

Next, Advent of Code 2018 – Day 6
As I explained in a recent post, I’m participating in this year’s Advent of Code challenge, with the twist of doing the challenges in T-SQL. In case you don’t know what “Advent of Code” is, Eric Wastl (t) created it for the purpose of, as Eric describes it:
Advent of Code is a series of small programming puzzles for a variety of skill levels. They are self-contained and are just as appropriate for an expert who wants to stay sharp as they are for a beginner who is just learning to code. Each puzzle calls upon different skills and has two parts that build on a theme.
The full explanation of “Advent of Code” is at https://adventofcode.com/2018/about. You can see my other posts in the “Advent of Code” category.
2018 Advent of Code recap
We started off with someone going back in time and altering Santa’s past. You went back in time to correct it, but the device to fix the problems hadn’t been calibrated before sending you on your way. You calibrated the device on Day 1. On Day 2, we located the boxes in the warehouse where the new (500 years ago) Santa suit material is. We sliced and diced the material on Day 3, finding the best piece to use. We figured out the best time to sneak into the Santa suit lab on Day 4. On Day 5, we modified the polymers in the Santa suit material.
Day 6 – Part 1
We all know that the shortest distance between two points is a straight line. What if you’re a taxi driver, and you need to deliver someone 6 blocks north and 7 blocks east? A straight line would probably take you through several buildings. In this case, your shortest distance is by grid. In Day 6, this is exactly what we are up against. After fixing the Santa suit, your device takes you another 500 years in the past. Along the way, the device detects chronal interference and gives you a list of grid points.
Thinking that those points are your danger zones, you need to find the largest area within your grid without any of those grid points. You will calculate the distance of all points on the grid from the grid points supplied, using the Manhattan distance calculation. We don’t consider any point that is the same distance from more than one of the supplied points. Additionally, we don’t consider any supplied point that extends indefinitely in any direction.
Side note: I created two different ways of accomplishing this. The procedural (while loop based) method was consistently twice as fast as the set-based method. I’ll be discussing the procedural method, but I will include the set-based method also.
The import file is a list of comma-separated values. The values represented the X-axis and the Y-axis coordinates on the grid. This makes it easy to process the import file:
IF OBJECT_ID('tempdb.dbo.#InputFile') IS NOT NULL DROP TABLE #InputFile;
SELECT ca1.ItemNumber,
MAX(CASE WHEN ca3.ItemNumber = 1 THEN CONVERT(INTEGER, ca3.Item) END) AS X,
MAX(CASE WHEN ca3.ItemNumber = 2 THEN CONVERT(INTEGER, ca3.Item) END) AS Y
INTO #InputFile
FROMOPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day06.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES (REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item)
CROSS APPLY dbo.Split(ca2.Item, ',') ca3
GROUP BY ca1.ItemNumber;Notice that I’m directing this output into a temporary table.
Day 6, Part 1 – Building the grid
Next, I need to build the grid. I use the MAX function to get the largest X and Y coordinate. Following that, I perform two CROSS JOINs to the physical tally table (built in Day 3) to get the proper number of values for both the X-axis and the Y-axis.
DECLARE @GridX INTEGER,
@GridY INTEGER;
SELECT @GridX = MAX(X), @GridY = MAX(Y)
FROM #InputFile;
IF OBJECT_ID('tempdb.dbo.#XYZ') IS NOT NULL DROP TABLE #XYZ;
CREATE TABLE #XYZ (
X INTEGER, -- horizontal axis
Y INTEGER, -- vertical axis
Z VARCHAR(25),
CONSTRAINT PK_XYZ PRIMARY KEY (X, Y));
INSERT INTO #XYZ (X, Y, Z)
SELECT tx.N AS X,
ty.N AS Y,
ISNULL(CONVERT(VARCHAR(13), InFile.ItemNumber),'') AS Z
FROM dbo.Tally tx
CROSS JOIN dbo.Tally ty
LEFT JOIN #InputFile InFile ON tx.N = InFile.X AND ty.N = InFile.Y
WHERE tx.N <= @GridX
AND ty.N <= @GridY;This code creates and populates another temporary table (#XYZ). The Z column is for the value being stored in the point referenced by the X-axis and Y-axis:
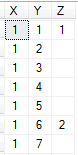
Day 6 Grid
For the next step, I determined the distance from each grid point supplied to the current grid point. I’m storing two bits of data in the Z column for the points that weren’t supplied: the shortest distance, and the grid point that was the closest. I use an asterisk for the grid location if there are more than one grid point that is the shortest distance for that grid location. I separate these two values with a dash. The distance calculation is the absolute value difference between the X-axis and Y-axis points of the supplied location, and the current location. Adding the two values together gets the total distance. A cursor is used to process this – I did mention that this was a procedural method.
