

SQL Server 2012 introduced non-clustered columnstore indexes, and SQL Server 2014 gave us clustered columnstore indexes. Both share the same technology for performance boosts, and they both share the same algorithms for compression. However, the compression will depend on the data you are storing.
SQL Server uses a mechanism of row groups, segments, encoding and compression to store the data for columnstore indexes. First the data is horizontally divided into row groups, where each group contains approximately 1 million rows. Next, the row groups are vertically partitioned into segments, where each column of the table is its own segment. Those segments are then encoded and compressed before being stored on disk. So if you create a colulmnstore index on a table that has five columns and 100,000 rows, it would result in one row group with five segments.
Compression of any type will definitely vary depending on the data that needs to be compressed. Columnstore indexes use RLE (run-length encoding) compression which works best when you have a lot of repetitive values. Just to see how this works, let’s compare the compression for data that is random to the compression for data that is highly redundant.
First, we’ll create the following tables that contain only a single column using the CHAR data type. Each table will store 1 million rows. One table will store random values for each row, and the other will store identical values for each row.
CREATE TABLE dbo.IdenticalCharacter(Col1 CHAR(50) NULL);
GO
CREATE TABLE dbo.RandomCharacter(Col1 CHAR(50) NULL);
GO
Now we'll populate the tables will artificial data.
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO IdenticalCharacter VALUES (REPLICATE('a',50));
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO RandomCharacter
SELECT CAST(NEWID() AS CHAR(50));
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
Next, we’ll create a non-clustered columnstore index on each table.
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.IdentitcalCharacter(Col1);
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.RandomCharacter(Col1);
GO
Now we can calculate the size of each columnstore index using the script below. This is a modified version of the script from Books Online.
SELECT
SchemaName
,TableName
,IndexName
,SUM(on_disk_size_MB) AS TotalSizeInMB
FROM
(
SELECT
OBJECT_SCHEMA_NAME(i.OBJECT_ID) AS SchemaName,
OBJECT_NAME(i.OBJECT_ID ) AS TableName,
i.name AS IndexName
,SUM(css.on_disk_size)/(1024.0*1024.0) AS on_disk_size_MB
FROM sys.indexes i
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
INNER JOIN sys.column_store_segments css
ON css.hobt_id = p.hobt_id
WHERE i.type_desc = 'NONCLUSTERED COLUMNSTORE'
AND i.index_id NOT IN (0,1)
AND p.index_id NOT IN (0,1)
GROUP BY OBJECT_SCHEMA_NAME(i.OBJECT_ID) ,OBJECT_NAME(i.OBJECT_ID ),i.name
UNION ALL
SELECT
OBJECT_SCHEMA_NAME(i.OBJECT_ID) AS SchemaName
,OBJECT_NAME(i.OBJECT_ID ) AS TableName
,i.name AS IndexName
,SUM(csd.on_disk_size)/(1024.0*1024.0) AS on_disk_size_MB
FROM sys.indexes i
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
INNER JOIN sys.column_store_dictionaries csd
ON csd.hobt_id = p.hobt_id
WHERE i.type_desc = 'NONCLUSTERED COLUMNSTORE'
AND i.index_id NOT IN (0,1)
AND p.index_id NOT IN (0,1)
GROUP BY OBJECT_SCHEMA_NAME(i.OBJECT_ID) ,OBJECT_NAME(i.OBJECT_ID ),i.name
) AS SegmentsPlusDictionary
GROUP BY SchemaName,TableName,IndexName
ORDER BY SchemaName,TableName,IndexName;
GO

