

Did you know that Edgar F. Codd is considered the father of the relational model that is used by most database systems? He authored papers on both relational calculus and normal forms in the 1970s. It is especially important to know where the history of where today’s technology comes from. The Fabric Warehouse does support a subset of Microsoft’s Transact Structured Query Language (T-SQL). However, the Fabric storage engine (OneLake) is based upon the delta lake file format. With this knowledge, we can understand why one design pattern performs well over another one.
Business Problem
Our manager has asked us to compare how to create a date table using both an iterative approach and a set-based approach. We will start off our exploration by creating a date dimension table with SQL Server 2022. Both the code and execution timings will be recorded. Next, we will migrate these design patterns to the Fabric Warehouse. At the end of this article, you will have a good understanding of how to write performant code to dynamically generate data for tables in the future.
SQL Server 2022
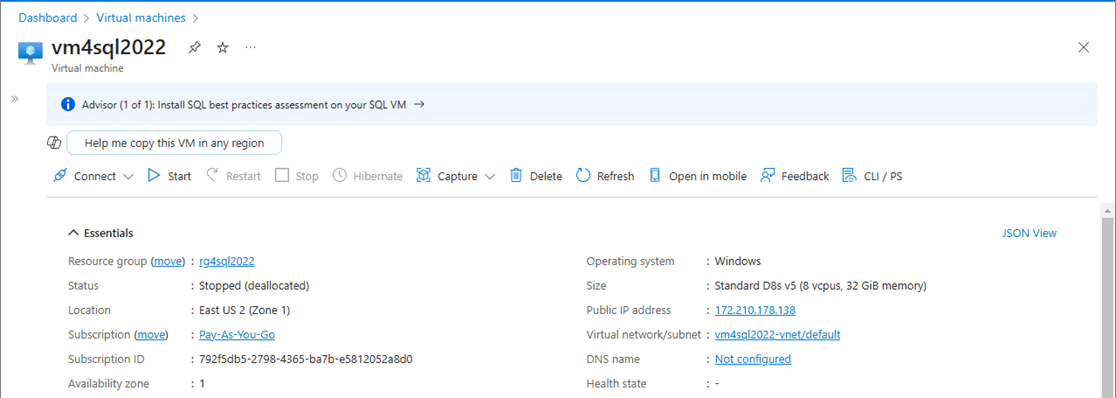
There are many companies out there that have technical debt. Since I specialize in the Data Platform area, I am always coming across client database versions that are older than my car. Please spend the time to modernize your databases to newer platforms that are supported and have many new features. In preparation for this article, I decommissioned both a SQL Server 2016 and SQL Server 2018 virtual machines in Azure. All databases were migrated to SQL Server 2022. The image below shows the new Azure virtual machine which has eight processing cores and thirty-two gigabytes of memory.
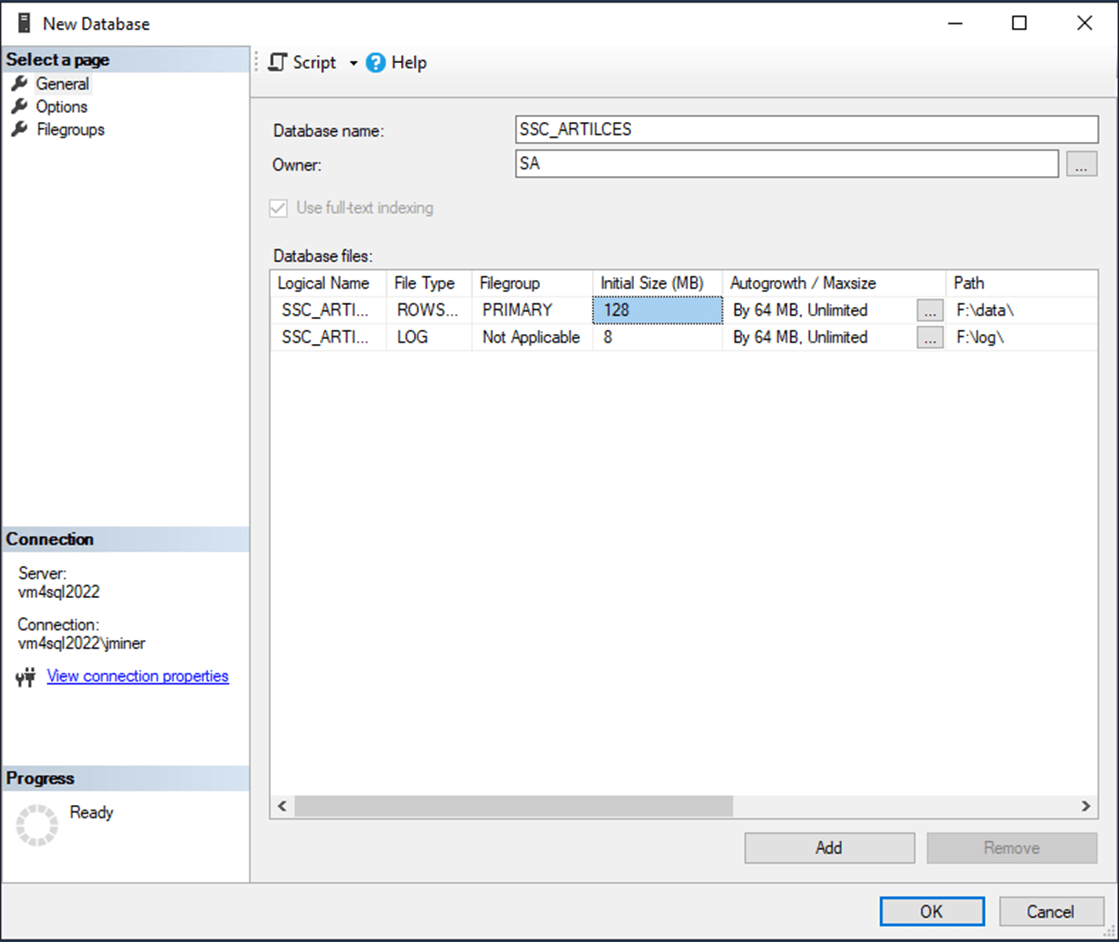
I will be using the latest version of SQL Server Management Studio to create the database schema for these tests. The image below shows both the log and data files for the database named SSC_ARTICLES being located on the F drive. The F drive is a P30 managed disk with a 5000 IOPS limit. Please check this article for details on disk performance with an Azure virtual machine.
