

I was surprised to find out that a lot people hadn’t heard about the new join type, Adaptive join. So, I figured I could do a quick overview.
Adaptive Join Behavior
Currently the adaptive join only works with columnstore indexes, but according to Microsoft, at some point, they will also work with rowstore. The concept is simple. For larger data sets, frequently (but not always, let’s not try to cover every possible caveat, it depends, right), a hash join is much faster than a loops join. For smaller data sets, frequently, a loops join is faster. Wouldn’t it be nice if we could change the join type, on the fly, so that the most effective join was used depending on the data in the query. Ta-da, enter the adaptive join.
First, the statistics are used at compile time for the tables we’re joining. Based on those statistics, a row target it set. Below that threshold, a loops join will be used. Above that threshold, a hash join. The way the row count is determined is that the operator will always build the hash table. With the hash table built and loaded, it will know how many rows it has. If it’s going to do a loops join, the hash table is tossed and a loops join commences. If the threshold has been passed on the row counts and it’s going to do a hash join, it already has the hash table built and proceeds to do a hash join. It’s easy to understand. Let’s see it in action.
Adaptive Join in Action
First, let’s create a columnstore index inside AdventureWorks:
CREATE NONCLUSTERED COLUMNSTORE INDEX csTest ON Production.TransactionHistory (ProductID, Quantity, ActualCost);
With that in place, we can run a query that looks like this:
DECLARE @quantity INT;
SET @quantity = 9726;
SELECT p.Name,
COUNT(th.ProductID) AS CountProductID,
SUM(th.Quantity) AS SumQuantity,
AVG(th.ActualCost) AS AvgActualCost
FROM Production.TransactionHistory AS th
JOIN Production.Product AS p
ON p.ProductID = th.ProductID
WHERE th.Quantity = @quantity
GROUP BY th.ProductID,
p.Name;
SET @quantity = 1;
SELECT p.Name,
COUNT(th.ProductID) AS CountProductID,
SUM(th.Quantity) AS SumQuantity,
AVG(th.ActualCost) AS AvgActualCost
FROM Production.TransactionHistory AS th
JOIN Production.Product AS p
ON p.ProductID = th.ProductID
WHERE th.Quantity = @quantity
GROUP BY th.ProductID,
p.Name;What we have are two instances of the same query, just passing in two different values to get two different result sets. The first returns one row, the second returns 229 rows. Let’s look at the estimated execution plan for the query:
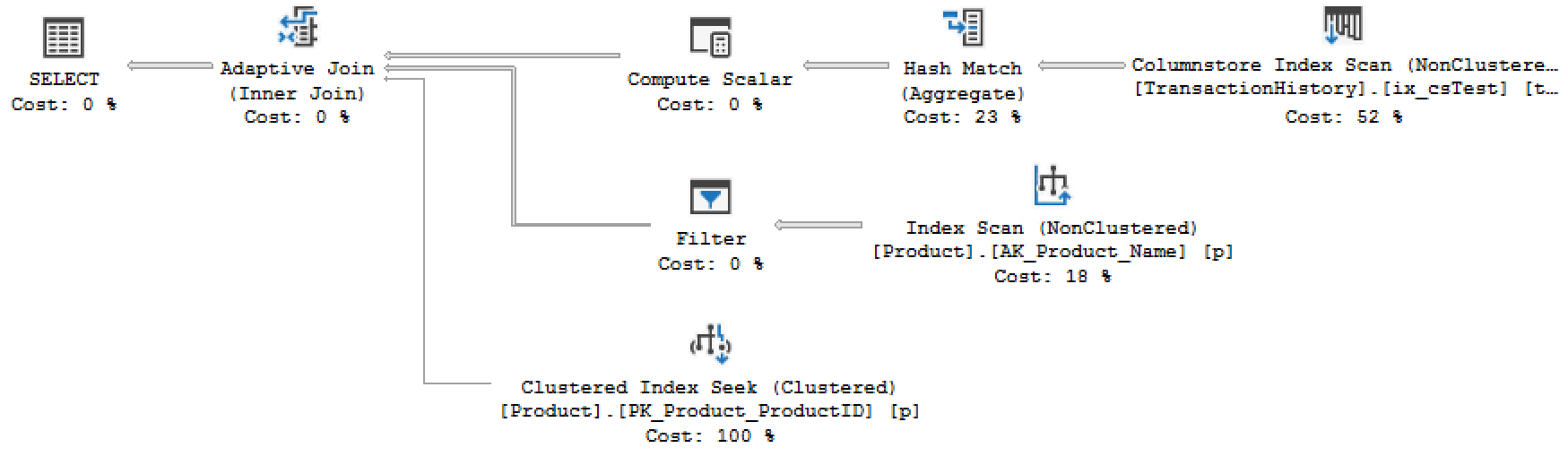
Reading the plan in the logical processing order, the Adaptive Join operator is the first operator on the left after the SELECT operator (which, by the way, technically isn’t an operator, but doesn’t really have any other name, so…). The key to understanding how to read an Adaptive Join is to know that the two paths displayed below it represent, going down, the hash join path and the loops join path. In this case then, the hash join path would have an Index Scan and a Filter operator while the loops path would have just a Clustered Index Seek.
To see the threshold, we just have to go to the properties of the Adaptive Join operator:

In this instance then, the threshold is 11.4837 rows. Basically 11 rows or less you’ll get a loops join (and the lower path), 12 rows or greater and you get a hash join (and the upper path).
