

This is part of a series on how to take the Adventureworks database and bring it in line with modern standards. How do we put a legacy SQL Server database into source control? What issues do we face and how hard is it? Then how do we build a continuous integration pipeline and possibly move towards continuous deployment. This series takes a look at how we achieve this whilst also implementing some coding standards and making an imperfect database a little bit better.
See the introduction: https://the.agilesql.club/Blog/Ed-Elliott/A-reference-for-creating-a-con...
Getting the code from the database into an SSDT project
why?
Having the code and schema in a database is great, it (should be) backed up, anyone can access it with the correct permissions, it is really open and accessible.
What is not so great is that we don't have a history of changes to the code, we can't easily version the code and the best case scenario for working with the code and making changes is that we have SQL Server management studio and SQL Prompt (Redgate).
We really need to get the code and bring it into a more developer friendly environment and today that format is SSDT.
Requirements
We have a couple of requirements that we must have thought about (there is that damned planning again), the first is where the source control repository is that we will be using, is there an existing one or do we create one?
The second is where the project will sit, is this a database that serves many applications and should have its own solution or is it for a single application and should be a part of that solution?
Decide where the project will live and get the source control sorted, this will determine where you create your SSDT project.
How?
The first step is to create the SSDT project so open Visual Studio and create a new "SQL Server" project, if you do not have Visual Studio, download either the community or express versions depending on your situation and if you do not see the "SQL Server" database project type then download the latest SSDT iso, at time of writing it is available: https://msdn.microsoft.com/en-us/data/hh297027?f=255&MSPPError=-2147217396
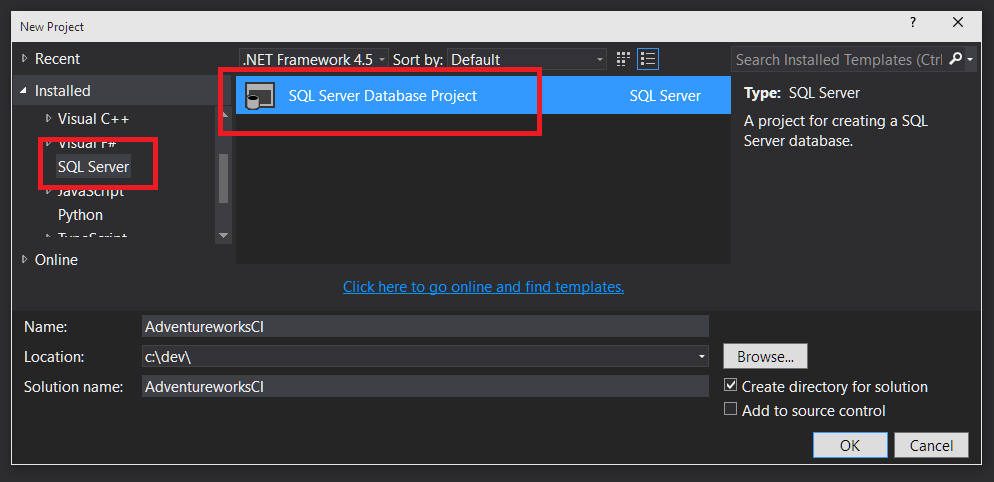
I have already got an instance of Adventureworks OLTP 2012 running locally, I am not going to tell you how to do that as a) it is already pretty well documented and more importantly b) if you follow along with this you should do it with databases that you actually care about, start getting one of your databases into SSDT and source control and show some real business value.
Once you have your new project we will simply do an import so in "Solution Explorer" right click the project, choose "Import" and then "Database...". Note, if you have added any files to the project then you will not have the option to import from anything other than script files so just delete anything or create a new project and then retry:

Create a new connection pointing to your database, I like to tick "Include Database Settings" but you may manage those separately:
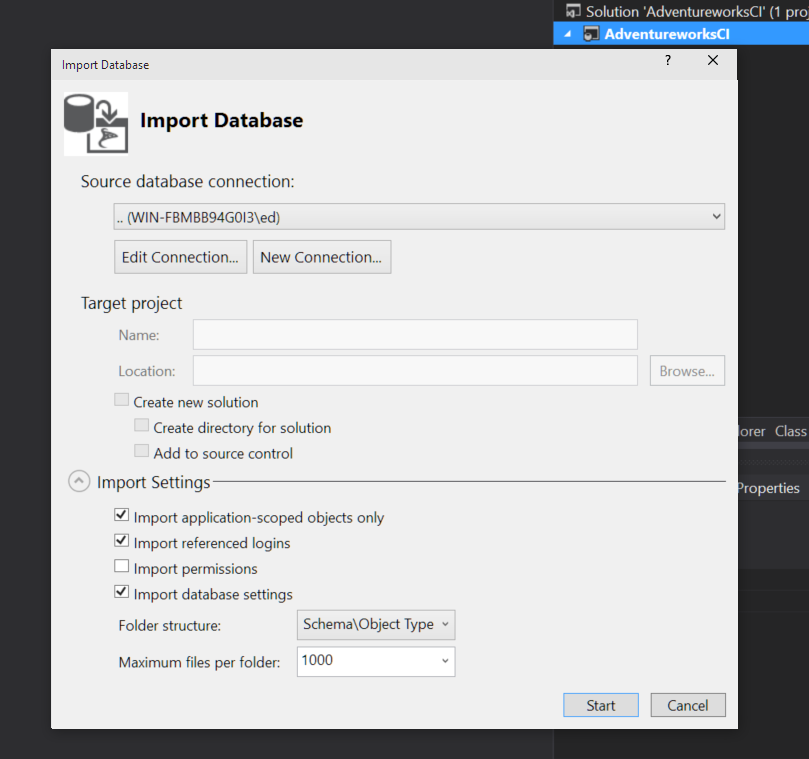
When you are ready click "Start", the wizard will import all of your objects and show you any errors. If you do get any errors at this point it may well be easier to use SSMS to generate scripts of the database and then try to import those, but have a look at the error and see if it is fixable first.