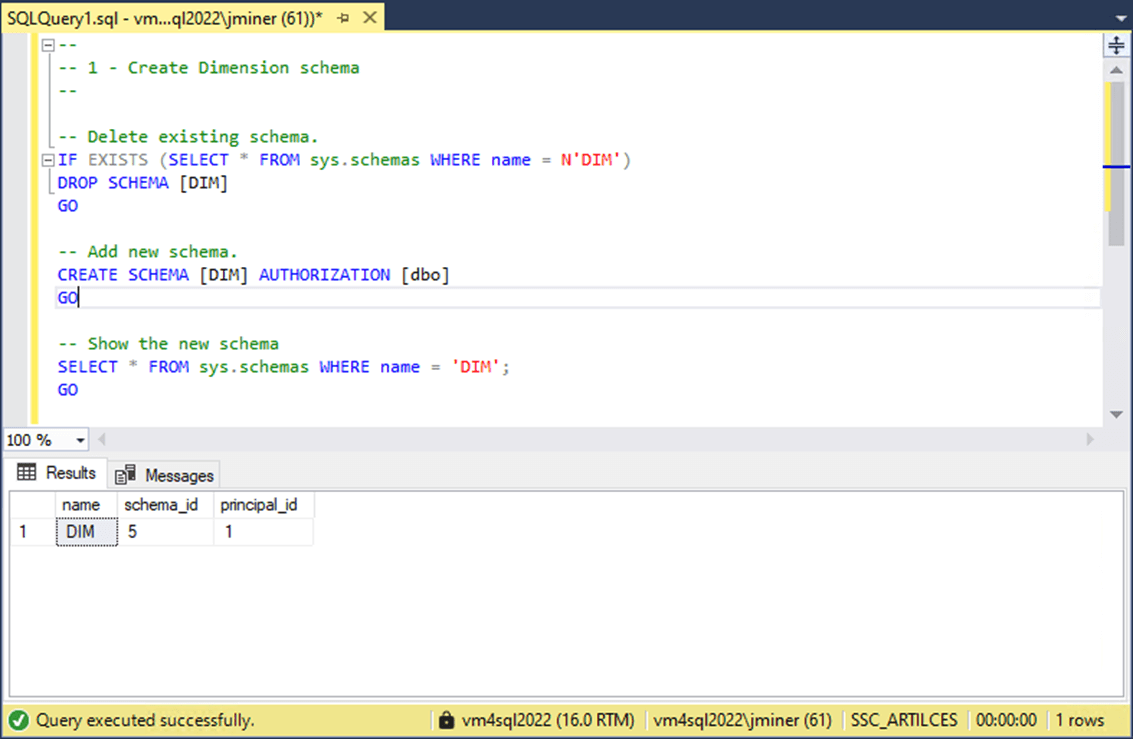
At the end of this article, I will be enclosing the T-SQL script (in a ZIP file) that is used in the section. The first step is to create a schema named DIM. Schemas are a wonderful way to bundle objects together for security purposes. Please see the image below for details.
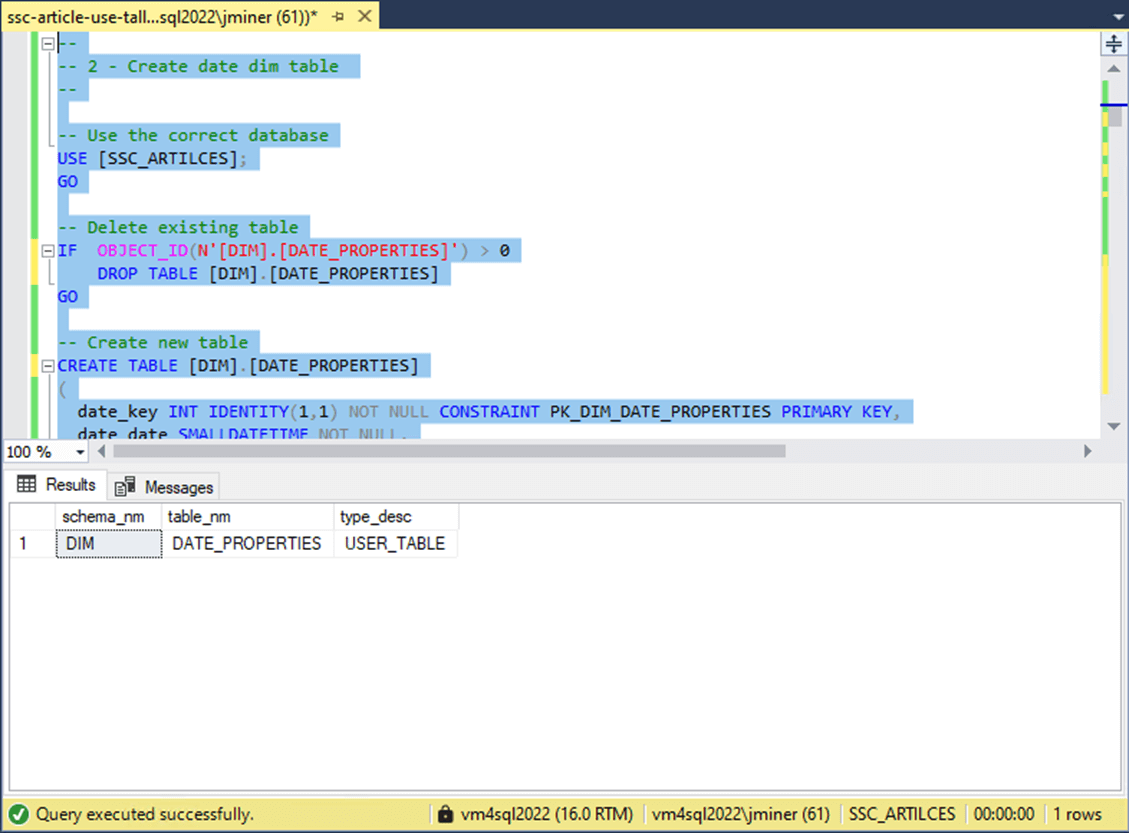
The next step is to create a table to contain properties about a given date. The image below shows a table named DATE_PROPERTIES that has been created in the DIM schema. Features such as constraints, primary keys, and default values are currently not supported in the Fabric Data Warehouse.
It is important to understand the execution time of a given algorithm. In computer science this can be mathematically calculated using Big O notation. There is a whole area of computer science dedicated to analysis of algorithms. The output below shows that the iterative approach to populating the date dimension table takes around seven seconds. This is totally acceptable for a process that only runs occasionally in an on-line analytic processing (OLAP) environment. For an on-line transaction processing (OLTP) environment that runs this code every 1 minute, devoting 11.66 percent of the processing time to this code might not be acceptable.
