

Some time ago I added a script component to a few SSIS packages to compare rows with each other using a hash to check if they had actually changed or not. In the output of the script component, I had chosen a string data type for the calculated hash with a length of 66 characters. In the destination table, I created a column with data type char(66) to store the hash value.

Of course, a few weeks later I had completely forgotten why I had chosen that particular length. That’s why I wrote this blog post, so that I might never forget it again.
In the script component, I used the SHA256CryptoServiceProvider to calculate the hash. When we use the T-SQL equivalent HASHBYTES, it is easy to see the 66 characters:

We have the 64 characters generated by the hash plus the 0x that precedes the hex string. The question is however: where do they come from? The SHA function outputs 256 bits, which equals 32 characters. So why do I have 66 characters instead of 34, knowing that a character takes up one single byte in SQL Server?
I took another look at the code generating the hash:
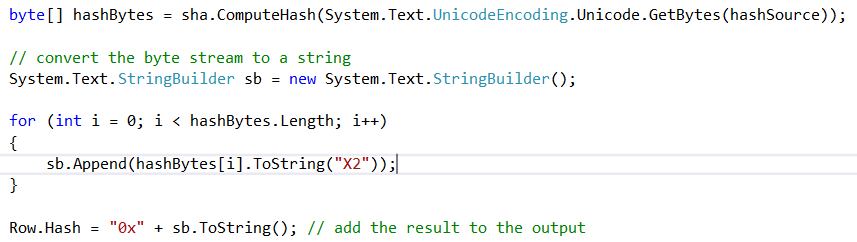
That’s when it hit me: the text input is first encoded the Unicode, so when you directly cast the output hex string to a string, you might get Unicode characters as well. And indeed, when you cast in T-SQL:
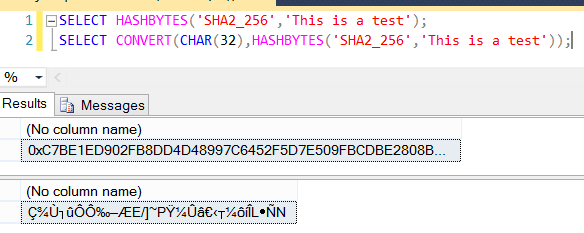
We have our 32 characters, they are only in Unicode. And as you might know, SQL Server uses not one byte to represent Unicode characters, but two bytes. For example, the hexadecimal representation of Ç (capital C with cedilla) is 00C7, or C7 for friends. Two characters indeed.
The for loop in the C# code takes the byte stream generated by the hash output and converts it byte per byte to a string and appends it to the result. This gives us our 66 characters as well.
So, now you know and I hopefully don’t forget.
