

Background
This article will follow a practical approach to choose the right candidate for clustered index. It’ll investigate through the best practices recommended for clustered index, with the help of an experiment.
Primary Key and Clustered Index
Primary Key and Clustered Index are different from each other. Clustered Index should not be confused with Primary Key. Primary Key can be created with / without Clustered / Nonclustered Index.
Description of terminologies used
Natural Clustered Key: Column or set of columns forming the clustered index, naturally part of table having some business meaning associated with it.
Surrogate Clustered Key: Artificial column such as Identity or uniqueidentifier column, forming the clustered index. We’ve used Identity column as Surrogate Clustered Key in our experiment.
Clustered Index best practices
- It should be as narrow as possible in terms of the number of bytes it stores.
- It should be unique to avoid SQL Server to add Uniquefier to duplicate key values.
- It should be static, ideally, never updated like Identity column.
- It should be ever-increasing, like Identity column to avoid fragmentation and improve the write performance.
Why should we always have a Clustered Index?
- Clustered Index out-performs NonClustered Index, since it stores the data for every row. Data page is stored in the leaf node of the Clustered Index.
- Data is sorted based on clustered index key values and then stored.
- The only time the data is stored in sorted order when the table contains a clustered index. Sort operation is most costly operator in SQL Server.
- Since data is stored in sorted order, hence sorting on the clustered key column avoids the sort operator, and makes it best choice for sorting.
- It helps the Database engine to lock a particular row, instead of a Page or a Table. Row level locking can be only achieved if table has Clustered Index. SQL Server applies lock on Row, Page or Table to ensure consistency.
What should be our Clustered Index?
By looking at the best practices, it’s very hard to find a Natural Key that can satisfy all the four recommendations.
Prima facie, it seems Surrogate Key, such as an Identity column seems to be the only best candidate for Primary Key.
Wait, if Surrogate Key is the best candidate then how to deal with following overheads?
How to minimize Sorting overhead?
Clustered Index column should be referred in Sort operation in the same sort order as defined in the index. Surrogate Key for e.g. Identity column is hardly the sorting requirement.
How to minimize Lock escalation – Page or Table lock?
All the DELETE and UPDATE should happen on Clustered Index Key column. There is hardly a requirement to delete / update based on Surrogate Key.
Alternate approach could be – take all the clustered key column values in a temp table and then using join or sub-query use it in delete / update statement. This is an additional overhead.
How to avoid Key Lookup?
Create nonclustered covering index. This is another overhead.
What we’ll achieve through this experiment?
We’ll compare the following parameters. It’ll be then left to us to decide what best suits to us, depending upon the requirement and workload.
- Execution Time
- Avg. Read Execution Time
- Avg. Write Execution Time
- Index size and read/write count
- Index size (KB)
- num_of_writes
- num_of_reads
- Lock/Latch count/wait count/wait time
- row_lock_count
- page_lock_count
- page_lock_wait_count
- page_lock_wait_in_ms
- index_lock_promotion_attempt_count
- page_latch_wait_count
- page_latch_wait_in_ms
- tree_page_latch_wait_count
- tree_page_latch_wait_in_ms
- Index usage stats
- user_seeks
- user_scans
- user_updates
Workload considered for this test
IoT (Internet of Things) and IIot (Industrial Internet of Things) domains are leading domains. These domains deals with huge volume of data. Data volume is huge in both read as well write, since it deals with machines.
A machine has multiple components and every components has multiple sensors and every sensor sends multiple messages per seconds/milliseconds.
