


Hello Dear Reader! I was teaching a class in Chicago last week and I got a lot of really great questions.
We only had two days so time was short. I got an email reminder today. So this is the first blog that will answer some questions that I didn’t get to cover in depth in class, and I thought it would be an Excellent Question of the Day!
The Question that I got was “What is the T-SQL SAVE TRANSACTION statement used for?”
The short answer is it is a way of setting a save point in multiple Nested Explicit Transactions. For the Long answer we’ll look a little deeper.
REFRESHER
Back in a little over two years ago I wrote a blog, We Should Have A Talk: Your Database is Using ACID. If you are unfamiliar with ACID go read up on it, because it is fundamental to what we are doing here.
In that same blog I talk about Explicit, Implicit, and Nested Transactions. In case you miss the ACID reading let’s cover those.

Every Transaction in SQL Server is an Implicit Transaction, unless otherwise specified. You can turn off Implicit Transactions but that’s a talk for another time. Implicit means implied, rather than expressly stated.
As with the picture we don’t have to say it. Hopefully things end a little better for us.
SQL Server works the same way. No, not like a cat driving a car. Transactions are just as Implicit.
Every single ALTER TABLE, CREATE, DELETE, DENY, DROP, FETCH, GRANT, INSERT, OPEN, REVOKE, SELECT, TRUNCATE TABLE, or UPDATE is a going to be wrapped in a BEGIN TRANSACTION and end with either a COMMIT or a ROLLBACK.
Explicit means fully and clearly expressed or demonstrated; leaving nothing merely implied.

There is no mistake about it. The following SQL Statement is an Explicit Transaction.
BEGIN TRANSACTION
INSERT INTO dbo.myTable1 DEFAULT VALUES
COMMIT TRANSACTION
So we’ve covered Implicitand Explicit, now we get to Nested. Nested Transactions are multiple levels of Explicit Transactions.

For Example:
Here we have 3 levels. However, if any one of them fail or ROLLBACK then they all Rollback.
Some companies use Explicit Transactions as part of their error handling. Nothing wrong with that, but wouldn’t it be nice if you could commit part of the statement, even if a later part fails?
SAVED!

Saved Transactions allow us to save our success as we go in Nested Transaction, so that a Rollback doesn’t wipe out all of our progress.
Depending how your code works, you MIGHT be able to use this. Test the logic very soundly.
So let’s look at how this works. First we’ll create a Table to test out our transaction.
if exists(select name from sys.tables where name='myTable1')
begin
drop table dbo.myTable1
end
go
create table dbo.myTable1(
myid int identity(1,1)
,mychar char(50)
,mychar2 char(50)
,constraint pk_myid_mytable1 primarykey clustered(myid)
)
Now let’s create a transaction to insert some data and roll it all back.
BEGIN TRANSACTION
INSERT INTO dbo.myTable1(mychar, mychar2)
VALUES('some data 1', 'some more data 1')
BEGIN TRANSACTION
INSERT INTO dbo.myTable1(mychar, mychar2)
VALUES('some data 2', 'some more data 2')
BEGIN TRANSACTION
UPDATE dbo.myTable1
set mychar='some new data 1'
WHERE myid=1
BEGIN TRANSACTION
SELECT * FROM dbo.myTable1
COMMIT TRANSACTION
COMMIT TRANSACTION
COMMIT TRANSACTION
ROLLBACK TRANSACTION
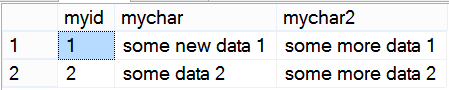
Here’s the Output from our SSMS Windows.
/*
OOPS did I say ROLLBACK!?
*/
SELECT * FROM dbo.myTable1
We had a ROLLBACK at the end. So the work isn’t going to stick. Sure enough another select from the table and everything is gone.
Now let’s try the same code again, but now we’ll create a SAVE TRANSACTION and name is testSavePoint. Note the syntax change. *We need to call this in the ROLLBACK otherwise the whole thing will ROLLBACK again.* ACID properties are still in play, so we need a COMMIT AFTER the ROLLBACK
/*
Let's Try this again
*/
BEGIN TRANSACTION
INSERT INTO dbo.myTable1(mychar, mychar2)
VALUES('some data 1', 'some more data 1')
SAVE TRANSACTION testSavePoint
BEGIN TRANSACTION
INSERT INTO dbo.myTable1(mychar, mychar2)
VALUES('some data 2', 'some more data 2')
save transaction testSavePoint
BEGIN TRANSACTION
UPDATE dbo.myTable1
set mychar='some new data 1'
WHERE myid=3
BEGIN TRANSACTION
SELECT * FROM dbo.myTable1
COMMIT TRANSACTION
COMMIT TRANSACTION
COMMIT TRANSACTION
ROLLBACK TRANSACTION testSavePoint
COMMIT TRANSACTION
Here’s our output from SSMS again. This looks very similar to last time with only changes in the identity key.

/*
OOPS did I say ROLLBACK AGAIN!?
But did we save anything
*/
SELECT * FROM dbo.myTable1

This time however, only our Update Statement was rolled back.
“So Balls,” you say, “That’s cool, but will we actually use this? If we are using Nested Transactions would we only want to save ½ of it?”
Excellent Question Dear Reader! Let me answer that with a real world scenario.
I was working with some friends earlier this year. We changed an update job that ran for hours from row-by-row logic to set based logic. The result was minutes instead of hours. There were two parts of this job that we worked on.
It was a four step process. First a range of data was selected from one table. Second we looked for missing data and inserted anything that was missing based on matching natural keys. Third we then looked at everything that matched and updated any rows that needed the information. Fourth we updated the range selected in another table. We needed all four steps to run. A Saved Transaction wouldn’t work for us using their current logic.
However the job failed when we first ran it, because there was an error on saving the range table. Insert and Updates worked just fine. The job would look at the range table and try the same range. Even though it was failing the job was reporting success because the error handling did not catch the rollback. It was explicitly called, but executed on a GO TO on error statement.
While we would have still had to fix the error on the range table, we could have used SAVE TRANSACTION to save the insert and update. Then moved the range table update to its own Transaction that would have better error handling. It also would save retry operations on the job by not processing expensive Updates, Inserts, and Rollbacks.
Alright Dear Reader, there it is. SAVE TRANSACTION and how it works with Explicit Transactions. Thanks for the questions, keep them coming!
As always Thanks for stopping by.
Thanks,
Brad
