

By Steve Bolton
…………“The names statisticians use for non-parametric analyses are misnomers too, in my opinion: Kruskal-Wallis tests and Kolmogorov-Smirnov statistics, for example. Good grief! These analyses are simple applications of parametric modeling that belie their intimidating exotic names.”
Apparently even experts like Will G. Hopkins, the author of the plain English online guide to stats A New View of Statistics, perceive just how dry the subject can be. They feel our pain. Sometimes the topics are simply too difficult to express efficiently without brain-taxing equations and really terse writing, but this is not the case with the Kolmogorov-Smirnov Test, the topic of this week’s mistutorial on how to perform goodness-of-fit tests with SQL Server. This particular test got its lengthy moniker from two Russian mathematicians, Vladimir Smirnov (1887-1974) and Andrey Kolmogorov (1903-1987), the latter of whom is well-known in the field but hardly a household name beyond it.[ii] He made many important contributions to information theory, neural nets and other fields directly related to data mining, which I hope to shed some light on in a future tutorial series, Information Measurement with SQL Server. Among them was Kolmogorov Complexity, a fascinating topic that can be used to embed data mining algorithms more firmly into the use of reason, in order to make inferences based on strict logical necessity. Even more importantly, he was apparently sane – unlike most famous mathematicians and physicists, who as I have noted before tend to be not merely eccentric, but often shockingly degenerate or dangerous, or both.[iii] Despite the imposing name, I was actually looking forward to coding this particular test because Kolmogorov’s work always seems to turn out to be quite useful. I wasn’t disappointed. The concepts aren’t half as hard to grasp as the name is to pronounce, because aside from the usual inscrutable equations (which I almost always omit from these articles after translating them into code) the logic behind it is really common sense. Perhaps best of all, the Kolmogorov-Smirnov Test is hands down the fastest and best-performing goodness-of-fit measure we have yet surveyed in this series. The code I provided for the last few articles was some of the weakest I’ve written in all of my tutorial series, which was compounded by the fact that the tests I surveyed aren’t a good match for SQL Server use cases, but all in all, the T-SQL below for the Kolmogorov-Smirnov is some of the best I’ve written to date. After several rewrites, it now executes on an 11-million-row dataset on a beat-up desktop in less than 30 seconds.
The Benefits of Kolmogorov’s Test
Several studies comparing the various goodness-of-fit tests often rank the Kolmogorov-Smirnov measure near the bottom along with other popular ones like the Chi-Squared Test) because it has lower statistical power (i.e., the ability to detect an effect on a variable when it is actually present) than rivals like the Shapiro-Wilk. As we have seen in previous articles, however, many of these alternate measures are not as well-suited to the use cases the SQL Server community is likely to encounter – particularly the popular Shapiro-Wilk Test, since it can only be applied to very small datasets. Our scenarios are distinctly different from those encountered in the bulk of academic research, since we’re using recordsets of millions or even billions of rows. These datasets are often big enough to reduce the need for random sampling, since they may represent the full population or something close to it. Furthermore, parameters like averages, counts, standard deviations and variances can be instantly calculated for the entire dataset, thereby obviating the need for the complicated statistical techniques often used to estimate them. This advantage forestalls one of the stumbling blocks otherwise associated with the Kolmogorov-Smirnov Test, i.e. the need to fully specify all of the parameters (typically aggregates) for the distribution being tested.[iv]
…………The ideal goodness-of-fit test for our purposes would be one applicable to the widest number of distributions, but many of them are limited to the Gaussian “normal” distribution or bell curve. That is not true of the Kolmogorov-Smirnov Test, which can be applied to any distribution that would have a continuous Content type in SQL Server Data Mining (SSDM). It is also an exact test whose accuracy is not dependent on the number of data points fed into it.[v] I would also count among its advantages the fact that it has clear bounds, between 0 and 1; other statistical tests sometimes continually increase in tandem with the values and counts fed into them and can be difficult to read, once the number of digits of the decimal place exceeds six or seven, thereby requiring users to waste time counting them. As we shall see, there is a lingering interpretation issue with this test, or at least my amateur implementation of it. The test can also be “more sensitive near the center of the distribution than at the tails,” but this inconvenience is heavily outweighed by its many other advantages.