Timestamp is the key attribute for the calculation of the KPI’s to show the real-time analytics.
We’ll have a very simple example with one table, that holds the Coffee Vending Machine’s Sensor Data. Every second, 1000’s of records of multiple machines gets written into this table. The scenario here pertains to an application which gets refreshed every 10 seconds and reads past few minutes of data to render analytics over the UI.
Following aspects are considered in the workload:
- Committed Read to reproduce the locking
- Uncommitted Read / Dirty Read
- Insert new rows
- Update existing rows to simulate the Lock Escalation
- Concurrency with the help of 2 jobs each for both read and write
Script of table schema
CREATE TABLE Coffee_Vending_Machine_Data
(
ID NUMERIC IDENTITY(1,1) NOT NULL
, Date_Time DATETIME
, MachineID INT
, Sensor1_Value INT
, Sensor2_Value INT
, Sensor3_Value INT
, Sensor4_Value INT
)
Script to load table with lot of data
SET NOCOUNT ON
DECLARE @RowID INT = 1
, @MachineID INT
, @Date_Time DATETIME
, @Sensor1_Value INT
, @Sensor2_Value INT
, @Sensor3_Value INT
, @Sensor4_Value INT
WHILE (@RowID <= 1773885)
BEGIN
SET @Date_Time = GETDATE();
SET @MachineID = ROUND((RAND() * 10), 0)
SET @Sensor1_Value = ROUND((RAND() * 100), 0)
SET @Sensor2_Value = ROUND((RAND() * 100), 0)
SET @Sensor3_Value = ROUND((RAND() * 100), 0)
SET @Sensor4_Value = ROUND((RAND() * 100), 0)
INSERT INTO Coffee_Vending_Machine_Data (Date_Time, MachineID, Sensor1_Value, Sensor2_Value, Sensor3_Value, Sensor4_Value)
VALUES (@Date_Time, @MachineID, @Sensor1_Value, @Sensor2_Value, @Sensor3_Value, @Sensor4_Value)
SET @RowID = @RowID + 1;
END
Other prerequisites
Script of table to log the execution time
CREATE TABLE log_simulation_job_execution ( LogIDINT NOT NULL IDENTITY(1,1) , JobNameVARCHAR(100) , Start_DateTimeDATETIME , End_DateTimeDATETIME , Duration_MSAS DATEDIFF(MS, Start_DateTime, End_DateTime) )
Script of Read Stored Procedure
CREATE PROCEDURE [dbo].[usp_read_sensor_data] ( @Start_Date_TimeDATETIME ) AS BEGIN SET NOCOUNT ON; DECLARE @Job_Start_DateTimeDATETIME , @Job_End_DateTimeDATETIME; SET @Job_Start_DateTime = GETDATE(); SELECT AVG(Sensor1_Value) , MIN(Sensor2_Value) , MAX(Sensor3_Value) , AVG(Sensor4_Value) , COUNT(1) FROM Coffee_Vending_Machine_Data (NOLOCK) WHERE MachineID = FLOOR(RAND() * 10) AND Date_Time BETWEEN @Start_Date_Time AND DATEADD(MINUTE, FLOOR(RAND() * 10), @Start_Date_Time); SET @Job_End_DateTime = GETDATE(); INSERT INTO log_simulation_job_execution ( JobName , Start_DateTime , End_DateTime ) VALUES ( 'Simulate_Read_Load' , @Job_Start_DateTime , @Job_End_DateTime ); END
Script of Write Stored Procedure
CREATE PROCEDURE [dbo].[usp_write_sensor_data] AS BEGIN SET NOCOUNT ON; DECLARE @Job_Start_DateTimeDATETIME , @Job_End_DateTimeDATETIME; SET @Job_Start_DateTime = GETDATE(); DECLARE @RowIDINT = 1 , @MachineIDINT , @Date_TimeDATETIME , @Sensor1_ValueINT , @Sensor2_ValueINT , @Sensor3_ValueINT , @Sensor4_ValueINT; DECLARE @Sensor1_Value_Avg INT , @Sensor2_Value_Avg INT , @Sensor3_Value_Avg INT , @Sensor4_Value_Avg INT , @Machine_ID_MinINT , @Machine_ID_MaxINT; SELECT @Sensor1_Value_Avg=AVG(Sensor1_Value) , @Sensor2_Value_Avg =AVG(Sensor2_Value) , @Sensor3_Value_Avg =AVG(Sensor3_Value) , @Sensor4_Value_Avg =AVG(Sensor4_Value) , @Machine_ID_Min=MIN(MachineID) , @Machine_ID_Max=MAX(MachineID) FROM Coffee_Vending_Machine_Data; WHILE (@RowID <= 1000) BEGIN SET @Date_Time = GETDATE(); SET @MachineID = ROUND((RAND() * 10), 0) SET @Sensor1_Value = ROUND((RAND() * 100), 0) SET @Sensor2_Value = ROUND((RAND() * 100), 0) SET @Sensor3_Value = ROUND((RAND() * 100), 0) SET @Sensor4_Value = ROUND((RAND() * 100), 0) INSERT INTO Coffee_Vending_Machine_Data (Date_Time, MachineID, Sensor1_Value, Sensor2_Value, Sensor3_Value, Sensor4_Value) VALUES (@Date_Time, @MachineID, @Sensor1_Value, @Sensor2_Value, @Sensor3_Value, @Sensor4_Value) SET @RowID = @RowID + 1; END -- This UPDATE statement may not make sense, but still keeping it here, to properly simulate the READ/WRITE overhead. UPDATE Coffee_Vending_Machine_Data SET Sensor1_Value=Sensor1_Value + @Sensor1_Value_Avg , Sensor2_Value=Sensor2_Value + @Sensor2_Value_Avg , Sensor3_Value=Sensor3_Value + @Sensor3_Value_Avg , Sensor4_Value=Sensor4_Value + @Sensor4_Value_Avg WHERE MachineID BETWEEN @Machine_ID_Min AND @Machine_ID_Max AND @Date_Time BETWEEN @Job_Start_DateTime AND GETDATE(); SET @Job_End_DateTime = GETDATE(); INSERT INTO log_simulation_job_execution ( JobName , Start_DateTime , End_DateTime ) VALUES ( 'Simulate_Write_Load' , @Job_Start_DateTime , @Job_End_DateTime ); END
