

In SQL Server, each and every row in a table needs to be accessible by itself, whether or not you declare a Primary Key. Even if you had 1 million rows of just the letter “A” in a one-column table, SQL Server still needs to distinguish between each of those 1 million rows so that it can manage them, refer to them, and record what happens to them.
When a table has no Clustered Index defined on it, it is known as a “heap”. Even if such a table has a Non-Clustered Primary Key defined on it, it is still a “heap”. The reason is that a Non-Clustered Index is entirely separate from the table; it has a copy of the key values plus a value that points to the specific source row. A Clustered Index, however, is the table, and the key values are not a copy of the source values, they are the source values.
But remember, each row in a table needs a unique value that points to only that row. This unique value is what gets copied into Non-Clustered Indexes. For heaps, since there is no declared (i.e. via DDL) reliable way of identifying a row, a hidden, system-generated unique RowID (RID) is added to each row. Clustered Indexes, on the other hand, a) do have a declared structure that is b) part of the table itself. So if those one or more key columns of the Clustered Index are unique, then there is no need for an additional RID value.
A Primary Key as well as a Unique Index / Constraint are all guaranteed to be unique so there’s nothing more to do. The key value(s) inherently point to one, and only one, row. But, when a Clustered Index is created without the UNIQUE keyword, then SQL Server still needs to guarantee uniqueness of the key value(s), even if the key value(s) can have duplicates as far as you are concerned. And so SQL Server throws in an extra, hidden INT value as a key field.
This hidden field is known as the “uniquifier”. It takes up 4 bytes, but only when needed. And it is only needed when the declared key columns contain duplicate values. By implication, the first row containing a never-before seen key value (or combination of key values for a composite index) is inherently unique, thus it does not need any extra help in being unique, and no uniquifier value is added in any way (meaning, no additional 4 bytes are taken up). But starting with the first duplicate value (or set of values for a composite index), then that hidden field is added to the row.
We can see evidence of this behavior both indirectly and directly. We will test 3 Clusterd Index scenarios:
- Declared Unique: No uniquifier since the only option is for unique values.
- Non-Unique with all rows being the same value: The uniquifier is required for all but the first row since all rows duplicate the first row.
- Non-unique with all unique values: The Clustered Index has no guarantee that incoming data will be unique, so the uniquifier might be needed, but there are no duplicate values in this case, so does the uniquifier still take up the 4 bytes?
Indirect Evidence
SETUP
-- Create the tables:
CREATE TABLE #Unique (Col1 INT NOT NULL); -- No Uniquifier
CREATE TABLE #NonUnique (Col1 INT NOT NULL); -- Uniquifier required
CREATE TABLE #UniqueWithinNonUnique (Col1 INT NOT NULL); -- Uniquifier
-- available; is it used?
-- Create the indexes:
CREATE UNIQUE CLUSTERED INDEX [idx] ON #Unique([Col1] ASC)
WITH (FILLFACTOR = 100);
CREATE CLUSTERED INDEX [idx] ON #NonUnique([Col1] ASC)
WITH (FILLFACTOR = 100);
CREATE CLUSTERED INDEX [idx] ON #UniqueWithinNonUnique([Col1] ASC)
WITH (FILLFACTOR = 100);
-- Populate the tables:
INSERT INTO #Unique ([Col1])
SELECT TOP (100000) ROW_NUMBER() OVER (ORDER BY (SELECT 0))
FROM [master].[sys].[all_columns] sac1
CROSS JOIN [master].[sys].[all_columns] sac2;
INSERT INTO #NonUnique ([Col1])
SELECT TOP (100000) 999
FROM [master].[sys].[all_columns] sac1
CROSS JOIN [master].[sys].[all_columns] sac2;
INSERT INTO #UniqueWithinNonUnique ([Col1])
SELECT TOP (100000) ROW_NUMBER() OVER (ORDER BY (SELECT 0))
FROM [master].[sys].[all_columns] sac1
CROSS JOIN [master].[sys].[all_columns] sac2;
-- Make sure all data pages are in ideal state:
ALTER INDEX [idx] ON #Unique REBUILD;
ALTER INDEX [idx] ON #NonUnique REBUILD;
ALTER INDEX [idx] ON #UniqueWithinNonUnique REBUILD;
VERIFY
It’s a good idea to make sure that you are testing with the data that you think you are testing with 
-- Verify inserted data is unique or non-unique as expected: SELECT TOP (5) * FROM #Unique ORDER BY [Col1] ASC; SELECT TOP (5) * FROM #NonUnique ORDER BY [Col1] ASC; SELECT TOP (5) * FROM #UniqueWithinNonUnique ORDER BY [Col1] ASC;
TEST
EXEC tempdb.sys.sp_spaceused N'#Unique'; EXEC tempdb.sys.sp_spaceused N'#NonUnique'; EXEC tempdb.sys.sp_spaceused N'#UniqueWithinNonUnique';
RESULTS
The image below shows that the first and third scenarios — Declared Unique and Non-Unique with unique values — are the same size across all categories, though here we are mostly focused on the Reserved and Data sizes. But the second scenario — Non-Unique with all values being the same — shows the Reserved and Data sizes being quite a bit larger: 544 KB and 768 KB, respectively.