…………Another plus in its favor is the relative ease with which the inner workings can be grasped. End users should always know how to interpret the numbers returned to them, but there is no reason to burden them with the internal calculations and arcane equations; I think most of the instructional materials on math and stats lose their audiences precisely because they bury non-experts under a mountain of internal details that require a lot of skills they don’t have, nor need. End users are like commuters, who don’t need to give a dissertation in automotive engineering in order to drive to work each day; what they should be able to do is read a speedometer correctly. It is the job of programmers to put the ideas of mathematicians and statisticians into practice and make them accessible to end users, in the same way that mechanics are the middlemen between drivers and automotive engineers. It does help, however, if the internal calculations have the minimum possible level of difficulty, so that programmers and end users alike can interpret and troubleshoot the results better; it’s akin to the way many Americans in rural areas become driveway mechanics on weekends, which isn’t possible if the automotive design becomes too complex for them to work on efficiently.
Plugging in CDFs and EDFs
The Kolmogorov-Smirnov Test isn’t trivial to understand, but some end users might find it easier to grasp the inner workings of this particular goodness-of-fit test. The most difficult concept is that of the cumulative distribution function (CDF), which I covered back in Goodness-of-Fit Testing with SQL Server, part 2.1: Implementing Probability Plots in Reporting Services and won’t rehash here. Suffice it to say that all of the probabilities for all of the possible values of a column are arranged so that they accumulate from 0 to 1. The concept is easier to understand than to code, at least for the normal distribution. One of the strongest points of the Kolmogorov-Smirnov Test is that we can plug the CDF of any continuous distribution into it, but I’ll keep things short by simply reusing one of the CDF functions I wrote for the Implementing Probability Plots article.
…………All we have to do to derive the Kolmogorov-Smirnov metric is to add in the concept of the empirical distribution function (EDF), in which we merely put the recordset in the order of the values and assign an EDF value at each point that is equal to the reciprocal of the overall count. Some sources make cautionary statements like this, “Warning: ties should not be present for the Kolmogorov-Smirnov test,”[vi] which would render all of the test based on EDFs useless for our purposes since our billion-row tables are bound to have repeat values. I was fortunate to find a workaround in some undated, uncredited course notes I found at the Penn State University website, which turned out to be the most useful source of info I’ve yet found on implementing EDFs.[vii] To circumvent this issue, all we have to do is use the distinct count for values with ties as the dividend rather than one. Like the CDF, the EDF starts at 0 and accumulates up to a limit of 1, which means they can be easily compared by simply subtracting them at each level. The Kolmogorov-Smirnov test statistic is merely the highest difference between the two.[viii] That’s it. All we’re basically doing is seeing if the order follows the probability we’d expected for each value, if they came from a particular distribution. In fact, we can get two measures for the price of one by using the minimum difference as the test statistic for Kuiper’s Test, which is used sometimes in cases where cyclical variations in the data are an issue.[ix]