Script of Read Job 1
USE [msdb]
GO
/****** Object: Job [Simulate_Read_Load] ******/BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
/****** Object: JobCategory [[Uncategorized (Local)]] ******/IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Simulate_Read_Load',
@enabled=0,
@notify_level_eventlog=0,
@notify_level_email=0,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'No description available.',
@category_name=N'[Uncategorized (Local)]',
@owner_login_name=<your owner login name>, @job_id = @jobId OUTPUT
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
/****** Object: Step [1] ******/EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'1',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'DECLARE @Date_TimeDATETIME
SELECT @Date_Time = MIN(Date_Time)
FROM Coffee_Vending_Machine_Data
EXEC [dbo].[usp_read_sensor_data] @Start_Date_Time = @Date_Time;
',
@database_name=N'MyDB',
@flags=0
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 10 second',
@enabled=1,
@freq_type=4,
@freq_interval=1,
@freq_subday_type=2,
@freq_subday_interval=10,
@freq_relative_interval=0,
@freq_recurrence_factor=0,
@active_start_date=20200412,
@active_end_date=99991231,
@active_start_time=0,
@active_end_time=235959,
@schedule_uid=N'e041a22f-3c9f-4009-8974-5496f4536bf7'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO
Script of Read Job 2
USE [msdb]
GO
/****** Object: Job [Simulate_Read_Load_2] ******/BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
/****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 4/25/2020 5:58:59 PM ******/IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Simulate_Read_Load_2',
@enabled=0,
@notify_level_eventlog=0,
@notify_level_email=0,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'No description available.',
@category_name=N'[Uncategorized (Local)]',
@owner_login_name=<your owner login name>, @job_id = @jobId OUTPUT
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
/****** Object: Step [1] ******/EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'1',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'DECLARE @Date_TimeDATETIME
SELECT @Date_Time = MIN(Date_Time)
FROM Coffee_Vending_Machine_Data
EXEC [dbo].[usp_read_sensor_data] @Start_Date_Time = @Date_Time;
',
@database_name=N'MyDB',
@flags=0
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 10 second',
@enabled=1,
@freq_type=4,
@freq_interval=1,
@freq_subday_type=2,
@freq_subday_interval=10,
@freq_relative_interval=0,
@freq_recurrence_factor=0,
@active_start_date=20200412,
@active_end_date=99991231,
@active_start_time=0,
@active_end_time=235959,
@schedule_uid=N'e041a22f-3c9f-4009-8974-5496f4536bf7'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO
Script of Write Job 1
USE [msdb]
GO
/****** Object: Job [Simulate_Write_Load] ******/BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
/****** Object: JobCategory [[Uncategorized (Local)]] ******/IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Simulate_Write_Load',
@enabled=0,
@notify_level_eventlog=0,
@notify_level_email=0,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'No description available.',
@category_name=N'[Uncategorized (Local)]',
@owner_login_name=<your owner login name>, @job_id = @jobId OUTPUT
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
/****** Object: Step [1] ******/EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'1',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'EXEC [dbo].[usp_write_sensor_data]',
@database_name=N'MyDB',
@flags=0
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 10 seconds',
@enabled=1,
@freq_type=4,