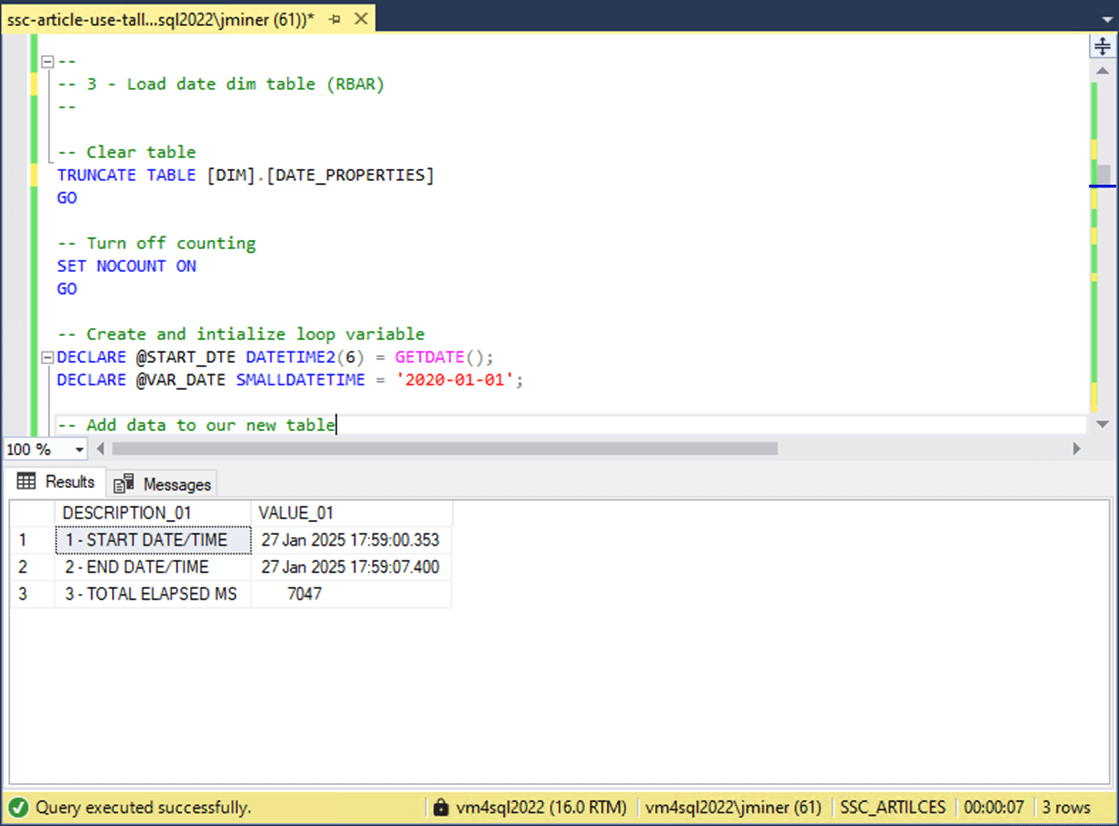
Jeff Moden, who is a fellow Microsoft MVP, coined the term RBAR that can be used to describe this code. RBAR stands for row by agonizing row. Since the database is based upon relational calculus, this non set base coding pattern does not perform well.
--
-- 1 - Load date dim table (RBAR)
--
-- Clear table
TRUNCATE TABLE [DIM].[DATE_PROPERTIES]
GO
-- Turn off counting
SET NOCOUNT ON
GO
-- Grab start date/time
DECLARE @START_DTE DATETIME2(6) = GETDATE();
-- Set loop start
DECLARE @VAR_DATE SMALLDATETIME = '2020-01-01';
-- Add data to our new table until …
WHILE (DATEDIFF(D, @VAR_DATE, '2030-01-01') <> 0)
BEGIN
-- Add row to dimension table
INSERT INTO [DIM].[DATE_PROPERTIES]
(
date_date,
date_string,
date_month,
date_day,
date_int_qtr,
date_int_doy,
date_int_yyyy,
date_int_mm,
date_int_dd
)
VALUES
(
-- As small date time
@VAR_DATE,
-- Date as string
SUBSTRING(CONVERT(CHAR(10), @VAR_DATE, 120) + REPLICATE(' ', 10), 1, 10),
-- Month as string
UPPER(SUBSTRING(CONVERT(CHAR(10), @VAR_DATE, 100) + REPLICATE(' ', 3), 1, 3)),
-- Day as string
UPPER(SUBSTRING(DATENAME(DW, @VAR_DATE), 1, 3)),
-- As quarter of year
DATEPART(QQ, @VAR_DATE),
-- As day of year
DATEPART(DY, @VAR_DATE),
-- Year as integer
YEAR(@VAR_DATE),
-- Month as integer
MONTH(@VAR_DATE),
-- Day as integer
DAY(@VAR_DATE)
);
-- Increment the counter
SELECT @VAR_DATE = DATEADD(D, 1, @VAR_DATE);
END;
-- Grab end date/time
DECLARE @END_DTE DATETIME2(6) = GETDATE();
-- Show output
SELECT '1 - START DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @START_DTE, 113) AS VALUE_01
UNION
SELECT '2 - END DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @END_DTE, 113) AS VALUE_01
UNION
SELECT '3 - TOTAL ELAPSED MS' AS DESCRIPTION_01, STR(DATEDIFF(MILLISECOND, @START_DTE, @END_DTE)) AS VALUE_01
GO
How can we make this code perform better? A tally table is just a set of numbers that is stored in a table. With the invention of common table expressions, these tables can be created in memory. There have been several algorithms proposed to create these tables over the years with their execution times. I am going to use one that fellow MVP Benjamin Nevarez designed. Please see his blog for the details.
