

We’re reading in some JSON files in Azure Data Factory (ADF), for example for a REST API. We’re storing the data in a relational table (SQL Server, Azure SQL DB…). The data volume is low, so we’re going to use a Copy Data activity in a pipeline, rather than a mapping data flow (or whatever they’re called these days). The reason why I specifically mention this assumption is that a data flow can flatten a JSON, while a Copy Data activity it needs a bit more work.
A Copy Data activity can – as it’s name gives away – copy data between a source and a destination (aka sink). In many cases, ADF can map the columns between the source and the sink automatically. This is especially useful when you’re building metadata-driven parameterized pipelines. Meta-what? Read this blog post for more info: Dynamic Datasets in Azure Data Factory.
The problem with JSON is that it is hierarchical in nature, so it doesn’t map that easily to a flattened structure, especially if there’re nested lists/arrays/whatevers. So you would need to specify an explicit mapping with a collection reference, like the one in this screenshot:
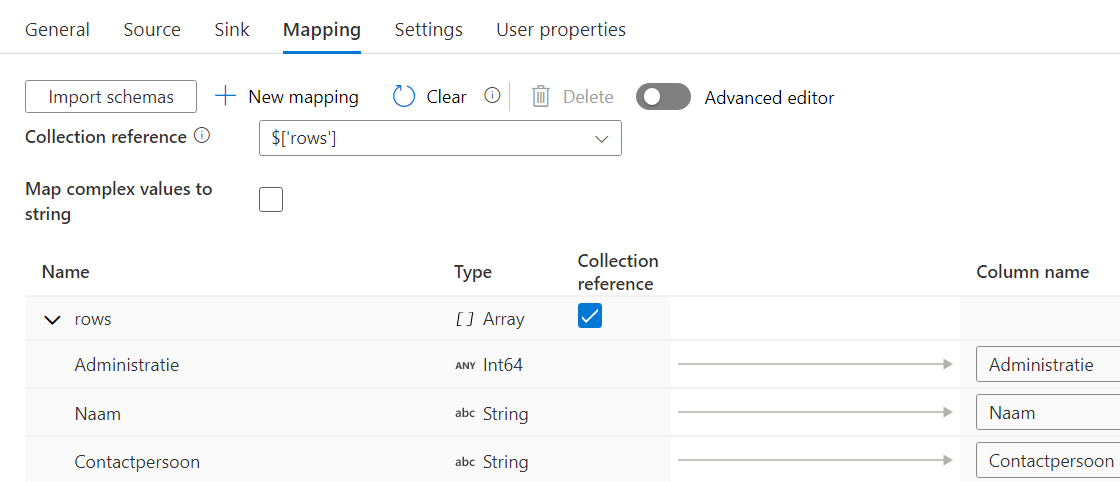
But if you need to import dozens of JSONs, this would mean a separate Copy Data activity for each JSON. Ugh, we don’t want that because that’s a lot of work. Luckily, there’s an option to specify a mapping with dynamic content (in other words, it can be parameterized):
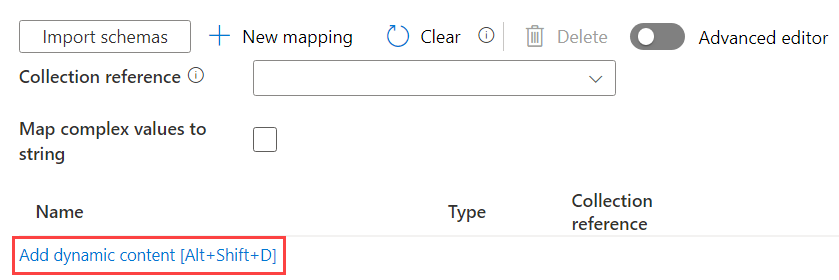
The mapping between the source and the sink columns needs to be specified using … JSON of course  The official docs explain how it should look like. In my case, I made a couple of assumptions:
The official docs explain how it should look like. In my case, I made a couple of assumptions:
- the destination table has already been created (it’s better this way, because if you let ADF auto-create it for you, you might end up with a table where all the columns are NVARCHAR(MAX))
- the column names from the source and the sink are exactly the same. Notice the emphasis on “exactly”. This means casing, but also white space and other shenanigans. If it’s not the case, ADF will not throw an error. It will just stuff the column it can’t map with NULL values.
- it’s OK if there are columns in the source or the sink that don’t exist on the other side. They just won’t get mapped and are thus ignored.
I wrote a little script that will read out the metadata of the table and translate it to the desired JSON structure. It uses FOR JSON, so you’ll need to be on SQL Server 2016 or higher (compat level 130). If you’re on an older version, read this blog post by Brent Ozar.