Figure 1: T-SQL Code for the Kolmogorov-Smirnov and Kuiper’s Tests
CREATE PROCEDURE [Calculations].[GoodnessOfFitKolomgorovSmirnovAndKuipersTestsSP]
@Database1 as nvarchar(128) = NULL, @Schema1 as nvarchar(128), @Table1 as nvarchar(128),@Column1 AS nvarchar(128), @OrderByCode as tinyint
AS
DECLARE @SchemaAndTable1 nvarchar(400),@SQLString nvarchar(max)
SET @SchemaAndTable1 = @Database1 + ‘.’ + @Schema1 + ‘.’ + @Table1
DECLARE @Mean float,
@StDev float,
@Count float
DECLARE @EDFTable table
(ID bigint IDENTITY (1,1),
Value float,
ValueCount bigint,
EDFValue float,
CDFValue decimal(38,37),
EDFCDFDifference decimal(38,37))
DECLARE @ExecSQLString nvarchar(max), @MeanOUT nvarchar(200),@StDevOUT nvarchar(200),@CountOUT nvarchar(200), @ParameterDefinition nvarchar(max)
SET @ParameterDefinition = ‘@MeanOUT nvarchar(200) OUTPUT,@StDevOUT nvarchar(200) OUTPUT,@CountOUT nvarchar(200) OUTPUT ‘
SET @ExecSQLString = ‘SELECT @MeanOUT = Avg(‘ + @Column1 + ‘),@StDevOUT = StDev(‘ + @Column1 + ‘),@CountOUT = Count(‘ + @Column1 + ‘)
FROM ‘ + @SchemaAndTable1 + ‘
WHERE ‘ + @Column1 + ‘ IS NOT NULL’
EXEC sp_executesql @ExecSQLString,@ParameterDefinition, @MeanOUT = @Mean OUTPUT,@StDevOUT = @StDev OUTPUT,@CountOUT = @Count OUTPUT
SET @SQLString = ‘SELECT Value, ValueCount, SUM(ValueCount) OVER (ORDER BY Value ASC) / CAST(‘ +
CAST(@Count as nvarchar(50)) + ‘AS float) AS EDFValue
FROM (SELECT DISTINCT ‘ + @Column1 + ‘ AS Value, Count(‘ + @Column1 + ‘) OVER (PARTITION BY ‘ + @Column1 + ‘ ORDER BY ‘ + @Column1 + ‘) AS ValueCount
FROM ‘ + @SchemaAndTable1 + ‘
WHERE ‘ + @Column1 + ‘ IS NOT NULL) AS T1‘
INSERT INTO @EDFTable
(Value, ValueCount, EDFValue)
EXEC (@SQLString)
UPDATE T1
SET CDFValue = T3.CDFValue, EDFCDFDifference = EDFValue – T3.CDFValue
FROM @EDFTable AS T1
INNER JOIN (SELECT DistinctValue, Calculations.NormalDistributionSingleCDFFunction (DistinctValue, @Mean, @StDev) AS CDFValue
FROM (SELECT DISTINCT Value AS DistinctValue
FROM @EDFTable) AS T2) AS T3
ON T1.Value = T3.DistinctValue
SELECT KolomgorovSmirnovSupremum AS KolomgorovSmirnovTest, KolomgorovSmirnovSupremum – KolomgorovSmirnovMinimum AS KuipersTest
FROM (SELECT Max(ABS(EDFValue – CDFValue)) AS KolomgorovSmirnovSupremum, — the supremum i.e. max
Min(ABS(EDFValue – CDFValue)) AS KolomgorovSmirnovMinimum
FROM @EDFTable
WHERE EDFCDFDifference > 0) AS T3
SELECT ID, Value, ValueCount, EDFValue, CDFValue, EDFCDFDifference
FROM @EDFTable
ORDER BY CASE WHEN @OrderByCode = 1 THEN ID END ASC,
CASE WHEN @OrderByCode = 2 THEN ID END DESC,
CASE WHEN @OrderByCode = 3 THEN Value END ASC,
CASE WHEN @OrderByCode = 4 THEN Value END DESC,
CASE WHEN @OrderByCode = 5 THEN ValueCount END ASC,
CASE WHEN @OrderByCode = 6 THEN ValueCount END DESC,
CASE WHEN @OrderByCode = 7 THEN EDFValue END ASC,
CASE WHEN @OrderByCode = 8 THEN EDFValue END DESC,
CASE WHEN @OrderByCode = 9 THEN CDFValue END ASC,
CASE WHEN @OrderByCode = 10 THEN CDFValue END DESC,
CASE WHEN @OrderByCode = 11 THEN EDFCDFDifference END ASC,
CASE WHEN @OrderByCode = 12 THEN EDFCDFDifference END DESC
