

Why Warehouse
Data warehousing is the act of transforming application database into a format more suited for reporting and offloading it to a separate store so your day to day transactions are not affected. This process typically involves flattening the data.
Let’s imagine we have an online store
SELECT
dbo.Sales.Date,
dbo.Customer.FullName,
dbo.Product.Name,
dbo.Product.Price,
dbo.Discount.Name,
dbo.Discount.Amount
FROM
Sales
INNER JOIN Customer ON Customer.Id = Sales.CustomerId
INNER JOIN Product ON Product.Id = Sales.ProductId
INNER JOIN Discount ON Discount.Id = Sales.DiscountIdThis is a fairly simple example but we can see a lot of joins are required to produce this report and as we want to do more and more aggregations on our data for reporting the joins will slow things down more and more.
Lets pretend this has got to the point where our database is great for running our applications transactions and serving user requests but it’s just not holding up the our reporting needs. At this point we can think about creating a data warehouse, in it’s simplest form this just involves creating a new database with a new schema and setting up a process that copies data here from our application database. Given the above, our warehouse could serve the same report with a query like this
SELECT
Date,
CustomerName,
ProductName,
ProductPrice,
Name,
Amount
FROM
SalesOk, so we’ve saved a few lines on what’s probably a simple query to run anyway. Lets imagine the online shop we’re talking about is Amazon and they want to see sales per month for the last year, we’re then talking probably billions of records that need to be joined across 4 tables, in this case the warehouse will make a huge difference.
When reading about data warehousing there are a few common terms that are used and they are ETL, Fact, Dimension, Star and Snowflake, lets take a look at each of these and what they mean.
Fact Table
A fact table is a table containing metrics you will be reporting on, I typically think of this as the table the holds the numbers you’ll be aggregating on.
For example a fact table could be
| Sales | |
|---|---|
| Id | INT |
| CustomerId | INT |
| Quantity | INT |
| ProductId | INT |
| Date | DATETIME |
Dimension Table
A dimension table is a table that you will be joining to your fact tables to give the data in the fact table meaning/categorization.
Given the above example of a fact table, Customer and Product would be the dimensions, as they would allow us to report on the quantity of sales and group on things like customer location, product type etc…
Imagine the customer table in our warehouse looked like this
| Customers | |
|---|---|
| Id | INT |
| Name | NVARHAR(100) |
| Location | NVARCHAR(100) |
We can then run reports in our warehouse to get the count of products sold by location, so we’re using our fact table to get our metric (Quantity) and then we’re categorizing this data on our dimension table customer on the location field.
SELECT
Customer.Location,
SUM(Sale.Quantity) AS ProductsSold
FROM
dbo.Sale
INNER JOIN dbo.Customer ON Customer.Id = Sale.CustomerId
GROUP BY
Customer.LocationStar Schema
A star schema is the result of dimension tables that are not normalized. If you visualize this in the centre you have your fact table then you have the dimension tables coming off around it.
