

I have blogged about Data Virtualization vs Data Warehouse and wanted to blog on a similar topic: Data Virtualization vs. Data Movement.
Data virtualization integrates data from disparate sources, locations and formats, without replicating or moving the data, to create a single “virtual” data layer that delivers unified data services to support multiple applications and users.
Data movement is the process of extracting data from source systems and bringing it into the data warehouse and is commonly called ETL, which stands for extraction, transformation, and loading.
If you are building a data warehouse, should you move all the source data into the data warehouse, or should you create a virtualization layer on top of the source data and keep it where it is?
The most common scenario where you would want to do data movement is if you will aggregate/transform one time and query the results many times. Another common scenario is if you will be joining data sets from multiple sources frequently and the performance needs to be super fast. These turn out to be the scenarios for most data warehouse solutions. But there could be cases where you will have many ad-hoc queries that don’t need to be super fast. And you could certainty have a data warehouse that uses data movement for some tables and data virtualization for others.
Here is a comparison of both:
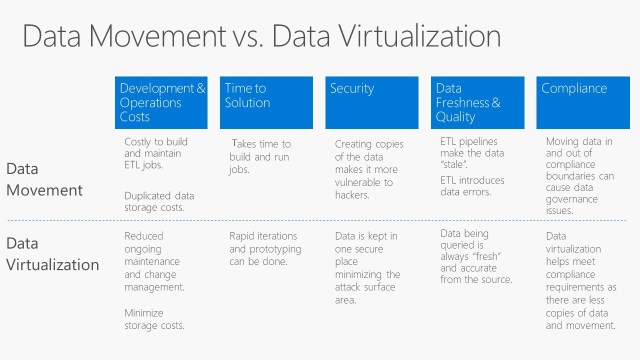
Other data virtualization benefits:
- Provides complete data lineage from the source to the presentation layer
- Additional data sources can be added without having to change transformation packages or staging tables
- All data presented through the data virtualization software is available through a common SQL interface regardless of the source (i.e. flat files, Excel, mainframe, SQL Server, etc)
While this table gives some good benefits of data virtualization over data movement, it may not be enough to overcome the sacrifice in performance or other drawbacks listed at Data Virtualization vs Data Warehouse. Also keep in mind the virtualization tool you choose may not support some of your data sources.
The better data virtualization tools provide such features as query optimization, query pushdown, and caching (i.e. Denodo) that may help with performance. You may see tools with these features called “data virtualization” and tools without these features called “data federation” (i.e. PolyBase).
More info:
Developing a Bi-Modal Logical Data Warehouse Architecture Using Data Virtualization

![]()