…………The code above is actually a lot simpler than it looks, given that the last 12 lines are dedicated to implementing the @OrderByCode parameter, which I’ve occasionally provided as an affordance over the course of the last two tutorial series. It’s particularly useful in this test when the column values, distinct counts EDF and CDF results in the @EDFTable are of interest in addition to the test statistic; ordinarily, this would be taken care of in an app’s presentation layer, so the ordering code can be safely deleted if you’re not using SQL Server Management Studio (SSMS). In this instance, 1 orders the results by ID ASC, 2 is by ID Desc, 3 is by Value ASC, 4 is by Value DESC, 5 is by ValueCount ASC, 6 is by ValueCount DESC, 7 is by EDFValue ASC, 9 is by EDFValue Desc, 9 is by CDFValue ASC, 10 is by CDFValue DESC, 11 is by EDFCDFDifference ASC and 12 is by EDFCDFDifference DESC. The rest of the parameters and first couple of line of dynamic SQL allow users to perform the tests against any column in any database they have sufficient access to. As usual, you’ll have to add in your own validation, null handling and SQL injection protection code. Two dynamic SQL statements are necessary because separate count, mean and standard deviation have to be extracted from the original base table. The retrieval of those aggregates needed for subsequent calculations occurs shortly after the declarations section.
…………Note that this procedure was markedly faster after substituting the sp_executesql statement for a dynamic INSERT EXEC on the base table (which had been used to populate the @EDFTable in an inefficient way). One quirk I should point out though is the use of the DISTINCT clause in the UPDATE subquery, which is needed to prevent unnecessary repetitive calls to the somewhat expensive Calculations.NormalDistributionSingleCDFFunction in the case of duplicate values. This somewhat convoluted method actually save a big performance hit on large tables with lots of duplicates. In the final query, I bet that the outer subquery would be less expensive than retrieving the max twice in a single query. One of the few concerns I have about the procedure is the use of the actual mean and standard deviation in calculating the CDF values. Some sources recommended using the standard normal, but this typically resulted in ridiculous distortions for most of the recordsets I tested them against. On the other hand, I verified the correctness of the calculations as they stand now by working through the example in the Alion System Reliability Center’s Selected Topics in Assurance Related Technologies, a series of publications on stats I recently discovered and now can’t live without.[x]
Figure 2: Sample Results from the Kolmogorov-Smirnov and Kuiper’s Tests
EXEC Calculations.GoodnessOfFitKolomgorovSmirnovAndKuipersTestsSP
@Database1 = N’DataMiningProjects’,
@Schema1 = N’Health’,
@Table1 = N’DuchennesTable’,
@Column1 = N’LactateDehydrogenase’,
@OrderByCode = 1
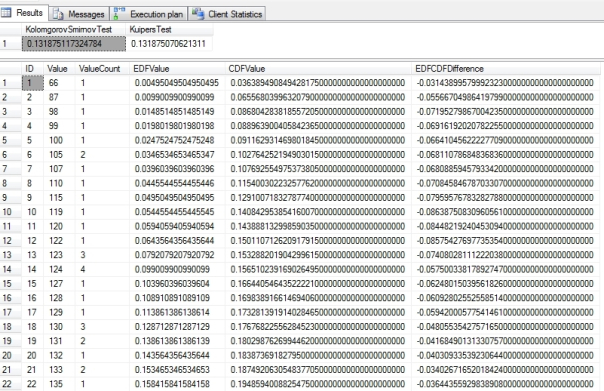
…………Even more good news: when I tested it on the 209 rows of the tiny 9-kilobyte set of data on the Duchennes muscular dystrophy and the 11 million rows and near 6 gigs of data in the Higgs Boson dataset (which I downloaded from the Vanderbilt University’s Department of Biostatistics and University of California at Irvine’s Machine Learning Repository respectively) I got pretty much the results I expected. After using the same datasets for the last dozen articles or so, I know which ones follow the Gaussian distribution and which do not, and the Kolmogorov-Smirnov Test consistently returned lower figures for the ones that followed a bell curve and higher ones for those that do not. For example, the query in Figure 2 returned a value of 0.131875117324784 for the LactateDehydrogenase enzyme, while the less abnormal Hemopexin scored a 0.0607407215998911. On the other hand, the highly abnormal, really lopsided first float column in the Higgs Boson dataset scored a whopping 0.276266847552121, while the second float column scored just a 0.0181892303151281 probably because it clearly follows a bell curve in a histogram.
