|
| http://bit.ly/16UyEPH |
Hello Dear Reader. Almost two weeks ago I delivered a presentation for the 24 Hours of PASS on SQL Server Data Internals. I received some really great questions that have pushed me to dive deeper in my understanding of SQL and computers in general. One of the questions was as follows:
Why are Bytes sometimes swapped and why do you have to flip bits in order to decode a bitmap? At the time I took a WAG at the question, Wild @$$ Guess. I said that they were flipped because of a need to protect proprietary data. I couldn’t have been more wrong. Fortunately for me my friend and co-worker Roger Wolter (
@RWolter50 |
Blog) was watching and was quick to let me know that the source of the byte swapping was not proprietary. It was because of Endians.
“So Balls,” you say, “It was because of Endi-a-Whats?”
Don’t worry Dear Reader, I was right there with you. This was a new term to me, some of you clever former Computer Science majors are already seeing a light bulb form. For my sake humor me and pretend you haven’t already figured this out. Some of you former Literature Majors, or general readers of classic tales, are wondering what Gulliver Travels has to do with SQL Internals.
|
| Jack Black, Comedian, Singer, Dancer, ...Computer Scientist |
In Jonathan Swift’s satirical novel Gulliver’s Travels, Gulliver ends up in a land called Lilliput. Lilliput has hostilities with their neighbor Blefuscu. You see Lilliput likes to eat their hard boiled eggs by cracking the little end. Whereas Blefuscu likes to eat their eggs by cracking the big end. There for the Lilliput’s are known as Little End-ians and the Blefuscu are Big End-ians. Side stepping Swift’s satirical play on societal issues the term was later utilized in Computer Science over 200 years later.
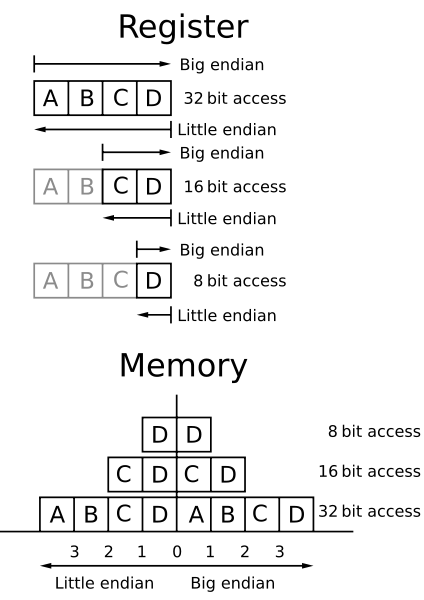
So what does this mean for Computers? It is how we read data out of memory.
We will be covering memory at a very high level, even though we are pretty deep. Memory is one big array waiting to hold our data.
What does that array hold? Bytes. How do we find where we are storing the bytes in our array? We give it an address and we look up that memory address.
An address is not an Index, but for the correlation of how to look up memory data it is comparable to the way we store data on a Clustered Index page and then look that data up by its unique key. So to make this an easy comparison for my SQL Family, let’s just say that an Address is our Index and how we will look up data in our array/table.
When we read data into memory there is a memory address assigned to the byte or bytes depending on the chipset of the machine. Big Endian Processors read the data from Left to right, also known as most significant byte to smallest address. Motorola and quite a few others use Big Endian. x86 and x64 processors use Little Endian. Since SQL Server run’s on x86 and x64 hardware we will focus mainly on that.
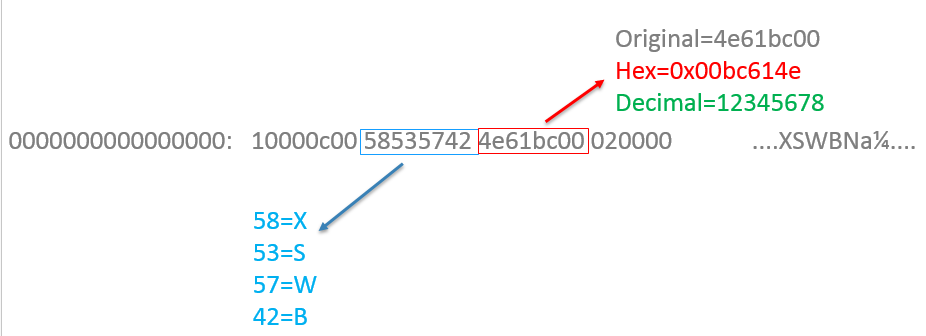
For example take value XSWB. If we translate each letter to two byte hex pairs that we would place into memory we would get X=58, S=53, W=57, B=42, or 58535742. Each hex pair would be translated to binary which would then translate to ASCI characters which would become the regular letters we see. How would we store that in memory? The ASCII example below is for 8 bit access.
*We will disprove the flipping of ASCII bit’s here in a moment using a 64 bit access. But what I want you to get from this is the concept. More in a moment. Also here’s a really nice graphic from theWikipedia Entry on Endianess, well worth the read.
BIG ENDIAN
Address | Value |
1000 | 58=X |
1001 | 53=S |
1002 | 57=W |
1003 | 42=B |
LITTLE ENDIAN
Address | Value |
1000 | 42=B |
1001 | 57=W |
1002 | 53=S |
1003 | 58=X |
This behavior is left over from when 8 bit processors had 16 bit memory registers and it was more efficient to load the lower byte first. If it was only an 8 bit operation then the top byte could be skipped. Thanks to Roger for all the technical explanations, more on that to come.
Since ASCI characters show up internally a little bit nicer than this, each letter is a two byte hex pair. No need for swapping to decode. When we get large numbers, we can really see this at work within SQL Server. For example let’s use the following statement.
if exists(select name from sys.databases where name='demoInternals') drop database demoInternals Create database demoInternals if exists(select name from sys.tables where name='brad1') create table brad1(mychar char(4) primary key clustered, myint int) insert into brad1(mychar, myint) We’ll create the value we just looked at XSWB and an integer value of 12345678. Now let’s do a DBCC IND, get our page number and look at the page dump.
dbcc ind('demointernals', 'brad1', 1) dbcc page('demointernals', 1, 278, 3) The ASCII doesn’t look byte swapped, but the integers obviously are. This lead to another question that I asked Roger. Ridiculously smart man that he is, he told me that ASCII characters do not need to load the registers in the arithmetic processors. For that reason we do not have to swap bytes.
Thanks Roger for all the great info. This was a lot of fun to learn. Thank You Dear Reader for stopping by.
Thanks,