@freq_interval=1,
@freq_subday_type=2,
@freq_subday_interval=10,
@freq_relative_interval=0,
@freq_recurrence_factor=0,
@active_start_date=20200412,
@active_end_date=99991231,
@active_start_time=0,
@active_end_time=235959,
@schedule_uid=N'9a6a8f7f-f2b6-4fb5-8e2d-4058b1cb71b5'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO
Script of Write Job 2
USE [msdb]
GO
/****** Object: Job [Simulate_Write_Load_2] Script Date: 4/25/2020 5:58:27 PM ******/BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
/****** Object: JobCategory [[Uncategorized (Local)]] ******/IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Simulate_Write_Load_2',
@enabled=0,
@notify_level_eventlog=0,
@notify_level_email=0,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'No description available.',
@category_name=N'[Uncategorized (Local)]',
@owner_login_name=<your owner login name>, @job_id = @jobId OUTPUT
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
/****** Object: Step [1] ******/EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'1',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'EXEC [dbo].[usp_write_sensor_data]',
@database_name=N'MyDB',
@flags=0
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 10 seconds',
@enabled=1,
@freq_type=4,
@freq_interval=1,
@freq_subday_type=2,
@freq_subday_interval=10,
@freq_relative_interval=0,
@freq_recurrence_factor=0,
@active_start_date=20200412,
@active_end_date=99991231,
@active_start_time=0,
@active_end_time=235959,
@schedule_uid=N'9a6a8f7f-f2b6-4fb5-8e2d-4058b1cb71b5'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO
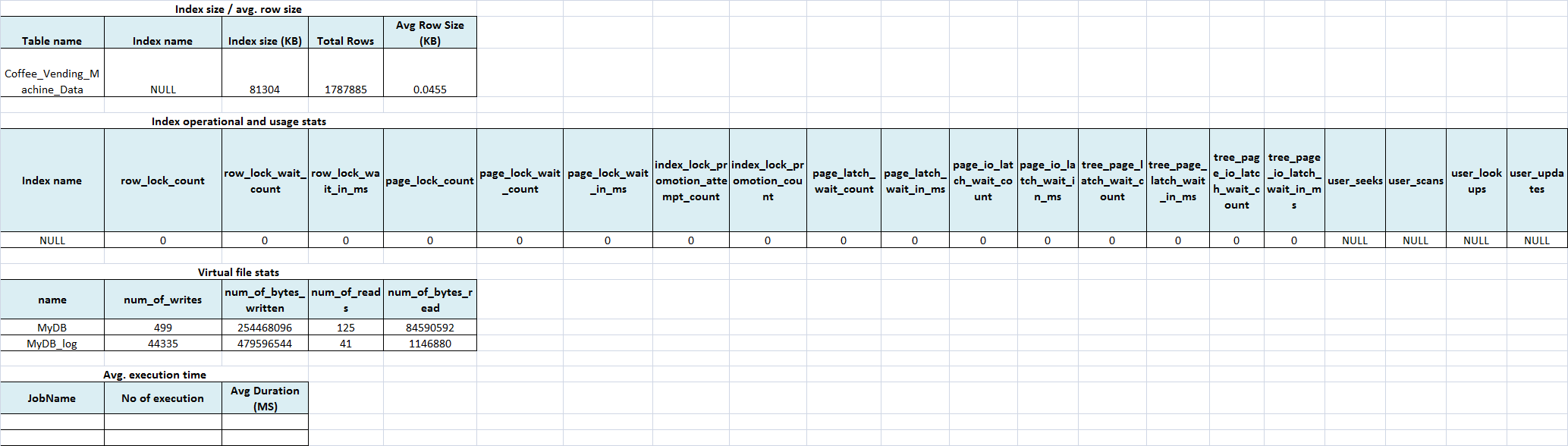
Stats script 1 – Index size / avg. row size
SELECT tn.[name] AS [Table name], ix.[name] AS [Index name] , SUM(sz.[used_page_count]) * 8 AS [Index size (KB)] , SUM(sz.row_count) AS [Total Rows] , CAST((SUM(sz.[used_page_count]) * 8.00) / SUM(sz.row_count) AS NUMERIC(10,4)) AS [Avg Row Size (KB)] FROM sys.dm_db_partition_stats AS sz INNER JOIN sys.indexes AS ix ON sz.[object_id] = ix.[object_id] AND sz.[index_id] = ix.[index_id] INNER JOIN sys.tables tn ON tn.OBJECT_ID = ix.object_id WHERE tn.[name] = 'Coffee_Vending_Machine_Data' GROUP BY tn.[name], ix.[name] ORDER BY tn.[name]
Stats script 2 – Index operational and usage stats
SELECT ix.[name] AS [Index name], stat.row_lock_count, stat.row_lock_wait_count
, stat.row_lock_wait_in_ms, stat.page_lock_count, stat.page_lock_wait_count, stat.page_lock_wait_in_ms
, stat.index_lock_promotion_attempt_count, stat.index_lock_promotion_count, stat.page_latch_wait_count
, stat.page_latch_wait_in_ms, stat.page_io_latch_wait_count, stat.page_io_latch_wait_in_ms
, stat.tree_page_latch_wait_count, stat.tree_page_latch_wait_in_ms, stat.tree_page_io_latch_wait_count
, stat.tree_page_io_latch_wait_in_ms
, ustat.user_seeks, ustat.user_scans, ustat.user_lookups, ustat.user_updates
FROM sys.dm_db_index_operational_stats(DB_ID(),OBJECT_ID('Coffee_Vending_Machine_Data'),-1,0) stat
LEFT JOIN sys.dm_db_index_usage_stats ustat
ON ustat.object_id = stat.object_id
AND ustat.index_id = stat.index_id
INNER JOIN sys.indexes AS ix
ON stat.[object_id] = ix.[object_id]
AND stat.[index_id] = ix.[index_id]
INNER JOIN sys.tables tn
ON tn.OBJECT_ID = ix.object_id
Stats script 3 – Virtual file stats
SELECT files.name, stat.num_of_writes, stat.num_of_bytes_written, stat.num_of_reads, stat.num_of_bytes_read FROM sys.dm_io_virtual_file_stats(DB_ID(),NULL) stat INNER JOIN sys.sysfiles files ON files.fileid = stat.file_id
Stats script 4 – Avg. execution time
SELECT JobName, COUNT(1) AS [No of execution], AVG(Duration_MS) AS [Avg Duration (MS)] FROM log_simulation_job_execution (NOLOCK) GROUP BY JobName
Server Configuration used for this test
This test has been performed on the server with following configurations.
- OS : Windows Server 2019 Datacenter 10.0 <X64> (Build 17763: ) (Hypervisor)
- SQL Server : SQL Server 2019 Developer Edition (64-bit)
- RAM : 4 GB
- Cores : 2 Virtual Cores
- Disk Performance (Estimated)
- IOPS limit : 500
- Throughput limit (MB/s) : 60
- On-Premises/Cloud : Azure Cloud
Pre-test stats

