

This week’s blog post is rather simple. One of the main characteristics of a data set involving classes, or discrete variables – are frequencies. The number of times each data element or class is observed is called its frequency. A table that displays the discrete variable and number of times it occurs in the data set is called a ‘Frequency Table’.A frequency table usually has frequency, percent or relative frequency expressed in % (the percentage of occurrences), cumulative frequency – the number of times all the preceding values have occurred and Cumulative Relative Frequency which is the ratio of cumulative frequency to size of sample (this can also be expressed as a percent if so desired).
For creating this I used the same data set I used for studying Simpson’s Paradox
To remember that variables we are deriving frequency for should be DISCRETE in nature and each instance of the variable should be related/comparable to another in some way. If we are interested in cumulative values – those should make some kind of sense..so just summing all records before a name, or before a product(even though those classify as discrete), may not really make sense in most situations .In this case my variable is the age cohort, so summing whatever is below a certain age cohort can be useful data.
My TSQL for this is as below:
DECLARE @totalcount numeric(18, 2) SELECT @totalcount = COUNT(*) FROM [dbo].[paradox_data] ;WITH agecte AS ( SELECT [agecohort], c = COUNT(agecohort) FROM [dbo].[paradox_data] GROUP BY [AgeCohort] ) SELECT agecte.[agecohort], c as frequency,(agecte.c/@totalcount)*100 AS [percent], cumulativefrequency = SUM(c) OVER (ORDER BY [agecohort] ROWS UNBOUNDED PRECEDING), cumulativepercent = ((SUM(c) OVER (ORDER BY [agecohort] ROWS UNBOUNDED PRECEDING))/@totalcount)*100 FROM agecte ORDER BY agecte.[agecohort];
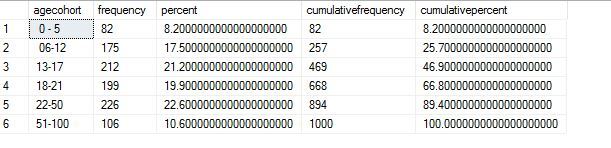
My results are as below. I have 1000 records in the table. This tells me that I have 82 occurences of age cohort 0-5, 8.2% of my dataset is from this bracket, 82 again is the cumulative frequency since this is the first record and 8.2 cumulative percent. For the next bracket 06-12 I have 175 occurences, 17.5 %, 257 occurences of age below 12, and 25.7 % of my data is in this age bracket. And so on.
Let us try the same thing with R. As it is with most R code, part of this is already written in a neat little function here. I did however, find some issues with this code and had to modify it. The main issue was that the function was calculating ‘length’ of the dataframe (in sql terms – number of records) from the variable – and R kept returning a value of ‘1’. The correct way to calculate number of records is to specify the field name after the dataframe, so when I did that it was able to get to the total number of records. This is a little nuance/trick with R that gets many sql people confused, and was happy to have figured it out. I do not know of a ‘macro’ or a generalised function that can pull this value so I had to stick it to the function. It will be different if you use another field for sure. The modified function and value it returns is as below.
##This is my code to initiate R and bring in the dataset
install.packages("RODBC")
library(RODBC)
cn <- odbcDriverConnect(connection="Driver={SQL Server Native Client 11.0};server=MALATH-PC\\SQL01;database=paradox_data;Uid=sa;Pwd=mypwd")data <- sqlQuery(cn, 'select agecohort from [dbo].[paradox_data]')
make_freq_table <- function( lcl_list )
{
## This function will create a frequency table for
## the one variable sent to it where that
## table gives the items, the frequency, the relative
## frequeny, the cumulative frequency, the relative
## cumulative frequency
## The actual result of this function is a data frame
## holding that table.
lcl_freq <- table( lcl_list )
##had to change this from original code to pull correct length.
lcl_size <- length( lcl_list$agecohort )
lcl_df <- data.frame( lcl_freq )
names( lcl_df ) <- c("Items","Freq")
lcl_values <- as.numeric( lcl_freq )
lcl_df$rel_freq_percent <- (lcl_values / lcl_size)*100
lcl_df$cumul_freq <- cumsum( lcl_values )
lcl_df$rel_cumul_freq_percent <- (cumsum( lcl_values ) / lcl_size)*100
lcl_df
}
make_freq_table(data)
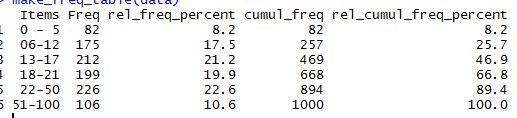
The result I get is as below and is the same as what I got with T-SQL.
Since this is a rather simple example that is 100 percent do-able in TSQL – I did not find the need to do it by calling R from within it. It did help me learn some nuances about R though.
Thanks for reading.

![]()