If you have managed to import the database into SSDT you should end up with a list of folders containing schemas and objects and possibly some other .sql files:
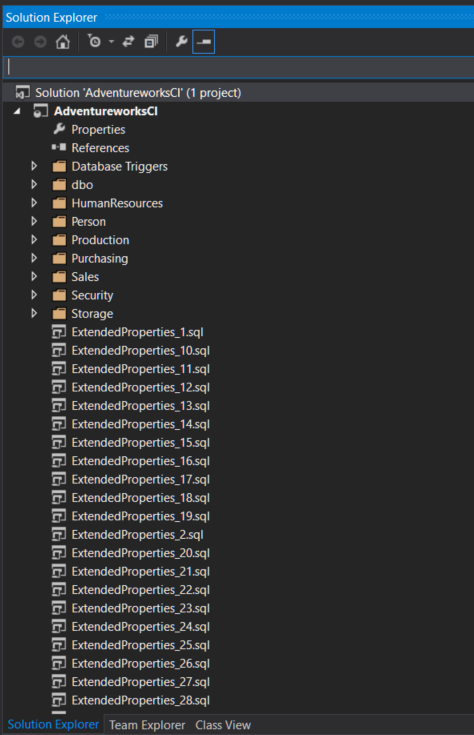
Once you have the code in SSDT you should try to build the project, surprisingly for me, the Adventureworks project builds straight away. This is the first database project I have worked on where that is the case! Typically, you would build at this point and then find lots of errors - if this happens to you don't worry, keep going, it will get better!
So that is it?
Yes, pretty much, you have now taken the major step of getting your code and schema out of a SQL database and into the file system, there is a bit further to go with making it a completely deployable piece of code but it is a great start.
Shall I fix any errors now?
No, don't do that - whether you have build errors or not, check in what you have. The first thing you should do is to check in the code as you have retrieved it from the database without making any changes, don't fix a reference here or delete an old stored procedure here, check in what you have.
The reason is that typically you will need to make changes, you will likely have legacy code that doesn't even compile but it may not compile for a number of reasons so before you make any changes check in what you have, if you are checking into an existing solution maybe take a branch and check it into that and you really must label it to tag it in some way so you can get back to it at a later date should you need it.
I wouldn't normally check in broken code but this is an exception, you really must have the confidence to delete broken unused code and source control gives us this confidence so check it in and be happy with that, it will get better and you will not have to check in broken code for this database forever.
It is checked in now, should I fix any errors now?
Yes if you want to or, considering you now have the code and schema in source control you may want to go and do some sort of celebration dance.
What problems will you get
The main problems you will see are when you have exported the code and you try to compile it, you are likely to see a large number of warnings and errors.
The warnings are quite common and you should have a plan to get rid of them where possible over time, I personally prefer to treat warnings as errors and either fix them or ignore them individually - someone has gone through the effort of writing something to tell you that something isn't as it should, I like to know that one of us has a problem and fix it!
Errors will stop you building the SSDT project which will stop us generating deployment scripts to fix the database so we need to fix the errors first. If you have dependencies on other databases so you have code that looks like: "select col_name from database.schema.table", this will be an unresolved reference and so you will need to get the database that your statement references and also put it into SSDT, in fact anything you reference outside of the current project including system views and procedures in master will need a reference:
http://schottsql.blogspot.co.uk/2012/10/ssdt-external-database-reference...
You can have a single Visual Studio solution and reference each project or you can build a project and reference its dacpac from your project, this is basically how references to master and msdb work, someone at Microsoft built a dacpac for them.
If you have circular references so two databases reference each other then you will need to split out the dependencies and do something like "http://blogs.solidq.com/en/sqlserver/ssdt-how-to-solve-the-circular-refe..." or you may find it simpler to have a single project and deploy the code to multiple databases, either having redundant tables / code in each database or filter the deployments to only include the objects that you are interested in. Whatever you do, if you have cross database calls you should generally try to remove them as they make working with the code harder and their use normally points to other issues such as an architectural issue that should be solved some other way.
My favorite type of code in a new SSDT project is code that is just wrong or references objects that no longer exists and as such do not compile and would never run if called on the SQL Server, as we have our original version in source control you can safely delete the code that doesn't work, go ahead and do that now and smile as you see the bad code go.
Next
That is all for now, hopefully you now have a database project in source control - you may have plenty of errors to fix and warnings to procrastinate over but it is a great toe dip into a sea of CI awesomeness. In the next post I will talk about data and the static data that we have and how we deal with that.
![]()