Note: Keep all the jobs Disabled.
Execution#1 with Surrogate Clustered Key (without nonclustered index)
Create the index using below query.
CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data (ID)
Enable all the jobs and disable it after 2 minutes. Once all the jobs are disabled, run the stats select queries.

Execution#2 with Surrogate Clustered Key (with nonclustered non covering index)
Drop the existing index using below query and run the stats select queries.
DROP INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data TRUNCATE TABLE log_simulation_job_execution
Create the below indexes, enable all the jobs and disable it after 2 minutes. Once all the jobs are disabled run the stats select queries.
CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data (ID) CREATE NONCLUSTERED INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data (MachineID, Date_Time)

Execution#3 with Surrogate Clustered Key (with nonclustered covering index)
Drop the existing indexes using below query and run the stats select queries.
DROP INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data DROP INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data TRUNCATE TABLE log_simulation_job_execution

Create the below indexes, enable all the jobs and disable it after 2 minutes. Once all the jobs are disabled run the stats select queries.
CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data (ID) CREATE NONCLUSTERED INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data (MachineID, Date_Time) INCLUDE (Sensor1_Value, Sensor2_Value, Sensor3_Value, Sensor4_Value)

Execution#4 with Natural Clustered Key
Drop the existing indexes using below query and run the stats select queries.
DROP INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data DROP INDEX IX_Coffee_Vending_Machine_Data_ID ON Coffee_Vending_Machine_Data TRUNCATE TABLE log_simulation_job_execution

Create the below indexes, enable all the jobs and disable it after 2 minutes. Once all the jobs are disabled run the stats select queries.
CREATE CLUSTERED INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data (MachineID, Date_Time)

Execution#5 without any Index
Drop the existing index using below query and run the stats select queries.
DROP INDEX IX_Coffee_Vending_Machine_Data_MachineID_Date_Time ON Coffee_Vending_Machine_Data TRUNCATE TABLE log_simulation_job_execution

Enable all the jobs and disable it after 2 minutes. Once all the jobs are disabled run the stats select queries.

Findings

- Execution#4 with Natural Clustered Key won with GOLD. It stood 1st in the Ranking in our experiment.
- Execution#3 with Surrogate Clustered Key (with nonclustered covering index) was runner up with SILVER. It stood 2nd in the Ranking in our experiment. It took the additional storage space which in-turn is an overhead to Disk IO.
- Execution#5 without any Index stood BRONZE. It stood 3rd in the Ranking in our experiment.
- Execution#1 and Execution#2 both lost the game in our experiment. Both of them stood 4th in the Ranking in our experiment.
Conclusion
There is no panacea solution. It’s always advisable to evaluate every recommendation / best practice and its trade-offs holistically, before actually applying it.
Sometimes it’s wise decision not to have any index (including clustered index), than having additional overhead of unused / poorly performing index.