…………Other programmers may also want to consider adding in their own logic to implement confidence intervals and the like, which I typically omit for reasons of simplicity, the difficulty of deriving lookup values on a Big Data scale and philosophical concerns about their applicability, not to mention the widespread concern among many professional statisticians about the rampant misuse and misinterpretation of hypothesis testing methods. Suffice it to say that my own interval of confidence in them is steadily narrowing, at least for the unique use cases the SQL Server community faces. The good news is that if you decide to use standard hypothesis testing methods, then the Kolmogorov-Smirnov test statistic doesn’t require modifications before plugging it into lookup tables, unlike the popular Shapiro-Wilk and Anderson-Darling tests.[xi]
Figure 3: Execution Plan for the Kolmogorov-Smirnov and Kuiper’s Procedure (click to enlarge)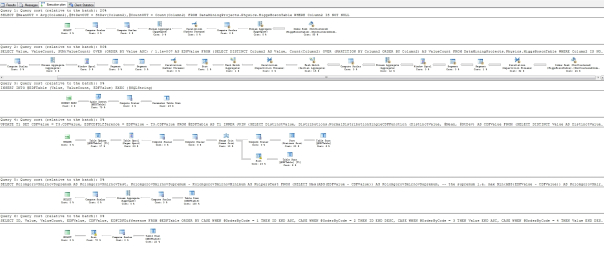
…………When all is said and done, the Kolmogorov-Smirnov Test is the closest thing to the ideal goodness-of-fit measure for our use cases. It may have low statistical power, but it can handle big datasets and a wide range of distributions. The internals are a shorter to code and moderately easier to explain to end users than those of some other procedures and the final test statistic is easy to read because it has clear bounds. It also comes with some freebies, like the ability to simultaneously calculate Kuiper’s Test at virtually no extra cost. For most columns I tested there wasn’t much of a difference between the Kolmogorov-Smirnov and Kuiper’s Test results till we got down to the second through fifth decimal places, but there’s no reason not to calculate it if the costs are dwarfed by those incurred by the rest of the procedure. Note that I also return the full @EDFTable, including the ValueCount for each distinct Value, since there’s no point in discarding all that information once the burden of computing it all has been borne. One of the few remaining concerns I have about the test is that much of this information may be wasted in the final test statistics, since merely taking minimums and maximums is often an inefficient way of making inferences about a dataset. This means that more useful, expanded versions of the tests might be possible by calculating more sophisticated measures on the same EDF and CDF data.
