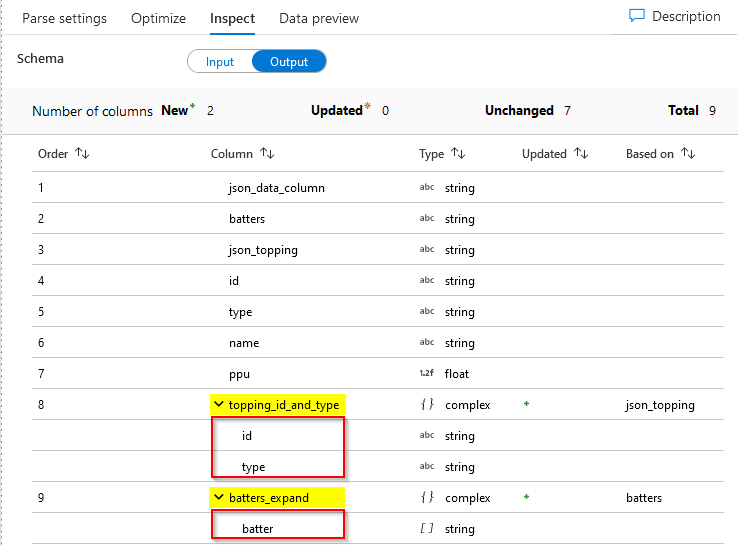
Data Preview
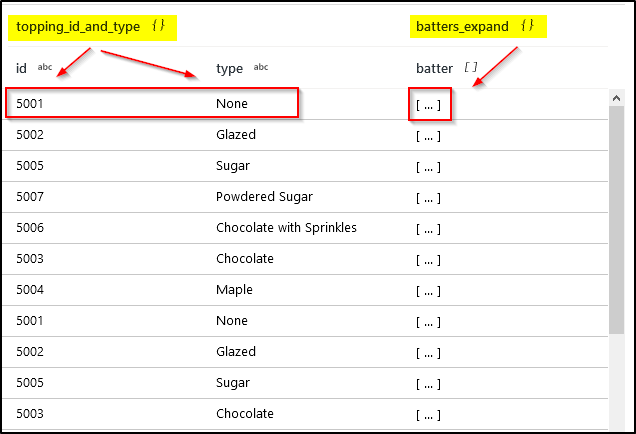
(4) Flatten JSON Batter
Transformation settings
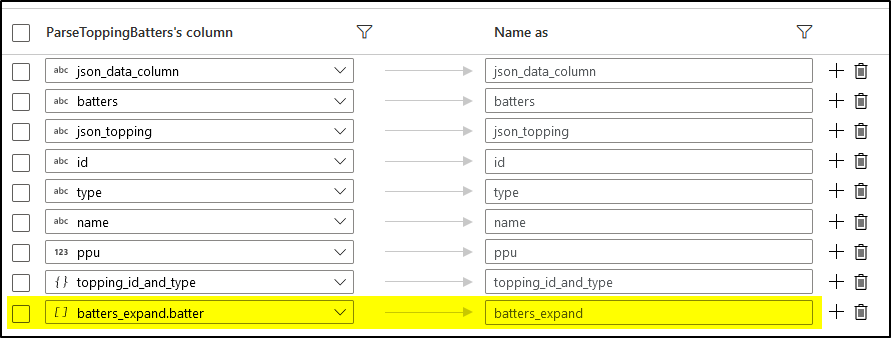
Output dataset
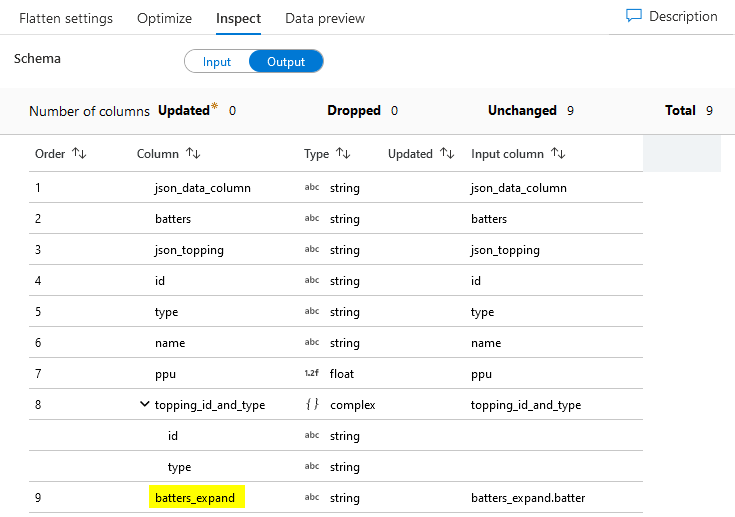
Data Preview
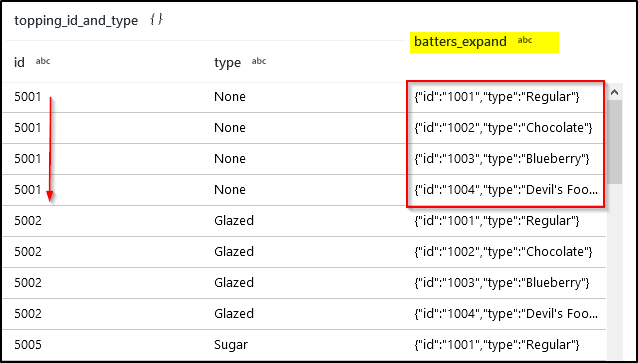
(5) Parse JSON Batter
Transformation settings
Output dataset
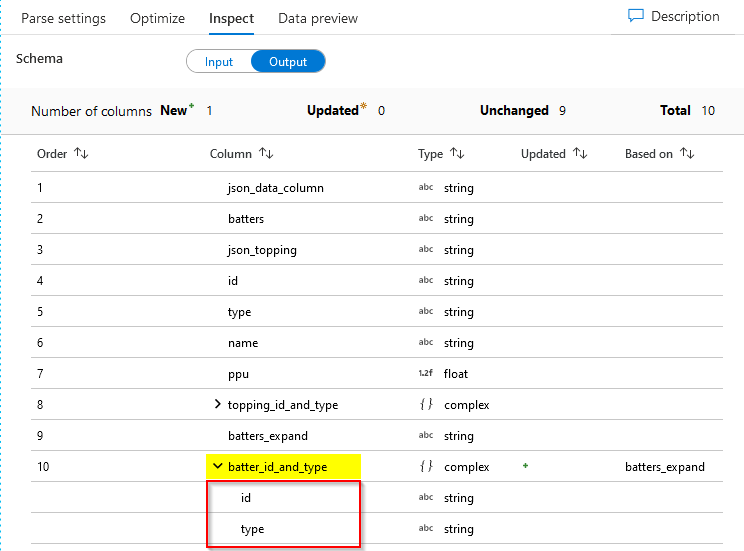
Data Preview
Summary (or things to remind me next time I work with Parse in ADF)
- JSON settings (Single document, Document per line, Array of documents) at each Parse transformation is VERY important to define whether your files contain a single JSON, multiple JSONs in separate lines, or in an array format. I've had multiple errors when this setting wasn't set correctly.
- Not to forget to give different column names at each transformation step (and this is applicable to both Parse & Flatten); I had several Spark error messages when similar sourcing and output columns were colliding with each other.
- It helps to do a data profiling first before parsing it, it will help to plan your transformations steps.
- Sometimes Parsing in ADF was a bit slower than I expected even on a small dataset.
- Will I use Parse in ADF? Yes: it works well with simple JSON elements. Will I use with more complex JSON structure, like arrays? Maybe: I still need to do more testing to see how it works on a large dataset.