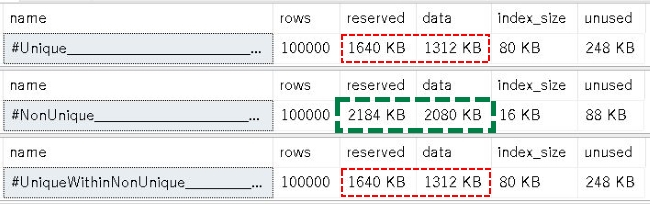
From this it certainly does appear that the uniquifier is only physically present when needed, which was the case in scenario #2.
Direct Evidence
Seeing that the sizes are the same between the #Unique and the #UniqueWithinNonUnique tables is compelling, but we should keep in mind that “correlation is not causation”, and that it is always preferable to have more explicit evidence. Fortunately, we are able to get more direct evidence by examining the contents of the data pages to see if the Uniquifier is actually there, and if so, if it is taking up any space or not.
To make it easier, we will dump the results of the undocumented DBCC PAGE command into local temporary tables so that we can then get some aggregate information from them.
SETUP
CREATE TABLE #DbccResults_Unique ( [ResultsID] INT IDENTITY(1, 1) NOT NULL, [ParentObject] NVARCHAR(255), [Object] NVARCHAR(255), [Field] NVARCHAR(255), [VALUE] NVARCHAR(255) ); CREATE TABLE #DbccResults_NonUnique ( [ResultsID] INT IDENTITY(1, 1) NOT NULL, [ParentObject] NVARCHAR(255), [Object] NVARCHAR(255), [Field] NVARCHAR(255), [VALUE] NVARCHAR(255) ); CREATE TABLE #DbccResults_UniqueWithinNonUnique ( [ResultsID] INT IDENTITY(1, 1) NOT NULL, [ParentObject] NVARCHAR(255), [Object] NVARCHAR(255), [Field] NVARCHAR(255), [VALUE] NVARCHAR(255) );
POPULATE TABLES
Here we use the sys.dm_db_database_page_allocations DMF to find the first data page for each table. When then use DBCC PAGE to dump the contents of that page into the local temp tables.
DECLARE @DatabaseID INT = DB_ID(N'tempdb'),
@FileID INT,
@PageID INT;
SELECT @FileID = dpa.allocated_page_file_id,
@PageID = dpa.allocated_page_page_id
FROM sys.dm_db_database_page_allocations(@DatabaseID,
OBJECT_ID(N'tempdb..#Unique'), 1, NULL, 'DETAILED') dpa
WHERE dpa.[page_type] = 1 -- DATA_PAGE
AND dpa.[previous_page_page_id] IS NULL; -- first page
INSERT INTO #DbccResults_Unique ([ParentObject], [Object], [Field],
[VALUE])
EXEC sp_executesql
N'DBCC PAGE (@DatabaseID, @FileID, @PageID, 3) WITH TABLERESULTS;',
N'@DatabaseID INT, @FileID INT, @PageID INT',
@DatabaseID = @DatabaseID, @FileID = @FileID,
@PageID = @PageID;
---
SELECT @FileID = dpa.allocated_page_file_id,
@PageID = dpa.allocated_page_page_id
FROM sys.dm_db_database_page_allocations(@DatabaseID,
OBJECT_ID(N'tempdb..#NonUnique'), 1, NULL, 'DETAILED') dpa
WHERE dpa.[page_type] = 1 -- DATA_PAGE
AND dpa.[previous_page_page_id] IS NULL; -- first page
INSERT INTO #DbccResults_NonUnique ([ParentObject], [Object], [Field],
[VALUE])
EXEC sp_executesql
N'DBCC PAGE (@DatabaseID, @FileID, @PageID, 3) WITH TABLERESULTS;',
N'@DatabaseID INT, @FileID INT, @PageID INT',
@DatabaseID = @DatabaseID, @FileID = @FileID, @PageID = @PageID;
---
SELECT @FileID = dpa.allocated_page_file_id,
@PageID = dpa.allocated_page_page_id
FROM sys.dm_db_database_page_allocations(@DatabaseID,
OBJECT_ID(N'tempdb..#UniqueWithinNonUnique'), 1, NULL, 'DETAILED') dpa
WHERE dpa.[page_type] = 1 -- DATA_PAGE
AND dpa.[previous_page_page_id] IS NULL; -- first page
INSERT INTO #DbccResults_UniqueWithinNonUnique ([ParentObject],
[Object], [Field], [VALUE])
EXEC sp_executesql
N'DBCC PAGE (@DatabaseID, @FileID, @PageID, 3) WITH TABLERESULTS;',
N'@DatabaseID INT, @FileID INT, @PageID INT',
@DatabaseID = @DatabaseID, @FileID = @FileID, @PageID = @PageID;
TEST
Here we check for:
- How many rows on this data page: the uniquifier takes up space (when used) which reduces the number of rows that can fit on a page
- How many of those rows are 11 bytes: this is the row size when no uniquifier is present.
