

The Problem
During our workload we have recognized a difference in performance for queries using IN clause. We are building query dynamically, so you can have a different length of list in IN clause. We work on the top of the Clustered Column Store Index table on SQL 2016 version.
Explanation
If you have a clause with just a couple of values such as this one:
WHERE [CCIDatatypeTestINT].[Column1] in (1, 2, 3, 4)
It translated to the following predicate in Scan operator
[AdventureWorksDW2017].[dbo].[CCIDatatypeTestINT].[Column1]=(1) OR [AdventureWorksDW2017].[dbo].[CCIDatatypeTestINT].[Column1]=(2) OR [AdventureWorksDW2017].[dbo].[CCIDatatypeTestINT].[Column1]=(3) OR [AdventureWorksDW2017].[dbo].[CCIDatatypeTestINT].[Column1]=(4) OR
And this is how exec plan looks:
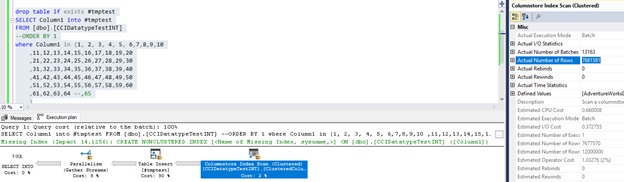
However, if you exceed 64 items in IN clause, exec plan changes as the following picture shows.
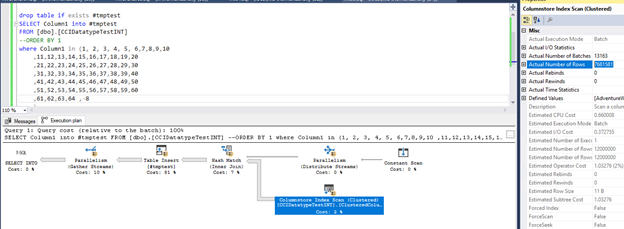
As you can see, we now have constant scan and hash match. As you can see, Actual Number of Rows of the scan operator did not change! In case of integer optimizer, it is still able to do a pushdown of the list from hash into the scan.
The situation is however different for nvarchar datatypes. Let’s see how exec plan looks if we have 64 or fewer values in IN clause:
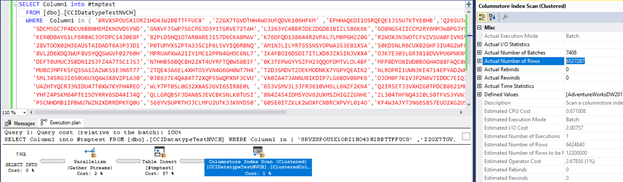
The predicate pushdown works well in this case and we have 6.5 mio records as an output of scan.
Now let’s check how it looks for 65 values in IN clause.
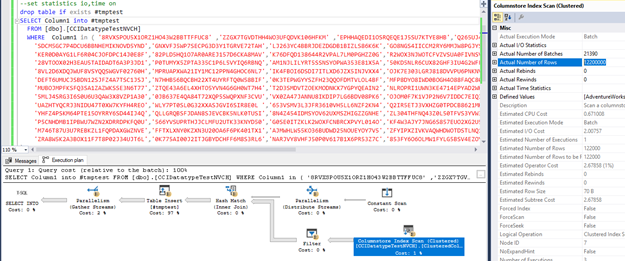
This is different exec plan than for INT data type. We can see all 12.2 mio records as an output of Scan operation. In this case, predicate pushdown of hash match results was not possible due to the probe values for s strings when hashing. Therefore, new operator – Filter is introduced in our plan to apply string filter. Let’s see some details of the filter operator:
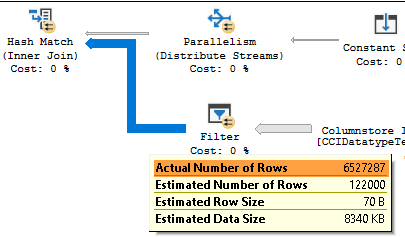
Let’s compare some statistics for integers – 64 values vs 65 values
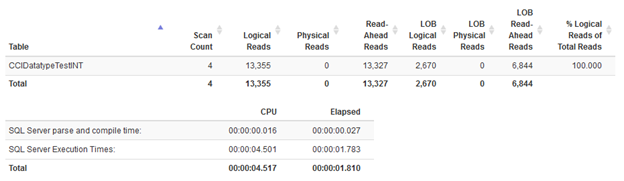
Statistics for Int with 64 items in IN condition
Statistics for Int with 65 items in IN condition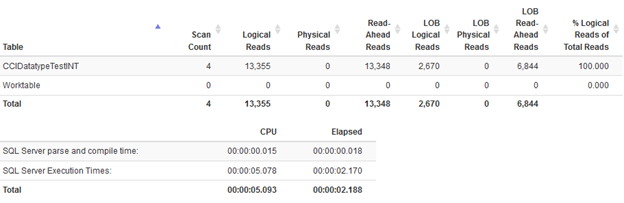
You can see there is no difference in IO activity. We have slightly different duration, but nothing dramatic.
Now let’s check the string results:
Statistics for nvarchar with 64 items in IN condition
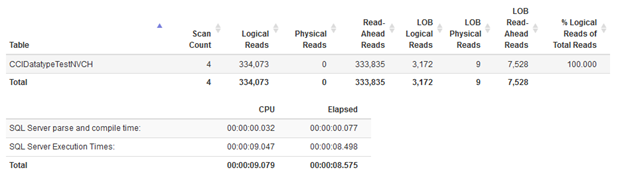
Statistics for nvarchar with 65 items in IN condition
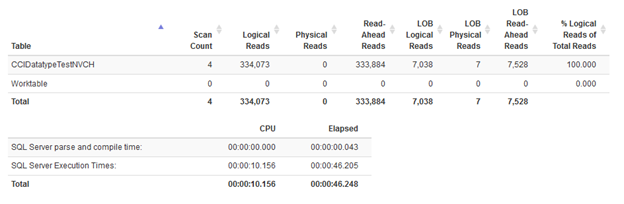
As you can see here the impact was huge. 8 seconds vs 46 seconds means we do better when we run query twice with shorter list of values in IN clause.
Summary
64 is the magic number for WHERE IN clause when working with CCI.
- For list of values less than 64 predicate pushdown works well.
- For more than 64 values we will have constant scan and hash.
- Due to the way how hashing works for INT, engine can push down values from hash operator thanks to the Bitmap In-Row Optimization
- For NVARCHAR due to the probe mechanism push down to scan is not possible
Therefore, the impact of going over 64 will be especially visible when working with strings in CCI. It will be of course less visible if your query is complex and scan takes only a small part of the duration.
