

In today’s blog I will attempt to challenge the popularly held notion that LIKE “%string%” wildcard searches must be slow (Sargability: Why %string% Is Slow).
A Sample Table Populated with 10 Million Rows of Test Data
In order to do this, we’ll need a large table of test data with a composite PRIMARY KEY to demonstrate various aspects of the issue.
CREATE TABLE dbo.TestLIKESearches
(
ID1 INT
,ID2 INT
,AString VARCHAR(100)
,Value INT
,PRIMARY KEY (ID1, ID2)
);
WITH Tally (n) AS
(
SELECT TOP 10000000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a CROSS JOIN sys.all_columns b
)
INSERT INTO dbo.TestLIKESearches
(ID1, ID2, AString, Value)
SELECT 1+n/500, n%500
,CASE WHEN n%500 > 299 THEN
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
RIGHT(1000+n%1000, 3) +
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('abcdefghijklmnopqrstuvwxyz', 1+ABS(CHECKSUM(NEWID()))%26, 1)
END
,1+ABS(CHECKSUM(NEWID()))%100
FROM Tally;
While we have set the AString column to contain some NULL values (60% in fact), what we are about to show works even when 0% of the rows are NULL. Let’s start by showing the non-SARGable version of the query and its corresponding actual execution plan.
SELECT ID1, ID2, AString FROM dbo.TestLIKESearches WHERE AString LIKE '%21%';
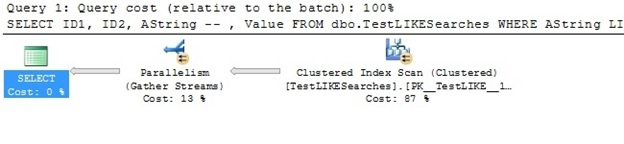
As expected, the non-SARGable query results in a Clustered Index SCAN on the table. Let’s see if we can affect this by adding the following INDEX.
CREATE INDEX tls_ix1 ON dbo.TestLIKESearches(AString);
When we check the execution plan again for the same query, it now looks like this:
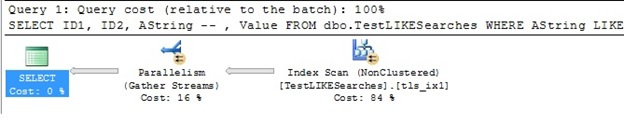
The query is now using the NONCLUSTERED INDEX, but it is still doing a SCAN. So let’s try a slightly different form of the same query, one which we know must generate the exact same results.
SELECT ID1, ID2, AString FROM dbo.TestLikeSearches WHERE AString IS NOT NULL AND AString LIKE '%21%';
All we have done is to modify the filter in the WHERE clause to ignore NULL values, none of which could contain our search string anyway. Now our execution plan looks like this:
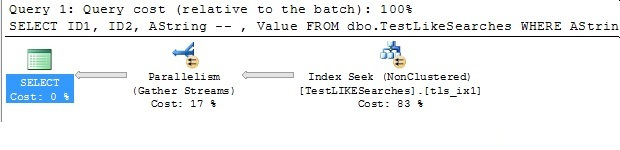
Since a SEEK should in theory be better than a SCAN, we’re hopeful that the query’s speed (elapsed time) is improved also, but we’ll get to that in a moment.
The same small change to an UPDATE converts the INDEX SCAN to a SEEK, as demonstrated by the two queries below.
UPDATE dbo.TestLIKESearches SET Value = 300 WHERE AString LIKE '%21%'; UPDATE dbo.TestLIKESearches SET Value = 400 WHERE AString IS NOT NULL AND AString LIKE '%21%';

On a SELECT however, we can show just how easily this SEEK can be broken. Let’s modify our query to also return the Value column.
SELECT ID1, ID2, AString, Value FROM dbo.TestLikeSearches WHERE AString IS NOT NULL AND AString LIKE '%21%';
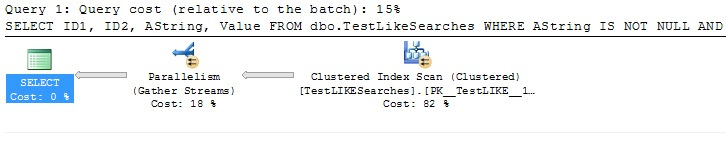
By adding Value into the returned results, we have broken the SEEK; it has reverted to a SCAN.
But there is a way around this. We can use a query hint (FORCESEEK) to restore our INDEX SEEK.
SELECT ID1, ID2, AString, Value FROM dbo.TestLikeSearches WITH(FORCESEEK) WHERE AString IS NOT NULL AND AString LIKE '%21%';
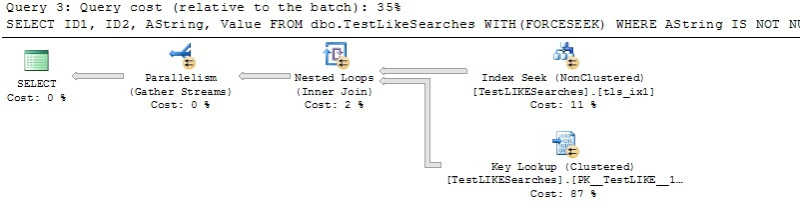
Performance Comparison of SCAN vs. SEEK for a LIKE “%string%” Search
The following table summarizes the performance results we got from this method of getting SQL Server to SEEK the INDEX on our string column during the LIKE “%string%” search.
| Logical Reads | CPU | Elapsed Time | |
| Base SELECT Query Without INDEX | 33193 | 2246 | 628 |
| Base SELECT Query With INDEX | 24169 | 2310 | 582 |
| Improved SELECT Query (INDEX SEEK) | 13659 | 1513 | 405 |
| Improvement | 43% | 35% | 30% |
| Base UPDATE Query With INDEX | 146678 | 2434 | 812 |
| Improved UPDATE Query (INDEX SEEK) | 136168 | 1763 | 546 |
| Improvement | 7% | 28% | 33% |
| SELECT with Value (INDEX SCAN) | 33193 | 2620 | 665 |
| SELECT with Value (FORCESEEK) | 136193 | 1794 | 455 |
| Improvement | -310% | 32% | 32% |
In all cases, by forcing the SEEK (even when it results in an added Key Lookup) we were able to improve elapsed and CPU times to a measurable degree. Only the FORCESEEK query hint on the SELECT when non-indexed columns are included actually increased the logical IO count (albeit by quite a bit).
Conclusion
Despite the commonly accepted belief that a LIKE “%string%” search is limited to an INDEX SCAN, we have proven that it is possible to make it happen with a properly constructed non-clustered INDEX on the string being searched.
The SEEK is easily obtained for either SELECT or UPDATE, and probably DELETE and/or MERGE as well (although we didn’t test these cases) with just a small additional filtering criteria (excluding NULLs).
The SEEK can also just as easily be broken by including columns in the SELECT that aren’t in our non-clustered INDEX, however even then using a FORCESEEK query hint can restore it.
You’ll be able to read more about the results of this technique and how well it improves performance against a wider range of NULL values in an upcoming article that I have submitted to http://www.sqlservercentral.com/. You can generally expect that as the percentage of NULL values decreases, the performance gain will not be as much.
Follow me on Twitter: @DwainCSQL
Copyright © Dwain Camps 2014 All Rights Reserved

![]()