--
-- 2 - Load date dim table (TALLY TABLE)
--
-- Clear table
TRUNCATE TABLE [DIM].[DATE_PROPERTIES]
GO
-- Turn off counting
SET NOCOUNT ON
GO
-- Grab start date/time
DECLARE @START_DTE DATETIME2(6) = GETDATE();
-- Ten years of dates
WITH CTE_TALLY_TABLE AS
(
SELECT TOP 100000
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS [N]
FROM
dbo.syscolumns tb1
CROSS JOIN
dbo.syscolumns tb2
),
CTE_TEN_YEARS AS
(
SELECT
N AS date_key,
CAST(DATEADD(D, N, '2020-01-01') AS DATETIME2(6)) AS date_date
FROM
CTE_TALLY_TABLE
WHERE
N < (365.25 * 10)
),
-- Create properties for a given date
CTE_DATE_TABLE AS
(
SELECT
-- row key
-- t.date_key,
-- date value
t.date_date,
-- Date as string
SUBSTRING(CONVERT(CHAR(10), t.date_date, 120) + CAST(REPLICATE(' ', 10) AS CHAR(10)), 1, 10) as date_string,
-- Month as string
UPPER(SUBSTRING(CONVERT(CHAR(10), t.date_date, 100) + CAST(REPLICATE(' ', 3) AS CHAR(3)), 1, 3)) as date_month,
-- Day as string
CAST(UPPER(SUBSTRING(DATENAME(DW, t.date_date), 1, 3)) AS CHAR(3)) as date_day,
-- As quarter of year
DATEPART(QQ, t.date_date) as date_int_qtr,
-- As day of year
DATEPART(DY, t.date_date) as date_int_doy,
-- Year as integer
YEAR(t.date_date) as date_int_yyyy,
-- Month as integer
MONTH(t.date_date) as date_int_mm,
-- Day as integer
DAY(t.date_date) as date_int_dd
FROM
CTE_TEN_YEARS AS t
)
-- Add to dimension table
INSERT INTO [DIM].[DATE_PROPERTIES]
SELECT * FROM CTE_DATE_TABLE;
-- Grab end date/time
DECLARE @END_DTE DATETIME2(6) = GETDATE();
-- Show output
SELECT '1 - START DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @START_DTE, 113) AS VALUE_01
UNION
SELECT '2 - END DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @END_DTE, 113) AS VALUE_01
UNION
SELECT '3 - TOTAL ELAPSED MS' AS DESCRIPTION_01, STR(DATEDIFF(MILLISECOND, @START_DTE, @END_DTE)) AS VALUE_01
GO
The cross joining of the catalog view for system columns create a noticeably big table in memory. I am grabbing the top 100 K rows into a common table expression named CTE_TALLY_TABLE. I am using this data as input to an expression called CTE_TEN_YEARS which contains dates from the start of 2020 to the end of 2030. Finally, the expression called CTE_DATE_TABLE has all the properties (columns) that I want in my final table.
The next question you might ask “Is the tally table substantially faster that the iterative approach?.”
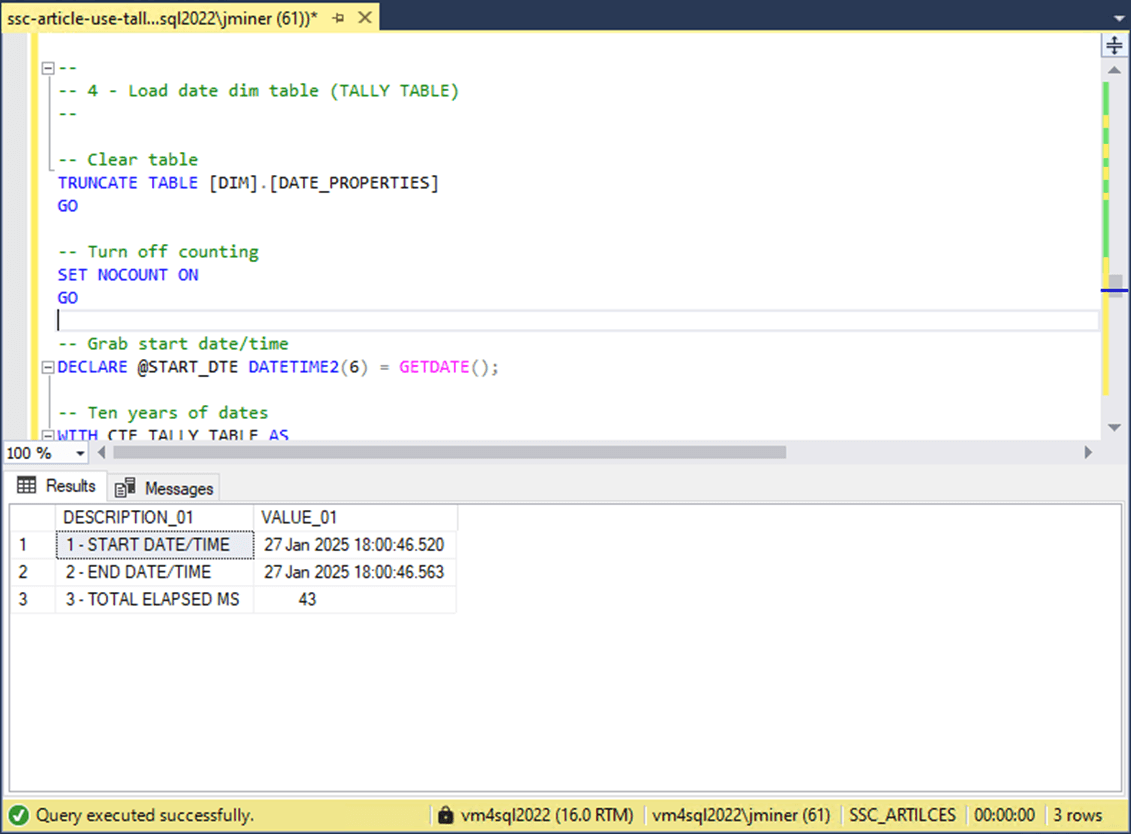
The answer is YES! This code is extremely fast since it is performed in memory before writing to disk. The execution time of the TALLY algorithm is 43 micro-seconds compared to 7047 micro-seconds required by the RBAR approach. That is a 99.39% decrease in total execution time. Next time, we will see how these algorithms transfer to the Fabric Warehouse.
Fabric Warehouse – Build Schemas
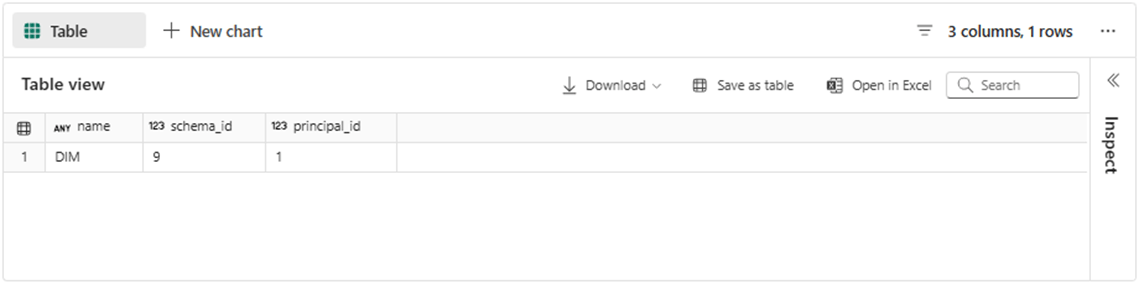
We are focused on algorithms today; However, the final goal is to dynamically populate a warehouse for Big Jons BBQ company with dummy data. There will be two schemas named DIM – contains dimensional tables and STAGE – holds raw data tables. Let us create those schemas right now. Upon execution, the T-SQL code shown below will create the first schema named DIM.