Looking at an estimated plan, you can’t see which path it took. You have to look at the actual plan. So, if we capture the plans for the query above, they look like this:
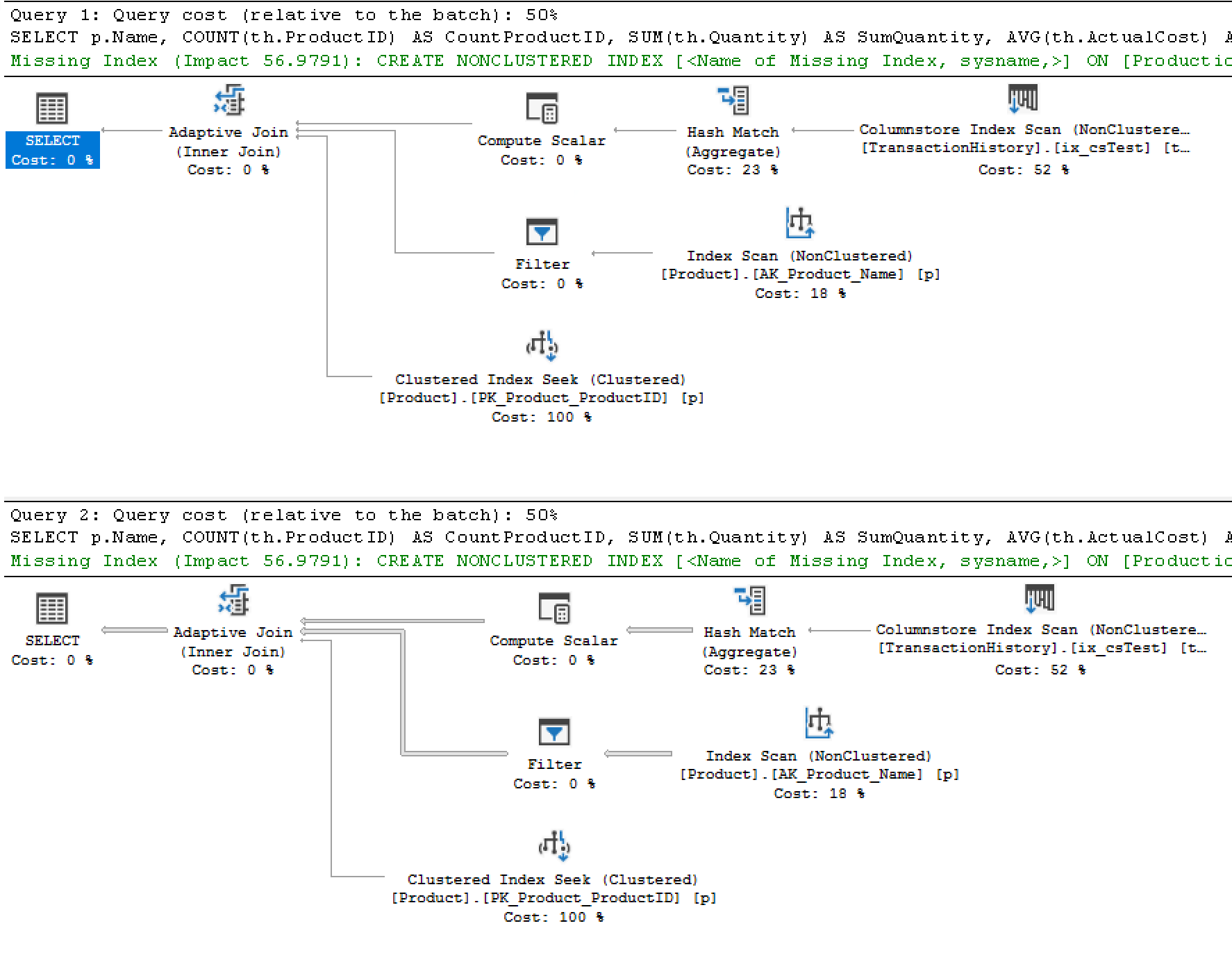
Just looking at the graphical plan, you only have one clue as to which path may have been taken. In the second, lower, plan, you can see that the pipes to the top input of the Adaptive Join operator are much thicker than they are in the first plan. That indicates data being moved, so can assume that was the path. However, to know for sure, you have to look at the properties to see the Actual Number of Rows being processed by the operators. If it’s zero for one of the paths, then the other path was chosen. You can’t get a situation where there will be values in both paths. It will always use a single path.
Conclusion
There are quite a bit more details to the implantation, but you can now see the basics. An adaptive join helps performance quite a lot. The nature of having to build the hash table before the path is picked does mean that the loops join path won’t be as fast as a natural loops join, but who cares. We’re optimizing joins on the fly now, with no code or structure changes needed. That’s pretty cool and very handy.
I’ve got several upcoming day long seminars around the country. First, in Richmond, on March 23, 2018, I’m doing a precon for SQLSaturday Richmond on the topic of tools for query tuning. There are only a couple of seats left, so move quickly and register here.
I’m proud to announce that I’m also going to be doing this same pre-con for SQLSaturday Philadelphia on April 20, 2018. You can sign up here for that event.
In what seems to be turning into a tour of the Eastern Seaboard, I am also doing this precon for SQLSaturday NYC on May 18, 2018. Go here to register for that event. Seats here are again limited and going fast, so don’t wait if you want to get your learn on.
The post Adaptive Joins appeared first on Grant Fritchey.
![]()