As you can see, the random data values did not compress nearly as much. 30MB of the total 41MB was just for the dictionaries, while only 11MB was needed for the segments. When you graph the data in Excel, it makes it little bit easier to see the difference in size.
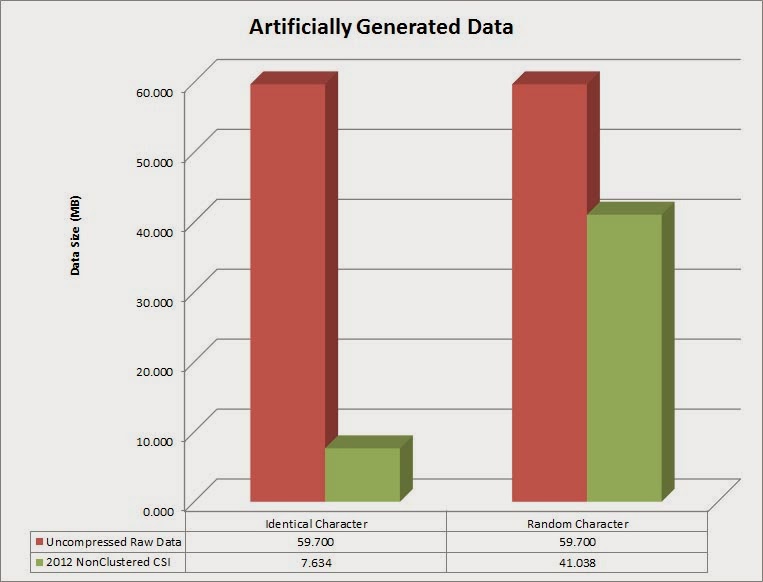
We can also compare a few other data types (integer and decimal), and we’ll see similar differences, but just not as drastic.
CREATE TABLE dbo.IdenticalInteger(Col1 INT NULL);
GO
CREATE TABLE dbo.RandomInteger(Col1 INT NULL);
GO
CREATE TABLE dbo.IdenticalDecimal(Col1 DECIMAL(18,8) NULL);
GO
CREATE TABLE dbo.RandomDecimal(Col1 DECIMAL(18,8) NULL);
GO
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO IdenticalInteger VALUES (1);
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO RandomInteger VALUES (@Counter);
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO IdenticalDecimal VALUES (1.0);
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
DECLARE @Counter int = 0;
WHILE @Counter < 1000000
BEGIN
INSERT INTO RandomDecimal VALUES (CAST((RAND() * @Counter) AS DECIMAL(18,8)));
SET @Counter = @Counter+1;
END
CHECKPOINT;
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.IdenticalInteger(Col1);
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.RandomInteger(Col1);
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.IdenticalDecimal(Col1);
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX csi1 ON dbo.RandomDecimal(Col1);
GO
Now run the same query from above to see the size difference of the indexes.
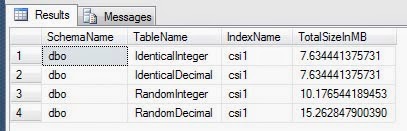
Here we see similar results as before; the highly redundant data gets compressed far more than the random data. Again, graphing the data makes it a little easier to visualize the difference.

The compression algorithm used for columnstore indexes is different from the row and page data compression originally released in SQL Server 2008; however, it’s interesting to compare the differences.
For this example, we’ll use actual data from a trading application. The fact table contains over 106 million rows, 26 columns which are mostly float data types, and is just over 21GB in size. Let’s compare the various types of compression: row, page, non-clustered columnstore index for SQL Server 2012, non-clustered columnstore index for SQL Server 2014, clustered columnstore index for SQL Server 2014, and lastly a clustered columnstore index with archival compression for SQL Server 2014.
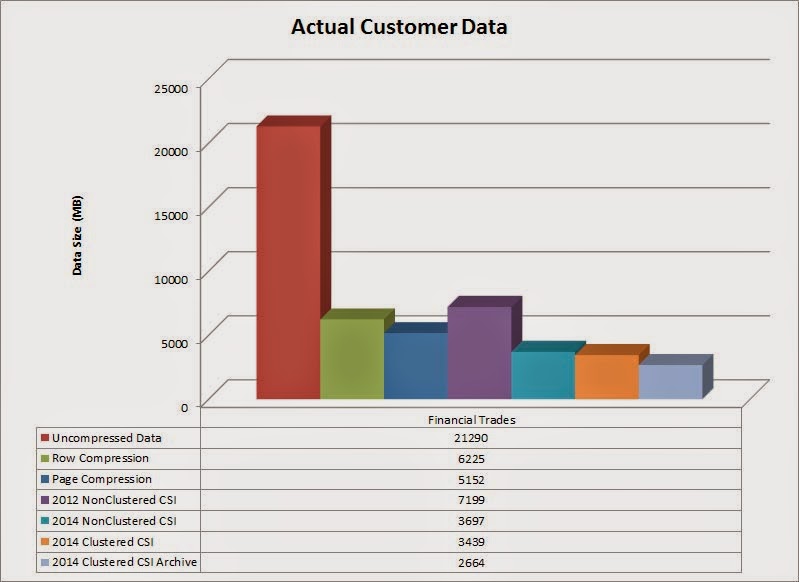
The graph above shows row and page compression already have compressed the data significantly, but the various columnstore indexes compress it even further. There are a couple of things to keep in mind. First, the non-clustered columnstore indexes are a separate copy from the base table, so the 7199MB 2012 columnstore index would be in addition to the 21GB of raw data for a total of nearly 29GB. The two clustered columnstore indexes only need 3.4GB and 2.6GB to store the entire dataset. That’s a 6X and 8X compression difference.
You may wonder why the 2012 non-clustered columnstore index is larger (7199MB) than the just using ordinary row or page compression, but there really is nothing wrong. It’s just a good example showing the differences in the compression algorithms. Although this example doesn’t show it, there are some cases where the columnstore compressed data could be higher than the actual data.
As you can see, columnstore indexes have to potential to highly compress your data, but it really depends on the type of data you’re storing and redundancy of the data values. The only way to know for sure to is to test it with your own data.
For more info on columnstore indexes, check out the Columnstore Index FAQ on Technet, Books Online, and my other blog posts.