-- -- 3 - Create Dimension schema -- -- Delete existing schema. IF EXISTS (SELECT * FROM sys.schemas WHERE name = N'DIM') DROP SCHEMA [DIM] GO -- Add new schema. CREATE SCHEMA [DIM] AUTHORIZATION [dbo] GO -- Show the new schema SELECT * FROM sys.schemas WHERE name = 'DIM'; GO
The output from the T-SQL notebook in fabric is shown below.
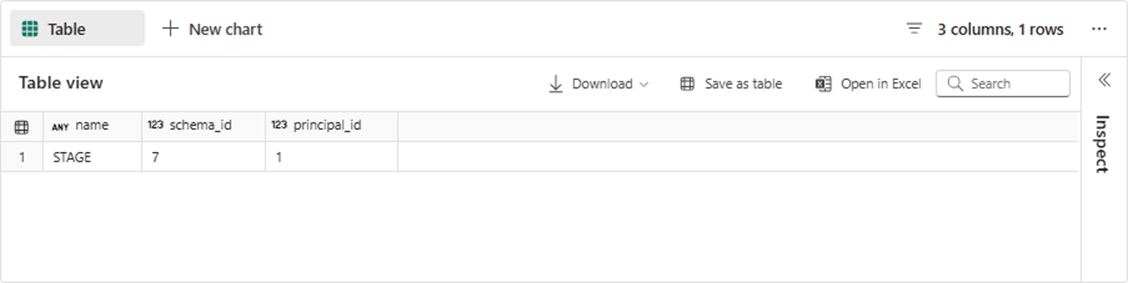
Execution of the code below will create our second schema named STAGE.
-- 4 - Create stage schema -- -- Delete existing schema. IF EXISTS (SELECT * FROM sys.schemas WHERE name = N'STAGE') DROP SCHEMA [STAGE] GO -- Add new schema. CREATE SCHEMA [STAGE] AUTHORIZATION [dbo] GO -- Show the new schema SELECT * FROM sys.schemas WHERE name = 'STAGE'; GO
The output from the T-SQL notebook in fabric is shown below.
The complete T-SQL notebook will be available at the end of the article, in the same ZIP file with the SQL script above. Therefore, we are just going to focus on tables within the schemas. The screen shot below reveals two tables in the DIM schema. The first one contains pig packages that the company will be selling, and the second one contains a date properties table.
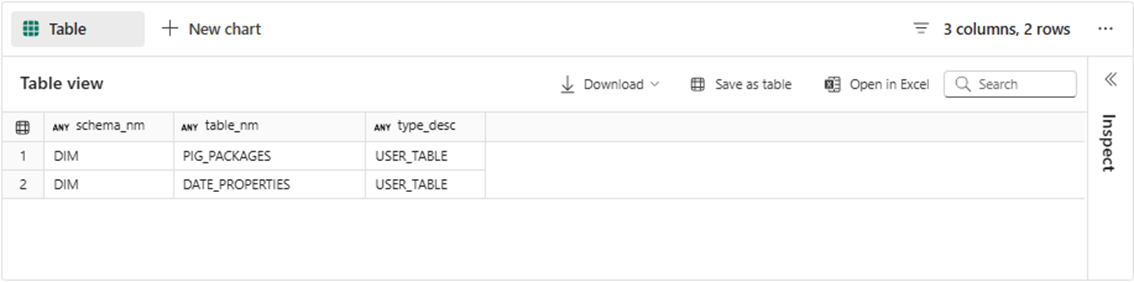
The STAGE dimension has five total tables. The following list describes each table: 1 - contains common first names, 2 - contains common last names, 3 - contains common street names, 4 – contains valid city state zip code combinations and 5 – contains a static tally table. Today, we are only focused on the date properties and tally tables. But you can guess that the staging tables will be used to dynamically create fictious clients in the demo warehouse.
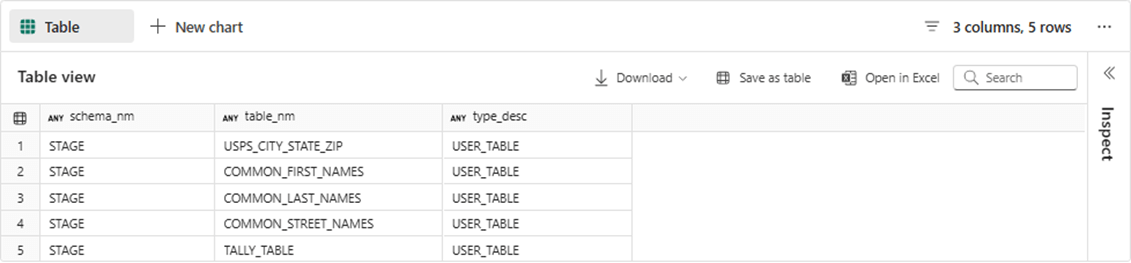
A major difference between SQL Server and Fabric Data Warehouse is the fact that names are case sensitive. This goes back to the underlying storage which is based upon delta files and the spark engine.
-- -- 5 - Show tables by schema -- SELECT s.name as schema_nm, t.name as table_nm, t.type_desc FROM sys.tables as t JOIN sys.schemas as s ON t.schema_id = s.schema_id WHERE s.name like 'STAGE%' GO
Let us populate the Tally Table using Benjamin’s algorithm.
--
-- 6 - Create tally table for looping (fails)
--
-- Delete existing table
IF EXISTS (
SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[STAGE].[TALLY_TABLE]') AND
type in (N'U'))
DROP TABLE [STAGE].[TALLY_TABLE]
GO
-- Create new table
WITH CTE_TALLY_TABLE AS
(
SELECT TOP 100000
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS [N]
FROM
dbo.syscolumns tb1
CROSS JOIN
dbo.syscolumns tb2
)
SELECT * INTO [STAGE].[TALLY_TABLE] FROM CTE_TALLY_TABLE;
GO
This code fails since querying system tables and saving the results to a table is not supported in distributed processing mode. See the documentation on limitations.
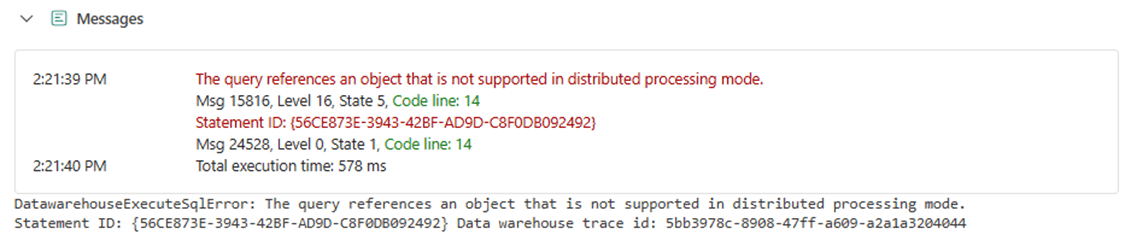
There is no restriction on creating a derived table from values. The T-SQL code below CROSS JOINS derived tables containing ten values. Thus, we are using powers of ten to generate a tally table.