…………Best of all, the test outperforms any of the others we’ve used in the last two tutorial series. After eliminating most of the dynamic SQL I overused in previous articles, the execution time actually worsened, till I experimented with some different execution plans. On the first float column in the 11-million-row, 6-gig Higgs Boson dataset, the procedure return in just 24 seconds, but for the equally-sized second float column, in returned in an average of just 29. That’s not shabby at all for such a useful statistical test on such a huge dataset, on a clunker of a desktop that’s held together with duct tape. I can’t account for that difference, given that the execution plans were identical and the two columns share the same data type and count; the only significant difference I know of is that one is highly abnormal and the other follows a bell curve. For smaller datasets of a few thousand rows the test was almost instantaneous. I don’t think the execution plan in Figure 3 can be improved upon much, given that just two of the five queries account for practically all of the cost and both of them begin with Index Seeks. In the case of the first, that initial Seek accounts for 92 percent of the cost. The second ought to be the target of any optimization efforts, since it accounts for 85 percent of the batch; within it, however, the only operators that might be worth experimenting with are the Hash Match (Aggregate) and the Sort. Besides, the procedure already performs well enough as it is and should be practically instantly on a real database server. In the next installment, we’ll see whether the Lilliefors Test, another measure based on the EDF, can compete with the Kolmogorov-Smirnov Test, which is thus far the most promising measure of fit we’ve yet covered in the series.
See Hopkins, 2014, “Rank Transformation: Non-Parametric Models,” published at the A New View of Statistics webpage http://www.sportsci.org/resource/stats/nonparms.html
[ii] See the Wikipedia pages “Andrey Kolmogorov” and “Vladimir Smirnov” at http://en.wikipedia.org/wiki/Andrey_Kolmogorov and http://en.wikipedia.org/wiki/Vladimir_Smirnov_(mathematician) respectively.
[iii] I’m slowly compiling a list of the crazy ones and their bizarre antics for a future editorial or whatever – which will include such cases as Rene Descartes’ charming habit of carrying a dummy of his dead sister around Europe and carrying on conversations with it in public. I’m sure there’ll also be room for Kurt Gödel, who had a bizarre fear of being poisoned – so he forced his wife to serve as his food-taster. Nothing says romance like putting the love of your life in harm’s way when you think people are out to get you. When she was hospitalized, he ended up starving to death. Such tales are the norm among the great names in these fields, which is why I’m glad I deliberately decided back in fifth grade not to pursue my fascination with particle physics.
[iv] See National Institute for Standards and Technology, 2014, “1.3.5.16 Kolmogorov-Smirnov Goodness-of-Fit Test,” published in the online edition of the Engineering Statistics Handbook. Available at http://www.itl.nist.gov/div898/handbook/eda/section3/eda35g.htm
[v] IBID.
[vi] p. 14, Hofmann, Heike, 2013, “Nonparametric Inference and Bootstrap { Q-Q plots; Kolmogorov Test,” lecture notes published Oct. 11, 2013 at the Iowa State University web address http://www.public.iastate.edu/~hofmann/stat415/lectures/07-qqplots.pdf
[vii] Penn State University, 2014, “Empirical Distribution Functions,” undated course notes posted at the Penn State University website and retrieved Nov. 5, 2014 from the web address https://onlinecourses.science.psu.edu/stat414/node/333
[viii] I also consulted the Wikipedia page “Kolmogorov-Smirnov Test” at http://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test for some of these calculations.
[ix] See the Wikipedia article “Kuiper’s Test” at http://en.wikipedia.org/wiki/Kuiper’s_test
[x] See Alion System Reliability Center, 2014, “Kolmogorov-Simirnov: A Goodness of Fit Test for Small Samples,” published in Selected Topics in Assurance Related Technologies, Vol. 10, No. 6. Available online at the Alion System Reliability Center web address
https://src.alionscience.com/pdf/K_STest.pdf
[xi] “Critical value beyond which the hypothesis is rejected in Anderson-Darling test is different when Gaussian pattern is being tested than when another distribution such a lognormal is being tested. Shapiro-Wilk critical value also depends on the distribution under test. But Kolmogorov-Smirnov test is distribution-free as the critical values do not depend on whether Gaussianity is being tested or some other form. No author listed, 2014, “Checking Gaussianity,” published online at the MedicalBiostatistics.com web address http://www.medicalbiostatistics.com/checkinggaussianity.pdf

![]()