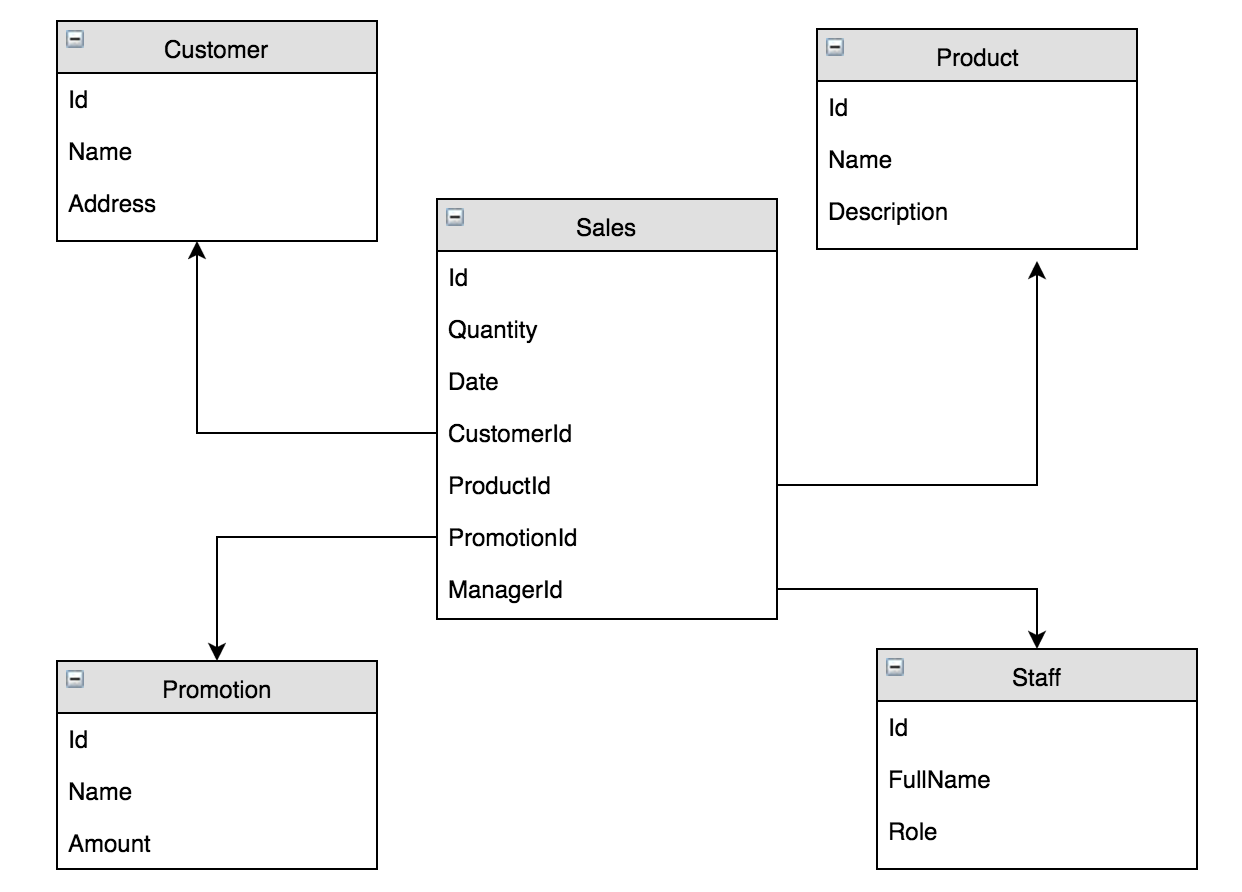
The above diagram shows a basic star schema, you have a fact table in the middle with flat dimension tables around it.
Snowflake Schema
A snowflake schema is when you have some normalization in your dimension tables, if you picture this model in the centre you have your fact table, round that you have your dimension tables and coming out of them you may have more dimension tables which can look a bit like a snowflake.