--
-- 7 - Create tally table for looping
--
-- Delete existing table
IF EXISTS (
SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[STAGE].[TALLY_TABLE]') AND
type in (N'U'))
DROP TABLE [STAGE].[TALLY_TABLE]
GO
-- Create + load new table
WITH CTE_TALLY_TABLE AS
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N
FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) a(N)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) b(N)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) c(N)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) d(N)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) e(N)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) f(N)
)
SELECT N INTO [STAGE].[TALLY_TABLE] FROM CTE_TALLY_TABLE;
GO
--
SELECT COUNT(*) as TOTAL_RECS FROM [STAGE].[TALLY_TABLE];
GOThis algorithm creates a static tally table in 10 seconds. The execution time is a lot slower than SQL Server! We will get to the root cause of this issue when we explore the iterative and set based approaches to fill the date table in the next section.
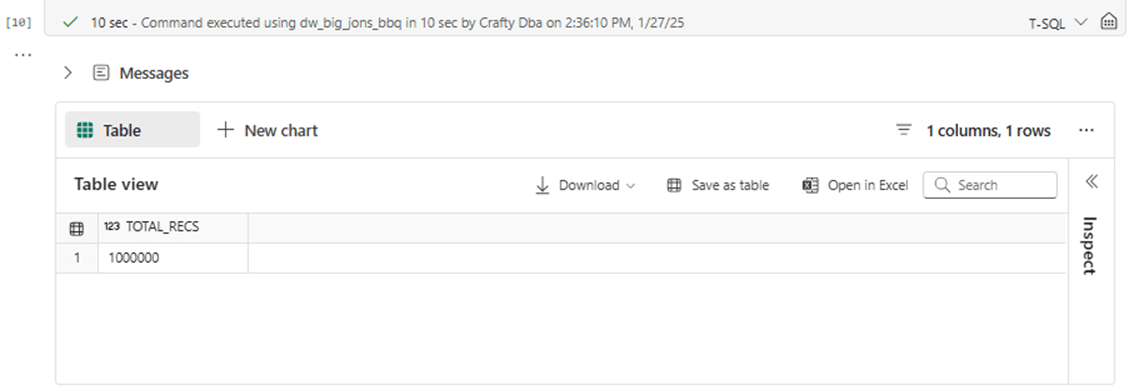
Fabric Warehouse – Analyze Algorithms
I did skip over the date properties table before. I am going to rectify that oversight now by showing the table creation code right now.
--
-- 8 - Create date dim table
--
-- Delete existing table
IF OBJECT_ID(N'[DIM].[DATE_PROPERTIES]') > 0
DROP TABLE [DIM].[DATE_PROPERTIES]
GO
-- Create new table
CREATE TABLE [DIM].[DATE_PROPERTIES]
(
date_key INT NOT NULL,
date_date DATETIME2(6) NOT NULL,
date_string VARCHAR(10) NOT NULL,
date_month VARCHAR(3) NOT NULL,
date_day VARCHAR(3) NOT NULL,
date_int_qtr INT NOT NULL,
date_int_doy INT NOT NULL,
date_int_yyyy INT NOT NULL,
date_int_mm INT NOT NULL,
date_int_dd INT NOT NULL
);
GO
There is only one change that needs to be made for the T-SQL code in section 1 to work with Fabric Data Warehouse. The identity column is not supported by the warehouse. Thus, we must define, initialize, and increment a counter for the surrogate key field called date_key.
--
-- 9 - Load date dim table (RBAR)
--
-- Clear table
TRUNCATE TABLE [DIM].[DATE_PROPERTIES]
GO
-- Turn off counting
SET NOCOUNT ON
GO
-- Grab end date/time
DECLARE @START_DTE DATETIME2(6) = GETDATE();
-- Date counter
DECLARE @VAR_DATE SMALLDATETIME = '2020-01-01';
-- Surrogate key counter
DECLARE @VAR_CNTR INT = 1;
-- Add data to our new table
WHILE (DATEDIFF(D, @VAR_DATE, '2030-01-01') <> 0)
BEGIN
-- Add row to dimension table
INSERT INTO [DIM].[DATE_PROPERTIES]
(
date_key,
date_date,
date_string,
date_month,
date_day,
date_int_qtr,
date_int_doy,
date_int_yyyy,
date_int_mm,
date_int_dd
)
VALUES
(
-- Surrogate key for record
@VAR_CNTR,
-- A date time value
@VAR_DATE,
-- Date as string
SUBSTRING(CONVERT(CHAR(10), @VAR_DATE, 120) + REPLICATE(' ', 10), 1, 10),
-- Month as string
UPPER(SUBSTRING(CONVERT(CHAR(10), @VAR_DATE, 100) + REPLICATE(' ', 3), 1, 3)),
-- Day as string
UPPER(SUBSTRING(DATENAME(DW, @VAR_DATE), 1, 3)),
-- As quarter of year
DATEPART(QQ, @VAR_DATE),
-- As day of year
DATEPART(DY, @VAR_DATE),
-- Year as integer
YEAR(@VAR_DATE),
-- Month as integer
MONTH(@VAR_DATE),
-- Day as integer
DAY(@VAR_DATE)
);
-- Increment the counter
SELECT @VAR_DATE = DATEADD(D, 1, @VAR_DATE), @VAR_CNTR = @VAR_CNTR + 1;
END;
-- Grab end date/time
DECLARE @END_DTE DATETIME2(6) = GETDATE();
-- Show output
SELECT '1 - START DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @START_DTE, 113) AS VALUE_01
UNION
SELECT '2 - END DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @END_DTE, 113) AS VALUE_01
UNION
SELECT '3 - TOTAL ELAPSED MS' AS DESCRIPTION_01, STR(DATEDIFF(MILLISECOND, @START_DTE, @END_DTE)) AS VALUE_01
GO
I knew this algorithm would perform badly. But I was astonished that it took almost 22 minutes to load the table with 3652 records.
