

1) A client who experienced a problem on Thursday and waited until Friday evening to report it, even though the problem was "critical" enough to ask us to work on it all weekend if we couldn't solve it.
2) A co-worker who got locked out of the client machine, thereby getting me involved.
3) A relatively obscure error message that I hadn't seen before.
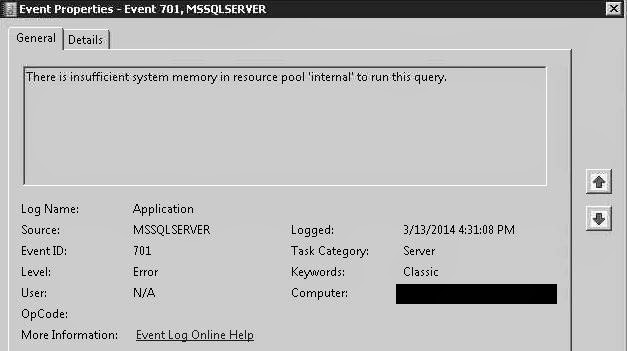


Looking at the MEMORYSTATUS dumps in the ErrorLogs I had available, I saw that the only unusual values were very large "Pages Allocated" values for the MEMORYCLERK_XE.
This behavior (let's reboot - reboot always fixes it!) resulted in the SQL Server Error Logs having been cycled out so that I couldn't see the original log from the original failure.
--
BEGIN RANT
Every SQL Server should be set up to retain more than the default six logs - there are too many situations (like the one I am describing here) where six restarts (and therefore six historical logs) just isn't good enough.

Best case is to set the retention to 40-50 logs *and* to create a SQL Server Agent job to run sp_cycle_errorlog on a nightly basis (say at 11:59:59 or 12:00:01 every night) which generates a new log every day. In most scenarios this will give you just over a month's error logs, and in a scenario such as this one, it will give multiple days' logs *and* allow for multiple MSSQLServer service restarts.
Even if you can't/don't want to implement the daily cycle job, you should definitely increase the retention to some larger number, such as 15 or 20 - the log files are relatively small text files, and even if your SQL service doesn't restart regularly (because you don't apply Windows patches, etc., in which case that is a different rant) the files don't get that large. (They can be unwieldy to open in the log viewer, but they aren't that large that they fill your disk.)
END RANT
--
Without the SQL Server Error Log from the time of the original failure, I went into the Windows Application and System Logs and the SQL Server Default Trace trying to find anything else of value. Unfortunately the only other item was one that I saw in the available logs, "Failed Allocate Pages: FAIL_PAGE_ALLOCATION 1" which unfortunately didn't tell me anything else other than the failure was related to a Single Page Allocation (1) rather than a Multi-Page Allocation.
Possible scenarios I was able to rule out at this point:
1) SQL Server 2012 SP1 Memory Leak - Fixed by 2012SP1CU2, and they were already at 2012SP1CU8
2) Service Broker Misconfiguration - Service Broker was not enabled.
Having exhausted my Google-Fu, I turned to my next avenue - #sqlhelp on Twitter:


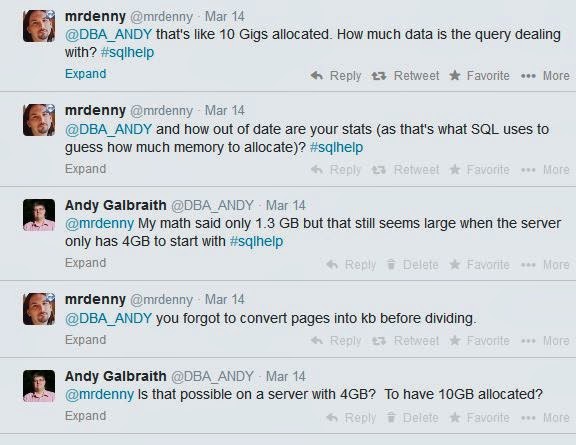
Trying to mitigate the issue, I recommended that the client increase the memory on their VM. (IMPORTANT NOTE - this was not in any way a VM vs. physical server issue!) The client increased the memory from 4GB to 12GB and I set the Max Server Memory to 11000MB (too high for long-term but set there to test against the 1409032 pages shown in the Tweet above), monitored the situation for another 30 minutes, and tried to go to bed, planning to review the situation in the morning.
No Good.
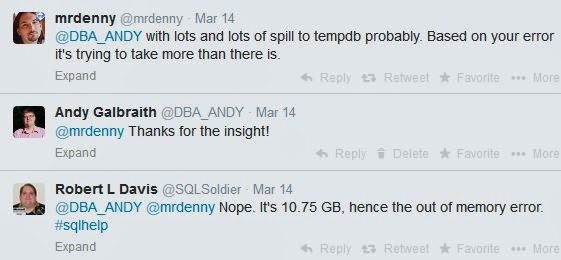
Pages came in overnight and when I got online I found a tweet that provided a whole new insight on the situation:

That made me pause and consider something that I hadn't thought about - in all of my Googling of the various problems earlier in the evening, I hadn't considered *which* memory clerk (MEMORYCLERK_XE) was complaining.
I checked the Extended Events section of Management Studio, and sure enough, their was a user-defined Extended Events session named "Locks" alongside the default system health session.
I checked the XE sessions DMV and found that the Locks session was almost as large as the system health session:
SELECT name, total_buffer_size
FROM sys.dm_xe_sessions
I opened the properties of the Locks session and not being an XE person myself took the most obvious route (for me anyway) - I started comparing it to the default system health session properties to see what was different - and then it hit me.
The system health session writes to a ring buffer (memory) and an eventfile (disk). The ring buffer target is a memory target and the eventfile target persists the completed buffers to disk.
The user-defined Locks session was set up to write to a ring buffer (OK - or so I thought) and a histogram (hmm) but not to an event file. I looked up the histogram and found that it too was a memory target. So the session was set up to write to memory and memory, and I have a memory problem...I see.
To investigate further I scripted out the two sessions and looked at the definitions of the targets. For the system health session:
ADD TARGET package0.event_file(SET filename=N'system_health.xel',max_file_size=(5),max_rollover_files=(4)),
ADD TARGET package0.ring_buffer(SET max_events_limit=(5000),max_memory=(4096))
WITH (MAX_MEMORY=4096 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=120 SECONDS,MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=NONE, TRACK_CAUSALITY=OFF, STARTUP_STATE=ON)
For the Locks session:
ADD TARGET package0.histogram(SET filtering_event_name=N'sqlserver.lock_acquired', source=N'sqlserver.query_hash'),
ADD TARGET package0.ring_buffer(SET max_events_limit=(1000000))
WITH (MAX_MEMORY=4096 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=30 SECONDS, MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=NONE, TRACK_CAUSALITY=ON, STARTUP_STATE=OFF)
Originally I thought the histogram was the issue, but after following up with Jonathan Kehayias (@sqlpoolboy/blog) of SQLskills - when you think of Extended Events, you should think of Jonathan - I found I was mistaken. I thought that the MAX_MEMORY=4096KB would throttle the ring buffer to 4MB. Instead, Jonathan explained to me that the MAX_MEMORY parameter in the WITH clause just determines the "event session memory buffer space for buffering events before they are dispatched to the targets for consumption" - the buffer *before* the ring buffer. There is a MAX_MEMORY parameter for the target but it needs to be included is the SET clause (like the max_events_limit) to affect the size of the target. If the SET MAX_MEMORY is set, it will cause the buffer to cycle, effectively having the events overwrite themselves, once the size is reached. With no parameter defined, there is *no* cap on the size of the ring buffer other than the indirect limit imposed by the max_events_limit parameter.
As you can see above, the default system_health session has its ring buffer set to a max_events_limit of 5,000 events, while the user-defined "Locks" session has a max_events_limit of 1,000,000 events! (Say it with me - one Millllllion events). The catch Jonathan described to me is that events can be of any size, so you can't directly convert a certain number of events to any particular MB/GB size.
As he so often does, Jonathan went above and beyond my basic question and found he could easily reproduce this problem (the XE session causing the 701 errors) on a SQL 2012 instance in his lab using the same XE session configuration. As Jonathan notes in this blog post on sqlperformance.com, this is an issue especially with SQL 2012 and the way XE works in 2012.
--
The catch to all of this is that had I realized it was an XE problem right away, there might (*might*) have been enough data still present in the default trace for me to see who had "Object:Created" the "Locks" object, but by the time I realized it was an XE situation the default trace had spun past the time of the original problem when the XE session was created, so there was no way (that I know of) to find the login responsible without someone confessing at the client.
The cautionary tool here is don't use a tool in Production that you don't understand (and remember, almost every environment is Production to someone!) - I have not been able to find out what the unknown admin was trying to accomplish with this session, but had they understood how XE sessions and the ring buffers work, they never would have set a max_events_limit so high without an accompanying max_memory parameter to cap the size of the ring buffer itself.
Thanks to Denny Cherry (@mrdenny/blog), Robert Davis (@sqlsoldier/blog), @sql_handle, and especially Jonathan Kehayias for their insights and #sqlhelp - community is amazing and I am proud to be part of it.
This was several hours for me on a Friday night and a Saturday early morning - hopefully this will help someone else in a similar situation in the future!
