

I was presenting a session on how to read execution plans when I received a question: Do you have a specific example of how you can use the query hash to identify similar query plans. I do, but I couldn’t show it right then, so the person asking requested this blog post.
If you’re dealing with lots of application generated, dynamic or ad hoc T-SQL queries, then attempting to determine tuning opportunities, missing indexes, incorrect structures, etc., becomes much more difficult because you don’t have a single place to go to see what’s happening. Each ad hoc query looks different… or do they. Introduced in SQL Server 2008 and available in the standard Dynamic Management Objects (DMO), we have a mechanism to identify ad hoc queries that are similar in structure through the query hash.
Query hash values are available in the following DMOs: sys.dm_exec_requests and sys.dm_exec_query_stats. Those two cover pretty much everything you need, what’s executing right now, what has recently executed (well, what is still in cache that was recently executed, if a query isn’t in cache, you won’t see it). The query hash value itself is nothing other than the output from a hash mechanism. A hash is a formula that outputs a value based on input. For the same, or similar, input, you get the same value. There’s also a query_plan_hash value that’s a hash of the execution plan.
Let’s see this in action. Here is a query:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'Flat%';And if I modify it just a little, like you might with dynamically generated code:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'HL%';What I’ve got is essentially the same query. Yes, if I were to parameterize that WHERE clause by creating a stored procedure or a parameterized query it would be identical, but in this case it is not. In the strictest terms, those are two different strings. But, they both hash to the same value: 0x5A5A6D8B2DA72E25. But, here’s where it gets fun. The first query returns no rows at all, but the second returns 8,534. They have identical query hash values, but utterly different execution plans:
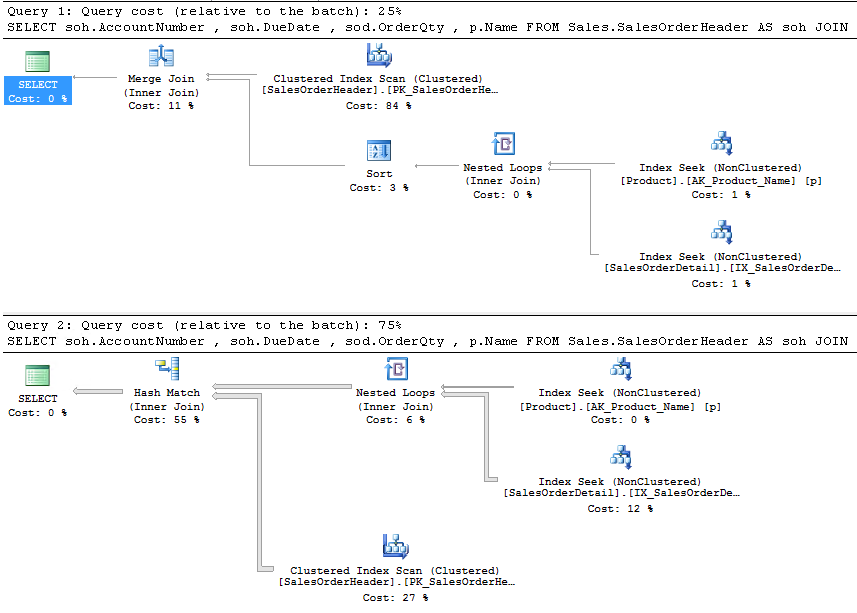
Now, how to use this? First, let’s say you’re looking at the second execution plan. You note the scan of the SalesOrderHeader clustered index and decide you might want to add an index here, but you’re unsure of how many other queries behave like this one. You first look at the properties of the SELECT operator. That actually contains the query hash value. You get that value and plug it into a query something like this:
SELECT deqs.query_hash ,
deqs.query_plan_hash ,
deqp.query_plan ,
dest.text
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp
CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest
WHERE deqs.query_hash = 0x5A5A6D8B2DA72E25;This resulted in eight rows. Yeah, eight. Because I had run this same query different times in different ways, in combinations, so that the query hash, which is generated on each statement, is common, but there were all different sorts of plans and issues. But, a common thread running through them all, a scan on the clustered index as the most expensive operator. So, now that I can identify lots of different common access paths, all of which have a common problem, I can propose a solution that will help out in multiple locations.
The problem with this is, what if I modify the query like this:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name,
p.Color
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'HL%';Despite the fact that this query has an identical query plan to the one above, the hash value, because of the added p.Color column, is now 0xABB5AFDC5A4A6988. But, worth noting, the query_plan_hash values for both these queries are the same, so you can do the same search for common plans with different queries to identify potential tuning opportunities.
So, the ability to pull this information is not a magic bullet that will help you solve all your ad hoc and dynamic T-SQL issues. It’s just another tool in the tool box.
For things like this and a whole lot more, let’s get together in November, 2013 at the all day pre-conference seminar at SQL Saturday Dallas.
UPDATE: In the text I had incorrectly said this was introduced in 2005. It was 2008. I’ve updated it and added this little footnote. Sorry for any confusion.
![]()