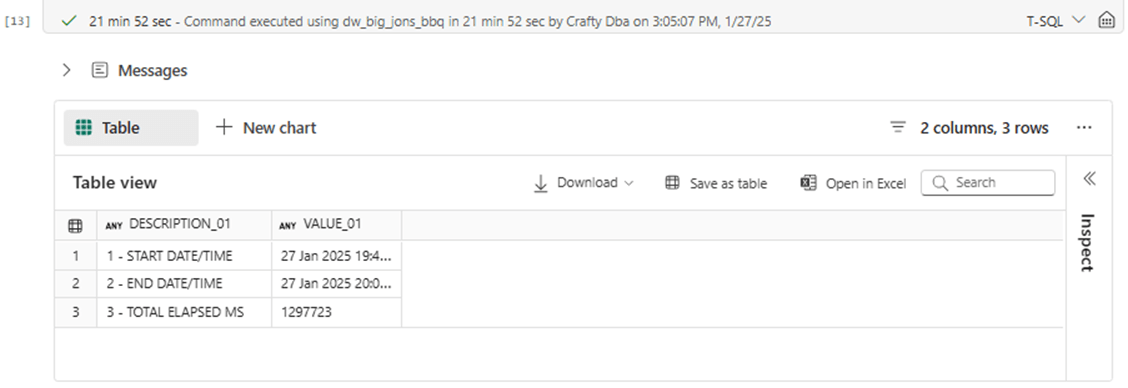
The image below shows how the delta file format works. For a newly inserted record, both a new Parquet and a new JSON file must be created. Thus, we are creating 7305 files on storage that is virtualized in Microsoft Fabric.
Let us re-write the code to use the static tally table and common table expressions.
--
-- 10 - Load date dimension table (Tally Table)
--
-- Use cte to insert data into table
-- Clear the table
DELETE FROM [DIM].[DATE_PROPERTIES];
GO
-- Turn off counting
SET NOCOUNT ON
GO
-- Start date / time
DECLARE @START_DTE DATETIME2(6) = GETDATE();
-- Ten years of dates
;
WITH CTE_TEN_YEARS AS
(
SELECT
N AS date_key,
CAST(DATEADD(D, N, '2020-01-01') AS DATETIME2(6)) AS date_date
FROM
[STAGE].[TALLY_TABLE]
WHERE
N < (365.25 * 10)
),
-- Create properties for a given date
CTE_DATE_TABLE AS
(
SELECT
-- row key
t.date_key,
-- date value
t.date_date,
-- Date as string
SUBSTRING(CONVERT(CHAR(10), t.date_date, 120) + CAST(REPLICATE(' ', 10) AS CHAR(10)), 1, 10) as date_string,
-- Month as string
UPPER(SUBSTRING(CONVERT(CHAR(10), t.date_date, 100) + CAST(REPLICATE(' ', 3) AS CHAR(3)), 1, 3)) as date_month,
-- Day as string
CAST(UPPER(SUBSTRING(DATENAME(DW, t.date_date), 1, 3)) AS CHAR(3)) as date_day,
-- As quarter of year
DATEPART(QQ, t.date_date) as date_int_qtr,
-- As day of year
DATEPART(DY, t.date_date) as date_int_doy,
-- Year as integer
YEAR(t.date_date) as date_int_yyyy,
-- Month as integer
MONTH(t.date_date) as date_int_mm,
-- Day as integer
DAY(t.date_date) as date_int_dd
FROM
CTE_TEN_YEARS AS t
)
-- Add to dimension table
INSERT INTO [DIM].[DATE_PROPERTIES]
SELECT * FROM CTE_DATE_TABLE;
-- Grab end date/time
DECLARE @END_DTE DATETIME2(6) = GETDATE();
-- Show output
SELECT '1 - START DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @START_DTE, 113) AS VALUE_01
UNION
SELECT '2 - END DATE/TIME' AS DESCRIPTION_01, CONVERT(CHAR(24), @END_DTE, 113) AS VALUE_01
UNION
SELECT '3 - TOTAL ELAPSED MS' AS DESCRIPTION_01, STR(DATEDIFF(MILLISECOND, @START_DTE, @END_DTE)) AS VALUE_01
GO
In general, set-based algorithms perform better than the iterative based ones. The total execution time of 1,297,723 milliseconds for the first algorithm versus 710 milliseconds for the second algorithm. This equates to a decrease in execution time of 99.94 percent.
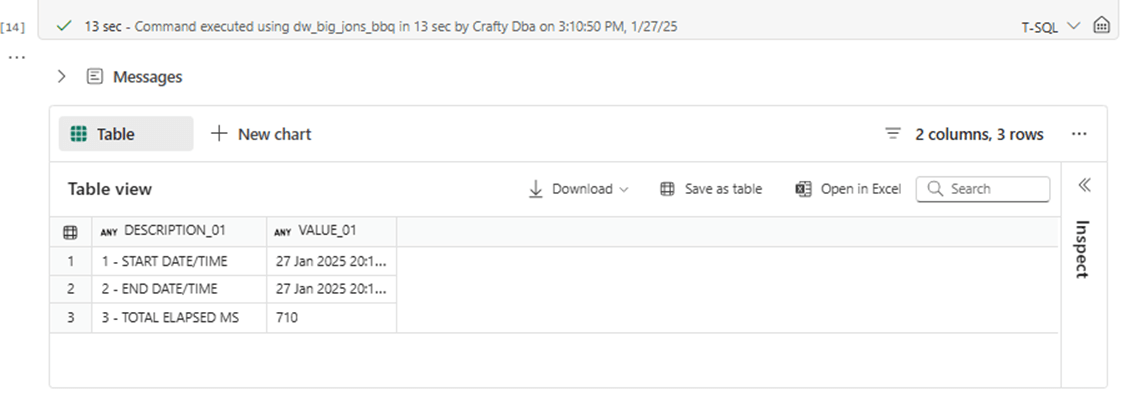
Many times, I see companies with performance problems assume that adding more hardware will fix the issue. Do you think scaling up the Fabric Capacity will decrease the execution time for both algorithms?
Fabric Capacity – Scaling Compute
The Fabric Capacity is defined in your Azure Subscription. Please see documentation for more details. We can see that we have an F16 computing tier as the current setting.