CREATE FUNCTION [dbo].[Get_JSONTableMapping](@TableName VARCHAR(250))
RETURNS TABLE
AS
RETURN
SELECT jsonmapping = '{"type": "TabularTranslator", "mappings": ' +
(
SELECT
'source.path' = '[''' + IIF(c.[name] = 'Guid','GUID_regel',c.[name]) + ''']'
-- ,'source.type' = m.ADFTypeDataType
,'sink.name' = c.[name]
,'sink.type' = m.ADFTypeDataType
FROM sys.tables t
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.all_columns c ON c.object_id = t.object_id
JOIN sys.types y ON c.system_type_id = y.system_type_id
AND c.user_type_id = y.user_type_id
JOIN etl.ADF_DataTypeMapping m ON y.[name] = m.SQLServerDataType
WHERE 1 = 1
AND t.[name] = @TableName
AND s.[name] = 'src'
AND c.[name] <> 'SRC_TIMESTAMP'
ORDER BY c.column_id
FOR JSON PATH
) + ',"collectionreference": "$[''rows'']","mapComplexValuesToString": true}';It returns output like this:
{
"type": "TabularTranslator",
"mappings": [
{
"source": {
"path": "['Column1']"
},
"sink": {
"name": "Column1",
"type": "Int32"
}
},
{
"source": {
"path": "['Column2']"
},
"sink": {
"name": "Column2",
"type": "String"
}
}
],
"collectionreference": "$['rows']",
"mapComplexValuesToString": true
}Keep in mind that the collection reference is specific for my use case (REST API reading data from the AFAS ERP system btw). You probably will need to change it to accommodate it for your JSON. The function also uses a mapping table which maps the SQL Server data types to the data types expected by ADF (as explained in the official docs I linked to earlier).

The full table in SQL INSERT statements:
CREATE TABLE #temptable ( [ADFTypeMappingID] int, [ADFTypeDataType] varchar(20), [SQLServerDataType] varchar(20) ) INSERT INTO #temptable ([ADFTypeMappingID], [ADFTypeDataType], [SQLServerDataType]) VALUES ( 1, 'Int64', 'BIGINT' ), ( 2, 'Byte array', 'BINARY' ), ( 3, 'Boolean', 'BIT' ), ( 4, 'String', 'CHAR' ), ( 5, 'DateTime', 'DATE' ), ( 6, 'DateTime', 'DATETIME' ), ( 7, 'DateTime', 'DATETIME2' ), ( 8, 'DateTimeOffset', 'DATETIMEOFFSET' ), ( 9, 'Decimal', 'DECIMAL' ), ( 10, 'Double', 'FLOAT' ), ( 11, 'Byte array', 'IMAGE' ), ( 12, 'Int32', 'INT' ), ( 13, 'Decimal', 'MONEY' ), ( 14, 'String', 'NCHAR' ), ( 15, 'String', 'NTEXT' ), ( 16, 'Decimal', 'NUMERIC' ), ( 17, 'String', 'NVARCHAR' ), ( 18, 'Single', 'REAL' ), ( 19, 'Byte array', 'ROWVERSION' ), ( 20, 'DateTime', 'SMALLDATETIME' ), ( 21, 'Int16', 'SMALLINT' ), ( 22, 'Decimal', 'SMALLMONEY' ), ( 23, 'Byte array', 'SQL_VARIANT' ), ( 24, 'String', 'TEXT' ), ( 25, 'DateTime', 'TIME' ), ( 26, 'String', 'TIMESTAMP' ), ( 27, 'Int16', 'TINYINT' ), ( 28, 'GUID', 'UNIQUEIDENTIFIER' ), ( 29, 'Byte array', 'VARBINARY' ), ( 30, 'String', 'VARCHAR' ), ( 31, 'String', 'XML' ), ( 32, 'String', 'JSON' ); DROP TABLE #temptable
So we can execute this function inside a Lookup activity to fetch the JSON metadata for our mapping (read Dynamic Datasets in Azure Data Factory for the full pattern of metadata-driven Copy Activities).
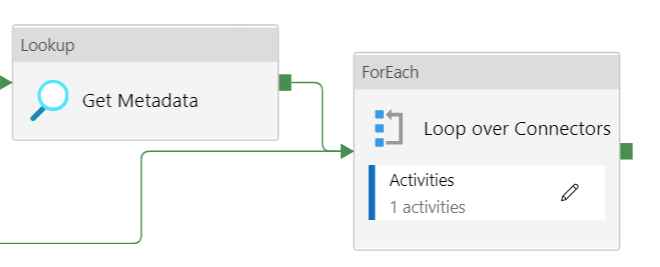
In the mapping configuration tab of the Copy Data Activity, we can now create an expression referencing the output of the Lookup activity.
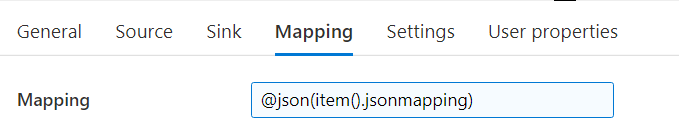
For easy copy paste:
@json(item().jsonmapping)
The item() function refers to the current item of the array looped over by the ForEach activity:
We need to wrap the expression of the mapping in the @json function, because ADF expects an object value for this property, and not a string value. When you know run the pipeline, ADF will map the JSON data automatically to the columns of the SQL Server table on-the-fly.
Note: there are other options as well to load JSON into a SQL Server database. You can dump the JSON into blob storage and then shred it using an Azure Function or Azure Logic App for example, or you can dump it into a NVARCHAR(MAX) column in a staging table and then use SQL to shred the JSON. Or use ADF data flows. I prefer the option from this blog post because the code complexity is very low and it’s dynamic. Just add a bit of metadata, create your destination table and you’re done.
The post Dynamically Map JSON to SQL in Azure Data Factory first appeared on Under the kover of business intelligence.