(2021-Nov-30) I heard a story about a young person who was asked why she was always cutting a small piece of meat and putting it aside before cooking a larger one. She answered that this was the usual way at her home when she was growing up and she didn’t really know why. Only after checking with her older relatives, she had discovered the true reason for cutting that small piece away: her grandmother’s cutting board was too small for a regular size meat piece and she wanted to fit it on the board while preparing a meal.

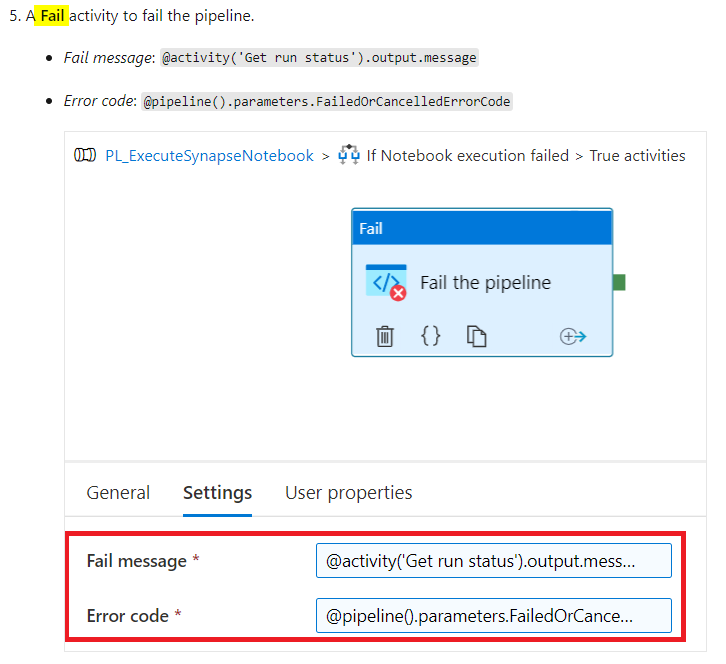
Recently, Microsoft introduced a new Fail activity (https://docs.microsoft.com/en-us/azure/data-factory/control-flow-fail-activity) in the Azure Data Factory (ADF) and I wondered about a reason to fail a pipeline in ADF when my internal being tries very hard to make the pipelines successful once and for all. Yes, I understand a documented explanation that this activity can help to “customize both its error message and error code”, but why?
Internal Conditions
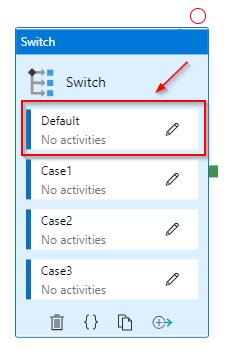
When I work with Switch activity in ADF, which allows me to branch out a control flow to multiple streams, a Default case always puzzles me. You either define all your explicit Cases and let the Default case cover all non-defined anomalies, or you can be bold enough to define all Cases but one and let that last one fall into the Default case, which doesn’t sound very stable. So, in my case, I can add a Fail activity to the Switch Default case, but it still doesn’t feel right.
External Conditions
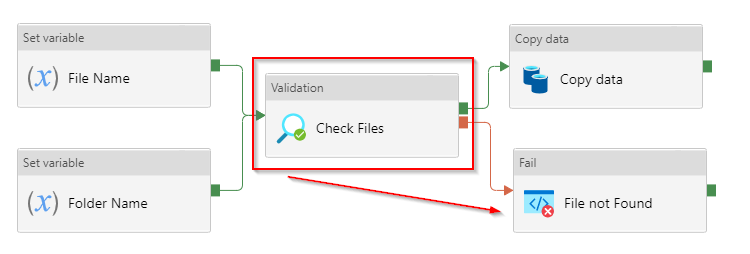
Also, I was reading about other people defining their intention to Fail a pipeline in ADF when certain files are not available or because of other file-based malfunction. I believe that Validation ADF activity is still very underrated, which is very powerful to regulate your pipeline control flow based on absence or availability files/folders. Plus, if you can wisely control the Timeout and Retry settings of similar activities, that will help you not to fail but gracefully exit your pipeline workflow if something bad happens.
Successfully Failed External Activity