

Watch this week's video on YouTube
One thing I see fairly often (and am occasionally guilty of myself) is using COUNT(DISTINCT) and DISTINCT interchangeably to get an idea of the number of unique values in a column.
While they will sometimes give you the same results, depending on the data the two methods may not always be interchangeable.
Let's start off with some test data. Important to note are the duplicate values, including the NULLs:
DROP TABLE IF EXISTS ##TestData;
CREATE TABLE ##TestData (Id int identity, Col1 char(1) NULL);
INSERT INTO ##TestData VALUES ('A');
INSERT INTO ##TestData VALUES ('A');
INSERT INTO ##TestData VALUES ('B');
INSERT INTO ##TestData VALUES ('B');
INSERT INTO ##TestData VALUES (NULL);
INSERT INTO ##TestData VALUES (NULL);
CREATE CLUSTERED INDEX CL_Id ON ##TestData (Col1);
If you want to know how many unique values are in Col1, you might write something like this:
SELECT COUNT(DISTINCT Col1)
FROM ##TestData
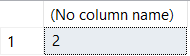
Two distinct values great! Except...weren't there some NULLs in there? If we want to see the actual values instead of just seeing the count:
SELECT DISTINCT Col1
FROM ##TestData

Interesting, when doing a plain DISTINCT we see there are three unique values, but in our previous query when we wrote COUNT(DISTINCT Col1) a count of two was returned.
And while the SQL Server documentation specifies that DISTINCT will include nulls while COUNT(DISTINCT) will not, this is not something that many people find intuitive.
Viewing and COUNTing the NULLs
Sometimes we might have to do the opposite of what the default functionality does when using DISTINCT and COUNT functions.
For example, viewing the unique values in a column and not including the nulls is pretty straightforward:
SELECT DISTINCT
Col1
FROM
##TestData
WHERE
Col1 IS NOT NULL
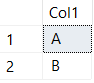
Getting the opposite effect of returning a COUNT that includes the NULL values is a little more complicated. One thing we can try to do is COUNT all of our DISTINCT non-null values and then combine it with a COUNT DISTINCT for our NULL values:
select COUNT(DISTINCT Col1) + COUNT(DISTINCT CASE WHEN Col1 IS NULL THEN 1 END)
from ##TestData;

While this logic is easy to interpret, it forces us to read our column of data twice, once for each COUNT - not very efficient on larger sets of data:

Another thing we can try is to put in a placeholder value (that doesn't exist elsewhere in the column's data) so that COUNT will include it in its calculation:
SELECT
/* ~~~ will never exist in our data */
COUNT(DISTINCT ISNULL(Col1,'~~~'))
FROM
##TestData

The ISNULL here functions the same as the CASE statement in our first attempt, without having to read the table twice. However, that Compute Scalar occurring to the left of our Clustered Index Scan will start to become painful as our data size increases since SQL Server will need to check each and every row and convert any NULLs it finds. Not to mention after computing all of those ~~~ values, SQL Server needs to re-sort the data to be able to find the DISTINCT values.
That leads us to a final attempt: using a DISTINCT in a derived table (to return our NULL) and then taking a count of that:
SELECT COUNT(*)
FROM (SELECT DISTINCT Col1 FROM ##TestData) v
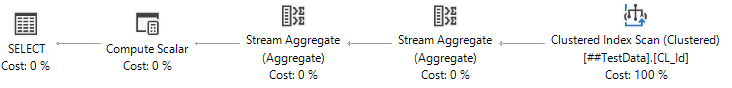
This last option eliminates the Compute Scalar and extra sort. While there might be even better options out there for accomplishing the same task, at this point I'm pretty happy with how this will perform.
What's the Point?
SQL Server's documentation says that COUNT(*) returns items in a group while COUNT(Col1) return non nulls in the group.
/* returns items in the group. Includes nulls */
SELECT COUNT(*)
FROM ##TestData;
/* returns non null values in group */
SELECT COUNT(Col1)
FROM ##TestData;
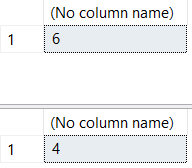
Because of this, COUNT, DISTINCT, and NULLs have a special relationship with each other that isn't always as intuitive as many people think.
Whenever using COUNT or DISTINCT, make sure to test with NULLs to make sure SQL Server is handling them like you expect.