

Unlike some other languages, T-SQL doesn’t have the concept of a constant.
As good coders, we’ve all at some point tried to use a SQL variable to hold a constant value within a stored procedure, in order to make our code both more readable and maintainable.
I’ll give you an example. Here I’m querying a Task table, and I want all the rows where the TaskStatus is 0 (zero) which means the Task is Open:
SELECT * FROM dbo.Task WHERE TaskStatus = 0;
If someone else comes along to look at this code they don’t know what the value of zero means. My code’s not clear. Worse I might refer to the same value multiple times in my procedure, so if I need to change it later I have to change it in multiple places.
Good practice from other coding languages would say that I replace it with a meaningfully named constant. As mentioned, in T-SQL we don’t have constants so I’ll compromise and use a variable:
DECLARE @OpenTask tinyint = 0; SELECT * FROM dbo.Task WHERE TaskStatus = @OpenTask;
Now that’s much more readable – right?
Unfortunately it’s also a bad idea in SQL . Let’s see why.
I’ll create the aforementioned Task table, add an index on TaskStatus. Then I’ll add million rows with status 1 (which we’ll call closed) and 1 row with the value 0 (zero) which is open:
CREATE TABLE dbo.Task ( Id INT IDENTITY(1,1) CONSTRAINT PK_Task PRIMARY KEY CLUSTERED, UserId INT, TaskType INT, Payload VARCHAR(255) NOT NULL, TaskStatus tinyint NOT NULL ); GO CREATE INDEX IX_Task_TaskStatus ON dbo.Task(TaskStatus); INSERT INTO dbo.Task (UserId,TaskType,Payload,TaskStatus) SELECT TOP 1000000 1,1,'This Shizzle Is Done',1 FROM sys.objects a, sys.objects b, sys.objects c; INSERT INTO dbo.Task (UserId,TaskType,Payload,TaskStatus) SELECT 1,1,'Do This Shizzle',0;
Once that’s completed I’m going to update the statistics just so we know SQL has the most up to date information to produce an optimal execution plan for our queries:
UPDATE STATISTICS dbo.Task WITH fullscan;
Now let’s go back to our original queries. Before I run them let’s think what we want them to do. We have an index on TaskStatus and we only have one row we are looking for, so we’d hope the query will use the index and go straight to the record. The index doesn’t contain all the columns, but that’s okay. We’re only going to have to output one record so if it has to look up the extra columns up in the clustered index that’ll be pretty damn quick.
Let’s run the first query, we’ll capture the execution plan and the STATISTICS output:
SET STATISTICS io ON; SET STATISTICS time ON; SELECT * FROM dbo.Task WHERE TaskStatus = 0;
Here’s the execution plan:
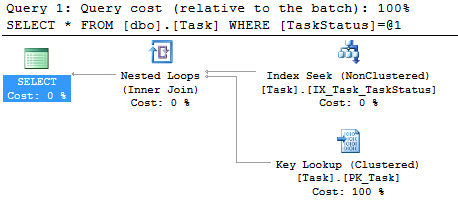
That’s doing exactly what we hoped for, it’s looked up the record in our index using a seek. Then it’s grabbed the rest of the columns from the clustered index using a key lookup.
Here’s the statistics output:
Table ‘Task’. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
So that’s a nice small number of reads and less than a millisecond of CPU.
Now let’s run the “improved” version:
SET STATISTICS io ON; SET STATISTICS time ON; DECLARE @OpenTask tinyint = 0; SELECT * FROM dbo.Task WHERE TaskStatus = @OpenTask;
Here’s the execution plan this time:
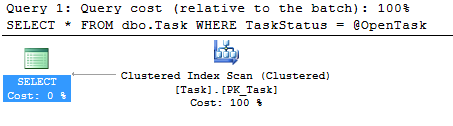
That doesn’t look so good. Let’s check the statistics:
Table ‘Task’. Scan count 1, logical reads 5341, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
CPU time = 109 ms, elapsed time = 96 ms.
Those figures tell us the query has got between 100 and 1,000 times worse. So much for the improved version.
So why is this happening?
The answer is simply that the optimizer doesn’t/can’t look at the values inside variables when a piece of SQL is compiled. Therefore it can’t use the statistics against the indexes on the table to get an accurate idea of how many rows to expect back in the results.
We can see that if we compare the properties of the Index Seek Operator from the first query:
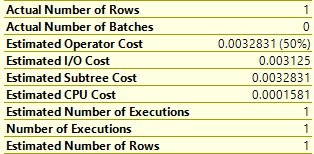
Against the properties for the Index Scan Operator from the second query:

In the first one we can see that the Actual Number of Rows (at the top) exactly matches the Estimated Number of rows (at the bottom). SQL has been able to use the statistics on the index to get an accurate estimate.
In the second this is not the case. We have 500,000 rows estimate, but only 1 actual. This has led SQL down the route of choosing a plan that would have been more effective for 500,000 rows – but is much less effective for 1. In this case it didn’t know what value to optimize for. Lacking that information it used the density value in the statistics and multiplied that by the total number of rows to get the estimate. Or in other words, the statistics tell it that there are two distinct values (0 and 1) in the table. Not knowing which one has been supplied the optimizer figures than on average half the rows will be returned.
So what should do you to make your code clearer?
The simple answer is to use comments, the following is totally clear to its meaning, and will perform optimally:
SELECT * FROM dbo.Task WHERE TaskStatus = 0 -- Open Task;
But what about the maintainability issue, where you may have to refer to the same value multiple times in a given procedure?
Unfortunately you’re just going to have to put up with maintaining the value in multiple places, but in general within a well designed application these should be static values (and hopefully integers) so it shouldn’t be too big a deal.
Note this is not the same for parameters passed to a stored procedure. In that case the queries inside the stored procedure will compile using the values passed the first time the procedure was executed – that can be really useful, but it can also cause its own set of issues to be aware of! Just remember parameters and variables – similar but not the same!

![]()
