

SQL Server 2016 AlwaysOn AG got many improvements, and I’m pretty impressed with the log throughput improvements and redo improvements based on some of my test cases(A detailed blog post on that will follow soon). In this blog post we will look at another key improvement, ie Database Level Health Detection.
SQL Server 2016 enhances the AlwaysOn health diagnostics with database health detection. If AlwaysOn availability group database health detection has been selected for your availability group, and an availability database transitions out of the ONLINE state (sys.databases.state_desc), then entire availability group will failover automatically.
Let’s look at a demo to demonstrate the new behaviour –
I have enabled Database Level Health Detection for my AG as shown below –
 Now, in theory if one of the disks which is hosting my database tpcc is gone(both data/log file), then it should trigger a failover.
Now, in theory if one of the disks which is hosting my database tpcc is gone(both data/log file), then it should trigger a failover.
Currently node 001 is the primary replica. Let’s see, if theory matches with reality.
I went ahead and inserted data continuously to one of the tables in the database, and took the disk(which hosts both data/log files) offline via Disk Management –
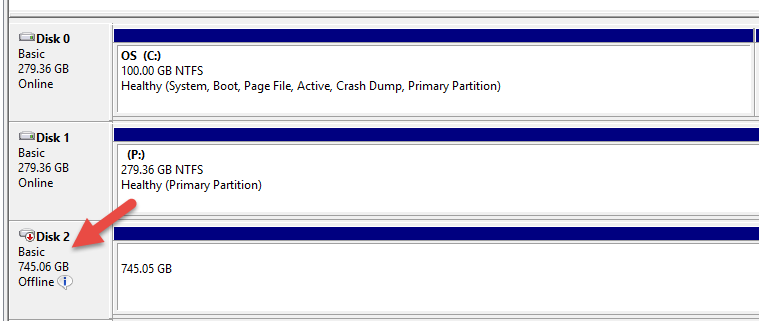
That caused the database to go into Recovery Pending State –
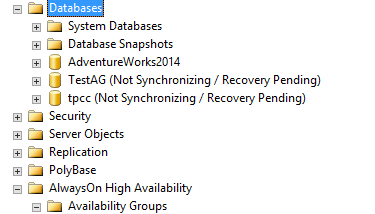
Note – This controlled failure simulation was not a straightforward process. Initially the database was not going to a degraded state. After my interaction with some of the top SQL Server Experts out there in our community, I was able to force the DB go into a degraded state.
Ref this twitter thread for more details – https://twitter.com/AnupWarrier/status/748364014682578949
This immediately caused a failover, and now 002 is the primary replica.

Conclusion –
This proves that Database level health detection works seamlessly and a failover is triggered when the state of a database changes from Online to other degraded states.
Thanks for reading, and keep watching this space for more!
