

Introduction
In this blog post, I would like to explain what a columnstore segment elimination is and how to load data to achieve better segment elimination.
I’ll cover the following scenarios of loading data into a CCI:
- Loading a Small Data Set: Create a CCI on a table with clustered index using MAXDOP 1,
- Loading a Large Data Set into a table with CCI using a splitter and data distribution logic.
Before we dig into segments elimination details, let’s quickly review the columnstore index structure:
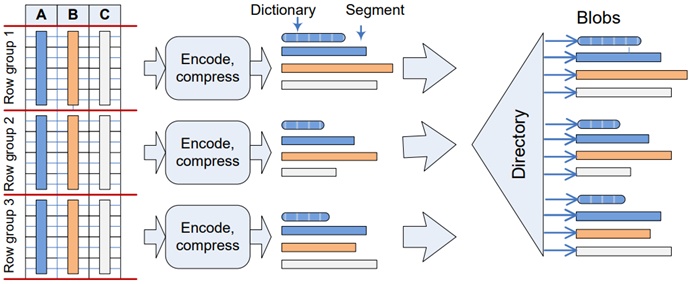
As we can see in the diagram above, a row group contains a set of rows (each row group can have up to 1 048 576 rows) that are converted to column segments and dictionaries. Column segments and dictionaries are stored on storage (broken down into 8KB pages) as BLOB data.
What is Columnstore Segment Elimination?
First and foremost, I have to mention that each segment has its own metadata that can be retrieved from the system catalog view sys.column_store_segments.
To achieve better segment elimination, we should focus on min_data_id and max_data_id values. These values represent Minimum/Maximum data id in the column segment and are used by SQL Server to eliminate any row groups that don’t meet the filter criteria (this process is called segment elimination).
Let’s have a look at the following example:
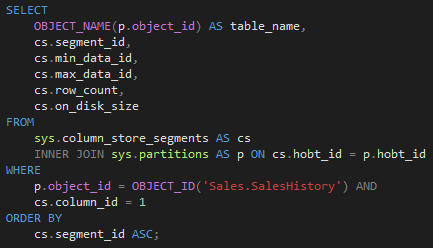
The SalesHistory table contains 6 segments in total:
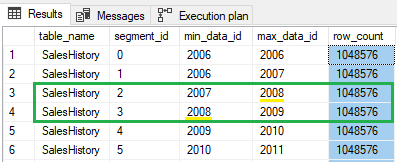
If we run a query with filter on YearNr = 2008, SQL Server uses the metadata (min_data_id and max_data_id) and reads only 2 segments (segment_id: 2, 3) and eliminates 4 segments (segment_id: 0, 1, 4, 5).
Note: It’s very important to mention that Character Data Types do not support Segment Elimination. The full list of data types that (do not) support segment elimination is available in the blog post Clustered Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”) written by Niko Neugebauer.
1.) Loading a Small Data Set: Create a CCI on a table with clustered index using MAXDOP 1
In this case scenario, we are going to test Segment Elimination process on a small data set (typically a few millions of rows).
For our tests, we are going to use the heap table Sales.SalesHistory that contains around 16 million rows.
Approach 1: Create a CCI on a heap table
Now, let’s create a CCI on this table:
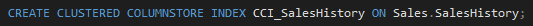
and check how many segments SQL Server eliminates when we execute the following query:
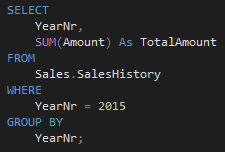
As we can see in the Messages tab, SQL Server had to read all 17 segments. If we visualize data from the catalog view sys.column_store_segments, we can see that value YearNr = 2015 is included in every single segment:
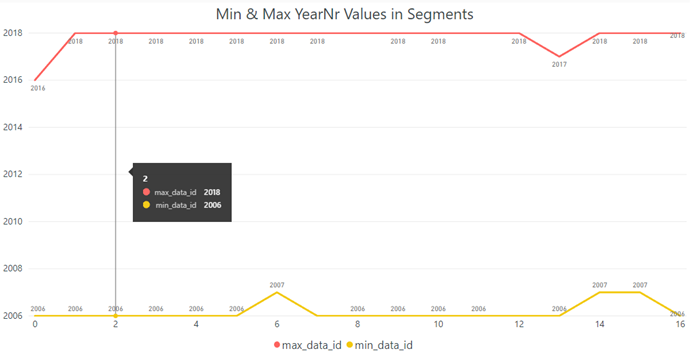
The reason for the wide range between min_data_id and max_data_id is that we created a CCI on the unsorted heap table Sales.SalesHistory and the table scan has been performed in a parallel way – as shown in the execution plan below:

Approach 2: Create a CCI on a table with Clustered Index with MAXDOP 1:
As we want to achieve better segment elimination, we will have to come up with another approach. Namely, let’s drop the CCI we just created and create a Clustered Index

At this point we have data sorted by YearNr, YearQuarterNr columns so we can create a new CCI on this table with MAXDOP 1 to prevent parallelism:

Checking the actual execution plan, we can see that the query was executed in single-thread mode:

And min_data_id and max_data_id values from the catalog view sys.column_store_segments look much better now:
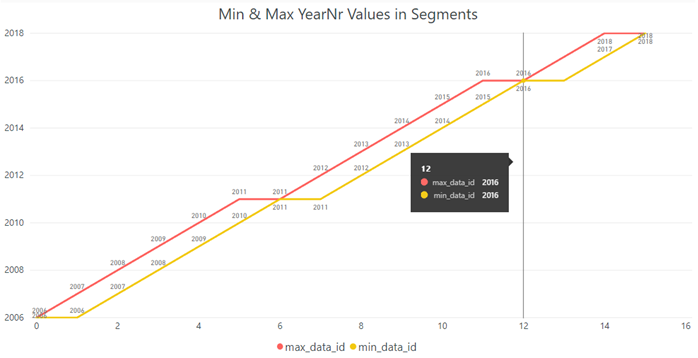
If we execute the same query, we can see that 14 segments out of 16 are eliminated:
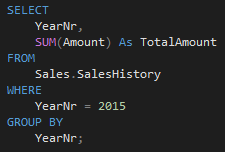
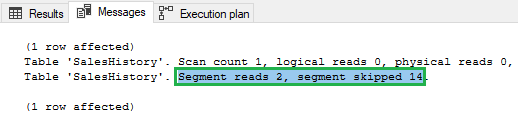
That’s exactly what we wanted to achieve.
2.) Loading a Large Data Set into a table with CCI using a splitter and data distribution logic
In the first scenario, we’ve created a new CCI with MAXDOP 1 on top of a table with clustered index – this approach is absolutely fine for reasonably small tables (a few million rows).
But, in some cases, we have very large tables (let’s say a few billion rows) so we cannot just simply go ahead and create a clustered index on it due to disk space limits, execution time, etc.
One of the options for loading large data sets into a CCI to achieve better segment elimination is to split data into smaller chunks/batches, based on a splitter attribute.
Analysis of our large Source table with CCI:
In our case scenario, we will use a table named Sales.SalesHistory_EnlargedSRC as an input. This table has the following structure:
And has a Clustered Columnstore Index (CCI) as well.
As the system catalog view sys.column_store_segments shows, this table is not loaded correctly for segment elimination because of big gaps between min_data_id and max_data_id in each segment:
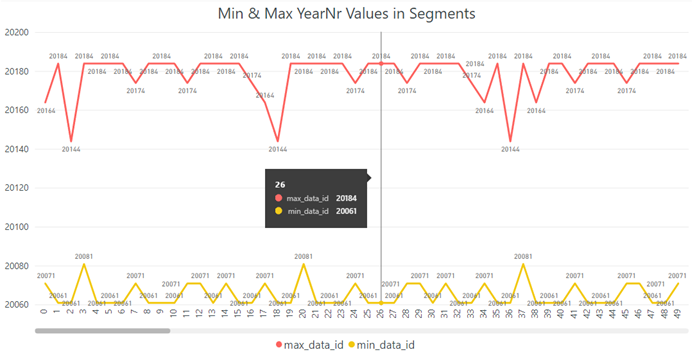
For example, if we run a query for the Q1 in 2012, SQL Server has to read 221 out of 241 segments:
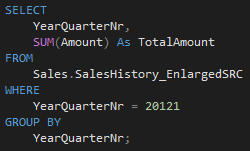
Splitter and data distribution logic:
Our goal is to load data from the table named Sales.SalesHistory_EnlargedSRC into the (currently empty) destination table called Sales.SalesHistory_EnlargedDST (that has the same structure and also CCI) to achieve better segment elimination.
In order to do that, we will have to find an ideal attribute (splitter) in the source table and split the whole data set into smaller batches/chunks that will be processed separately one by one in a loop. The YearQuarterNr attribute looks like a great splitter as this column is not nullable SMALLINT and each Quarter contains approximately 4 million rows.
Let’s analyse data distribution in the source table and split it into smaller batches:
- Get a sorted list of distinct quarters from the source table,
- Calculate the number of records for each quarter,
- Calculate the RunningTotal,
- Calculate the BatchID as RunningTotal / (NumberOfAvailableCores * RowGroupMaxSize)
In our case, we have 4 cores available and as we already know, MaxRowGroupSize = 1048576.
To implement the steps above, I created the following query:
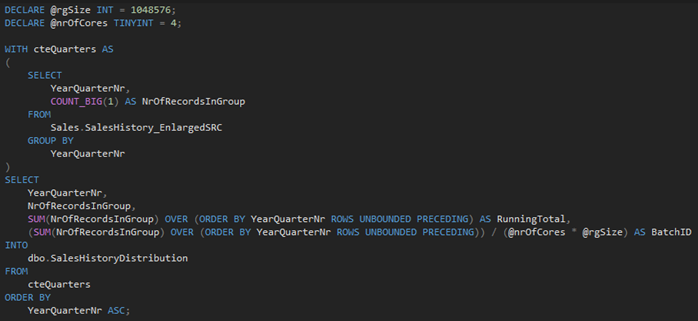
As a result, we get all quarters and their related BatchID:
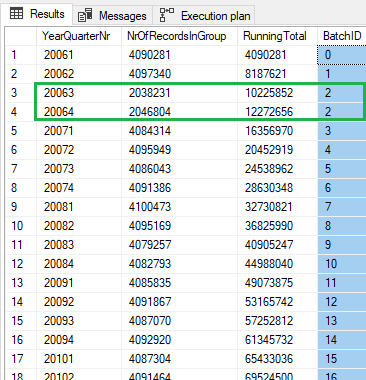
Note: See that quarters 2006 Q3 and 2006 Q4 have approx. 4 million records in total, so they are going to be processed in a single batch with BatchID = 2.
At this point, we know that we are going to load data into the destination table in batches. One option is to implement a stored procedure that loops through the batches and creates dynamic INSERT statements with a filter on the YearQuarterNr attribute.
Here is a part of the source code from our procedure:
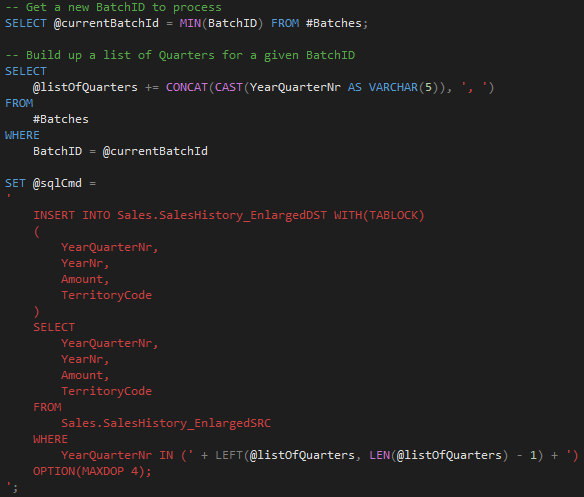
And here you can see one of the dynamically generated INSERT statements – in this case, we have the INSERT statement generated for the BatchID = 2:
From the query properties, we can see that records are evenly distributed between 4 threads as we specified the OPTION(MAXDOP 4) and BatchSize = 4 * MaxRowGroupSize.
Thanks to this setting, rows can go directly into the compressed row groups.
After the stored procedure processed all the batches, we should have data loaded in the destination table and we should also observe better segment elimination.
We can visualize metadata (min_data_id, max_data_id) from the system catalog view sys.column_store_segments:
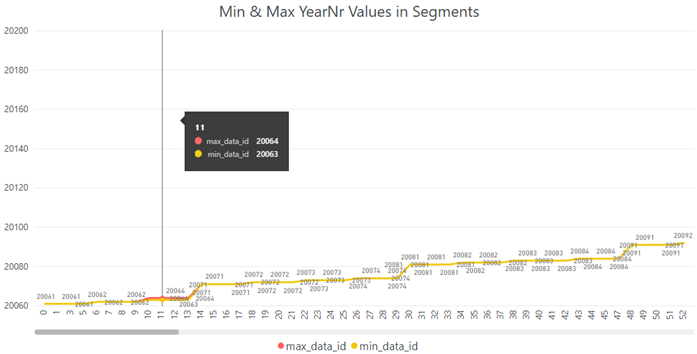
There is almost no difference between min_data_id and max_data_id in each segment so we should be able to achieve a great segment elimination.
Let’s run the same query again, but this time, against the Sales.SalesHistory_EnlargedDST:

In this case, SQL Server had to read only 5 segments compared to the original query where SQL Server had to read 221 segments to return the same result.
Summary
In this blog post, I explained a structure of a columnstore index: a row group in a columnstore index contains a set of rows (each row group can have up to 1 048 576 rows) that are converted to column segments and dictionaries. Column segments and dictionaries are stored on storage (broken down into 8KB pages) as BLOB data.
I also explained what segment elimination process is and that we have to focus on min_data_id and max_data_id values from the sys.column_store_segments catalog view that are used by SQL Server to eliminate any row groups that don’t meet the filter criteria.
When we load a small data set (a few million rows) we can achieve better segment elimination by creating a CCI on top of a table with a clustered index using MAXDOP 1.
When we load a large data set (a few billion rows) we cannot just create a clustered index on a source table due to CPU, disk size limits, etc. But we can achieve better segment elimination by splitting the large data set into smaller batches/chunks based on a splitter attribute, running total and number of available cores – I used the following formula to calculate the BatchID as:
RunningTotal / (NumberOfAvailableCores * RowGroupMaxSize).
Sources
https://www.microsoft.com/en-us/research/wp-content/uploads/2013/06/Apollo3-Sigmod-2013-final.pdf
https://blogs.msdn.microsoft.com/sql_server_team/columnstore-index-performance-rowgroup-elimination/