DECLARE @X INTEGER, @Y INTEGER, @ItemNumber INTEGER;
DECLARE cCoords CURSOR LOCAL SCROLL READ_ONLY FOR
SELECT X, Y, ItemNumber
FROM #InputFile;
OPEN cCoords;
FETCH FIRST FROM cCoords INTO @X, @Y, @ItemNumber;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE XYZ
SET Z = CASE WHEN caCur.posDash > 0 AND caPast.Distance < caCur.Distance
THEN XYZ.Z
WHEN caCur.posDash > 0 AND caPast.Distance = caCur.Distance
THEN CONVERT(VARCHAR(15), caCur.Distance) + '-*'
ELSE caCur.Z
END
FROM #XYZ XYZ
CROSS APPLY (VALUES (ABS(XYZ.X-@X) + ABS(XYZ.Y-@Y),
CONVERT(VARCHAR(15), ABS(XYZ.X-@X) + ABS(XYZ.Y-@Y)) +
'-' + CONVERT(VARCHAR(10), @ItemNumber),
CHARINDEX('-', XYZ.Z))) caCur(Distance, Z, posDash)
CROSS APPLY (VALUES (CASE WHEN caCur.posDash > 0
THEN CONVERT(INTEGER, LEFT(XYZ.Z, caCur.posDash-1))
ELSE 0
END,
CASE WHEN caCur.posDash > 0
THEN CONVERT(INTEGER, SUBSTRING(XYZ.Z, caCur.posDash+1, 25))
ELSE 0
END)) caPast(Distance, ItemNumber)
WHERE (XYZ.Z = ''
OR XYZ.Z LIKE '%-%')
FETCH NEXT FROM cCoords INTO @X, @Y, @ItemNumber;
END; -- WHILE @@FETCH_STATUS = 0
CLOSE cCoords;
DEALLOCATE cCoords;Day 6, Part 1 – Determining the number of grid points in the largest region
This final step is to process the grid to determine the largest region.
SELECT TOP 1 COUNT(*) + 1 AS Part1Answer
FROM #XYZ
CROSS APPLY (VALUES (SUBSTRING(Z, CHARINDEX('-', Z)+1, 50),
CONVERT(INTEGER, LEFT(Z, CHARINDEX('-', Z) - 1))
)) ca(ItemNumber, Distance)
WHERE ca.ItemNumber NOT IN (
SELECT DISTINCT SUBSTRING(Z, CHARINDEX('-', Z)+1, 50) AS ItemNumber
FROM #XYZ
-- these XY locations go to infinity, so don't include those.
WHERE (X=1 OR Y=1 OR X=@GridX OR Y=@GridY)
-- don't include locations w/ multiple locations being same distance
AND Z NOT LIKE '*%')
AND Z LIKE '%-%' -- not an original grid location
AND Z NOT LIKE '%-*' -- not a multiple same distance
GROUP BY ca.ItemNumber
ORDER BY COUNT(*) DESC;The where clause excludes the supplied grid locations that will go to infinity, and those where there are multiple locations for the shortest distance. After extracting the supplied grid location that is the shortest distance to the grid points, I group on this value to get the number of grid points that are the closest to the supplied location.
Day 6, Part 1 – the Set based solution
The Set-based solution for the cursor and the result is:
WITH cte1 AS
( -- For every plot on the grid, calculate the distance from every
-- assigned plot. Get the number of plots at each distance.
SELECT t1.X, t1.Y, ca.Distance, t2.ItemNumber,
COUNT(*) OVER (PARTITION BY t1.X, t1.Y, ca.Distance) AS Counter
FROM #XYZ t1
CROSS JOIN #XYZ t2
CROSS APPLY (VALUES (ABS(t1.X - t2.X) + ABS(t1.Y - t2.Y))) ca(Distance)
WHERE t2.ItemNumber IS NOT NULL
), cte2 AS
( -- Rank the data - the closest distance will be #1
SELECT X, Y, Distance, ItemNumber, Counter,
RN = RANK() OVER (PARTITION BY X, Y ORDER BY Distance, Counter)
FROM cte1
), cte3 AS
( -- get the closest distance if there's only one plot closest to it.
SELECT X, Y, Distance, ItemNumber
FROM cte2
WHERE RN = 1
AND Counter = 1
), cte4 AS
( -- exclude the Items that go to infinity - those on the outer ring of the grid
SELECT *
FROM cte3
WHERE ItemNumber NOT IN (
SELECT DISTINCT ItemNumber
FROM cte3
WHERE (X=1 OR X=@GridX OR Y = 1 OR Y = @GridY))
)
-- Get the largest grid
SELECT TOP (1) COUNT(*) AS Part1Answer
FROM cte4
GROUP BY ItemNumber
ORDER BY COUNT(*) DESC;Day 6, Part 2
For Part 1, we assumed that the supplied locations were for the dangerous spots, and we were trying to get as far away from them as possible. In Part 2, we are assuming that those locations are for the safest locations, so we want to find the region nearest the most number of supplied locations. For this puzzle, I calculate the distance between each supplied location on the grid, and the current grid point, and get those locations where the total is less than 10,000. Finally, a simple set-based solution, based on the #XYZ table already created and populated, gets the result that we need:
SELECT COUNT(*) AS Part2Answer
FROM (
SELECT t1.X, t1.Y, SUM(ca.Distance) Distance
FROM #XYZ t1
CROSS JOIN #XYZ t2
CROSS APPLY (VALUES (ABS(t1.X - t2.X) + ABS(t1.Y - t2.Y))) ca(Distance)
WHERE t2.Z NOT LIKE '%-%'
GROUP BY t1.X, t1.Y
HAVING SUM(ca.Distance) < 10000
) RequiredAlias;In this query, we get the total distance from all supplied grid locations for every grid point. The #XYZ table (t1) gets all grid points, and the #XYZ (t2) gets just the supplied locations. Next, group by the X-axis and Y-axis, and get just those grid points where this total is < 10,000. Finally, count the number of grid points that are in this region.
Summary
And here we have a T-SQL solution for Day 5 of the Advent of Code challenge. The key tasks that we can learn from today are:
- Loading a file.
- Splitting a string on a delimiter.
- Extracting data from a string.
- While loops.
- Using a physical tally table.
The post Advent of Code 2018 – Day 6 (Chronal Coordinates) appeared first on Wayne Sheffield.