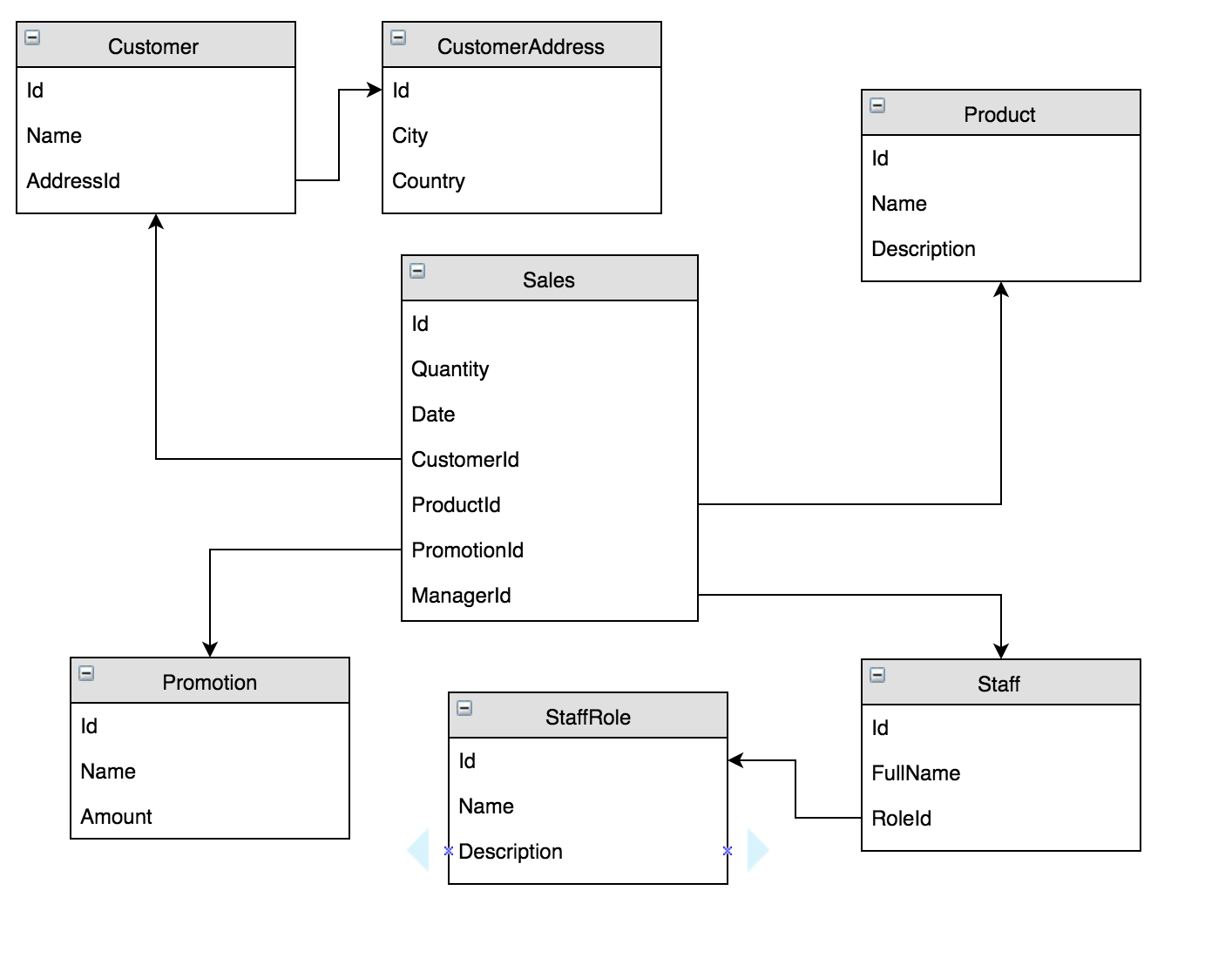
In the above diagram yu can see a basic snowflake schema, a fact table in the middle surrounded by dimension tables, some of which link to other dimension tables.
Which Schema To Choose?
There are reasons for and against on Snowflake vs Star and ultimately it’s about choosing the right trade offs for your environment.
The star schema makes queries a lot simpler as there is less joins but at the cost of a lot of duplicated denormalized data. This can also make it harder to maintain integrity as the data is duplicated and far less constrained.
The snowflake schema makes sense if you have a lot of dimension data, normally the fact data will be the bigger part of your warehouse but if in your scenario there is a lot of dimension data then it may make sense to keep it normalized.
ETL (Extract, Transform, Load)
This is ultimately the hardest problem to solve with warehousing. It comes down to how much of a delay is acceptable. SQL Server has an ETL tool called SSIS (SQL Server Integration Services) which can setup workflows for this process.
For example you could create an SSIS package that performs the ETL process every night and 9pm, or you could have it run hourly. For examples when you need near to real time reporting then you need to start looking at triggering this process as data changes come in to your application database.