- How many of those rows are 19 bytes: this is the row size when the uniquifier is present.
- How many of those rows could have a uniquifier: this will be unique rows in a non-unique clustered index.
- How many of those rows do have a uniquifier: this will be non-unique rows in a non-unique clustered index.
SELECT N'Unique' AS [Table],
MAX(CASE WHEN [Field] = N'm_slotCnt' THEN [Value] ELSE 0 END)
AS [RowsOnPage],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 11 THEN 1
ELSE 0 END) AS [11ByteRow],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 19 THEN 1
ELSE 0 END) AS [19ByteRow],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 0' THEN 1 ELSE 0 END) AS [UniquifierAvailable],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 4' THEN 1 ELSE 0 END) AS [UniquifierInUse]
FROM #DbccResults_Unique;
SELECT N'NonUnique' AS [Table],
MAX(CASE WHEN [Field] = N'm_slotCnt' THEN [Value] ELSE 0 END)
AS [RowsOnPage],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 11 THEN 1
ELSE 0 END) AS [11ByteRow],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 19 THEN 1
ELSE 0 END) AS [19ByteRow],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 0' THEN 1 ELSE 0 END) AS [UniquifierAvailable],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 4' THEN 1 ELSE 0 END) AS [UniquifierInUse]
FROM #DbccResults_NonUnique;
SELECT N'UniqueWithinNonUnique' AS [Table],
MAX(CASE WHEN [Field] = N'm_slotCnt' THEN [Value] ELSE 0 END)
AS [RowsOnPage],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 11 THEN 1
ELSE 0 END) AS [11ByteRow],
SUM(CASE WHEN [Field] = N'Record Size' AND [Value] = 19 THEN 1
ELSE 0 END) AS [19ByteRow],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 0' THEN 1 ELSE 0 END) AS [UniquifierAvailable],
SUM(CASE WHEN [Field] = N'UNIQUIFIER' AND [Object] LIKE
N'%(physical) 4' THEN 1 ELSE 0 END) AS [UniquifierInUse]
FROM #DbccResults_UniqueWithinNonUnique;
RESULTS
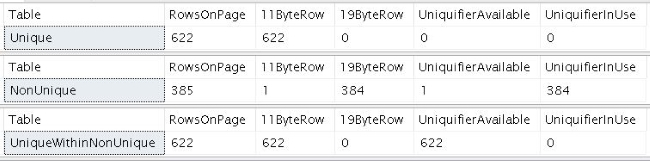
As we can see below:
- The only difference between the
UniqueandUniqueWithinNonUniquetables, which are the same size as we saw earlier, is whether or not the uniquifier was available. - For the
NonUniquetable, which, as we saw earlier, is larger than the other two:- there are fewer rows on the data page (since the rows are generally 8 bytes larger)
- one row — the first row, even though this query doesn’t show that particular detail — is unique and so doesn’t need the uniquifier (which is why I got the first data page for each table instead of any one random page)
CLEANUP (optional – they are temp tables after all)
/* DROP TABLE #Unique; DROP TABLE #NonUnique; DROP TABLE #UniqueWithinNonUnique; */ /* DROP TABLE #DbccResults_Unique; DROP TABLE #DbccResults_NonUnique; DROP TABLE #DbccResults_UniqueWithinNonUnique; */
Conclusion
As we saw here, the uniquifier is a hidden key column, added automatically to Clustered Indexes when they are not created using the UNIQUE keyword (and not as a Primary Key, which is, by its very nature, unique). However, being added to the index does not mean that they necessarily take up space on each row. They only take up space when needed, and they are only needed when the key value / composite key value is not unique.
What this really means is that you are not penalized if you create a Clustered Index to hold unique values and forget to use the UNIQUE keyword  .
.
Next time we will take a quick look at why the row size increased by 8 bytes when it was only a 4 byte INT column that was added, and what effect the uniquifier has on Non-Clustered Indexes.