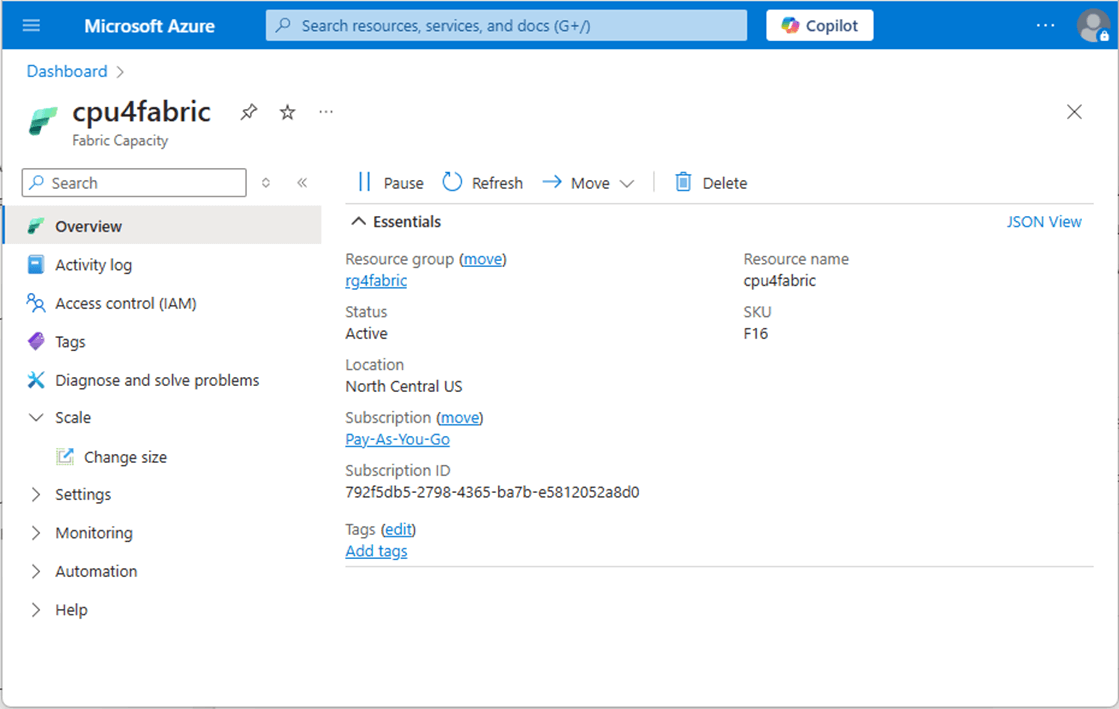
If there was a linear relationship between execution time and computing capacity, increasing the size by four times should reduce the execution time by a factor of four.
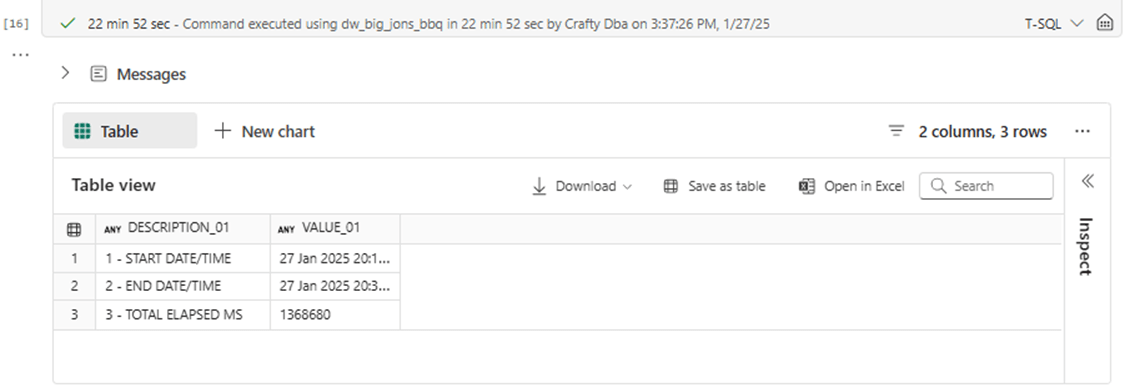
Please re-run the iterative algorithm using the new capacity level if you are following along with the examples. An unexpected result has just occurred. The execution time has increased by 60 seconds. I was expecting the same run time since the real bottle neck of the code is the creation of 3652 files on remote disk. The addition of more CPU and MEMORY should not fix this bottleneck.
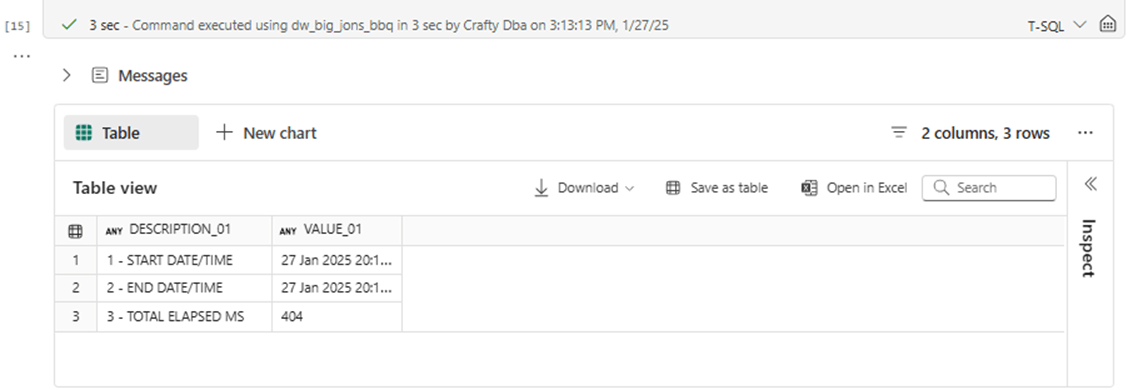
Please re-run the set-based algorithm using the new capacity tier. The outcomes of this test were expected. Since the common table expression is done in memory before writing one Parquet and one JSON file to disk, the addition of more computing will decrease the execution time. The execution time was reduced from 710 milliseconds to 404 milliseconds. That is a 43.09 percent decrease in execution time. I was hoping for 178 milliseconds if there was a linear relationship.
Summary
Students are taught about loops in their first computer programming class. Thus, using iterative based programming algorithms seem natural. However, relational based database systems and data warehouses are based on set logic. Set logic always performs better than iterative based algorithms.
Today, we explored how a tally table can reduce the execution time of code that is used to create data for a given table. The date properties table is just one-use case of such logic. For example, the banking industry uses loan amortization tables to determine how much of a payment goes towards the principle versus paying off interest. A company might want to generate and store this table for each new client. A thirty-year mortgage that is paid bi-monthly has 720 rows of data. The iterative algorithm would take mere seconds executing within SQL Server but would take minutes completing with Fabric warehouse. If we had to execute this process a couple hundred times each day for new loans, the Fabric execution time might stretch in hours. The set-based algorithm using a tally table will take a fraction of the total execution time.
Does adding more Fabric Capacity reduce the total execution time? I was surprised that it increased the execution time for iterative algorithms. More analysis is required to find the root cause of the change. However, I think the TRUNCATE TABLE statement must clean up the meta data and/or files which might account for the additional execution time. A better test would be to re-test with an empty table.
Finally, I want to point out the fact that this is a data warehouse. Again, single data manipulation language (DML) statements such as inserts, updates, and deletes do not scale well. Set oriented changes of substantial amounts of data will work fine. In closing, here is the code I used in this article bundled up into a zip file.
PS: Things are constantly changing in Technology. Microsoft introduced the GENERATE_SERIES function in SQL Server 2022 which is supported by the Fabric Warehouse. I leave it up to see if this function performs better than a Tally Table.