

Introduction
In this article, I’ll attempt to “convince” you that every SQL Server you put into production should be a SQL Server Failover Cluster Instance (FCI).
A Quick Introduction to Clustering
Clustering has been available in Windows NT4 and SQL Server since 6.5, although no one I know was brave enough to use SQL 6.5 with a Windows NT 4 cluster. Clustering in NT4 was just simply not usable. Clustering didn’t really become usable until Microsoft’s next cluster release with Windows 2000 and SQL Server 7.0.
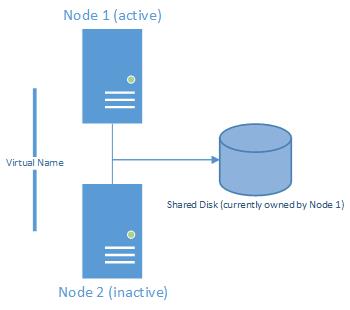
Clustering in SQL Server uses a shared-disk scenario along with (typically) multiple nodes. Although you can have a cluster of one, and most of what I present here applies to clusters of one, we’ll assume for this article that you have at two nodes in your cluster, which is by far the most common scenario. The SQL Server cluster is accessed using a Virtual Name, so that to an application, the cluster looks exactly like a stand-alone SQL Server. No additional configuration is required on the client (application) side to access a cluster.
So, what exactly is a node? From Books Online, a node is, “Microsoft Windows Server system that is an active or inactive member of a server cluster”. A SQL Server instance can only run on a single node at a time. An Active node is the one where SQL Server is currently running. The inactive node is then the one where SQL Server is not currently running. The node is essentially the “head” of the cluster. If one of the heads fails, another takes over. That in a nutshell is the beauty of a cluster.
The flowing picture illustrates a simple cluster of two:
From the Obvious to the Not-So-Obvious
Anyone thinking of clustering SQL Server is typically looking at clustering as a high availability solution, and that’s all good and fine, but I offer that there are several other reasons to consider clustering. The reasons I list will go from the obvious, especially if you’re already familiar with clusters, to the not-so-obvious. Hopefully, even if you’ve been doing clustering since SQL 7.0, you’ll pick up a few new ideas at the end of this section that maybe you hadn’t thought about.
Reason to cluster number 1: Hardware Failure
Probably the biggest reason someone would choose to cluster their SQL Server systems is to support high availability. The avoidance (or at least lessoning) of an outage when the hardware goes bad. Funny thing is, although this may not have been true several years ago, with the quality of today’s hardware I rarely see hardware as the main issue in server downtime.
Reason 2: SQL Server Upgrades
This is probably my favorite reason to consider clustering. As a sole DBA at the place I work, I support over 50 SQL servers (and yes, almost all of them are clustered – even the sandbox, development and QA servers). Upgrading SQL Server is “quick and easy” when you have a cluster, and I can do it on my schedule. Why? Because the only downtime is a failover and the time it takes SQL to update the scripts. This usually happens in a handful of minutes. There is no downtime associated with updating an inactive node, so I can upgrade the inactive node anytime I want. Then I can schedule a failover when it is convenient for the business. After the failover, I upgrade the second node (which is now inactive) when I have time again.
Compare this to doing a stand-alone upgrade, where SQL Server is down the entire time of the upgrade. Not to mention crossing your fingers that everything goes swimmingly with the upgrade. And if it doesn’t, your downtime just turned in to hours, or possibly days. Yikes! Worst case with a cluster, is I have to rebuild the node and re-add it to the cluster, all while SQL keeps running. I have had upgrades fail and had to tweak some things to get it to work, but again, all while SQL keeps running.
Reason 3: Windows Upgrades
I work in a company that has a networking group. That group is responsible for all of the OS level patches. What happens is they patch the inactive node (again on their time schedule) and fail over to that node when the business is ready. We’ll then wait for one week, if all looks good we’ll then patch the inactive node. There have been many times when an OS patch directly affected either SQL Server, or one of our SQL Server processes (SSIS, CLR, etc). When that happens, we simply fail back to the unpatched node, check to make sure that it was indeed the patch (by checking that everything is working as before the patch). We then remove the offending patches. Downtime is about a minute. On a stand-along install, you could be looking at multiple reboots and testing as you pull off each patch, all while SQL is probably down.
Reason 4: Offsite Node
Starting with SQL Server 2008. Geo-clustering (clustering servers not in the same subnet) became possible and in SQL 2012 it was greatly enhanced and actually became usable.
Reason 5: Move to better hardware
Another of my favorite reasons to cluster. We purchase hardware that comes with a 3 year warranty. Once the warranty runs out, we replace the server. In our situation, it simply is cheaper. We could debate why replacing your server every 3 years is actually cheaper than holding on to it for longer, but that would be another article. So, once our hardware comes up for replacement, we are tasked with moving off the old hardware and onto the new. In a clustered environment, it is extremely easy to simply add an additional node into the cluster (using the new hardware). Then fail over to that node. Once we are sure the new hardware is stable, we add the second new node, then decommission the old two nodes. Easy.
Again, downtime is about 1 minute. On a stand-alone server, best case, you would need to bring down SQL while you reattach the storage to the new server, or if that’s not possible, restore the databases to the new server. That is probably hours of down time and another session of crossing your fingers and hoping everything works out.
Reason 6: Add a VM to see if virtual will work
We’ve been moving to VMs for all of our SQL servers. There are huge benefits; licensing, lower power costs, isolating applications, lower hardware costs, taking advantage of VM high availability and the list goes on. Moving from physical to virtual is the right thing for us. When we’re moving our physical servers to virtual servers, we do our homework, do our sizing and performance testing, but in the end how will we know definitively if the virtual server environment will work for our specific SQL Server instance? What happens if you move to a VM environment, only to find out that it simply won’t work for your workload? This is where clustering can pay off again. In a cluster environment, you can simply spin up a SQL Server VM node and add it to the cluster, fail over to that node, test, benchmark, etc. If things look good, add another VM node and you’re on your way. If you missed the boat on estimating, simply fail back to the physical node and the only down time is about a minute (and your hurt pride).
Reason 7: Move to a physical when you’ve grown outside a VM
On the flip side, what happens when your VM outgrows the VM environment? Maybe you’ll upgrade your VM hosts to accommodate the growth, but maybe that isn’t feasible. With a cluster you would have the option to move to a physical machine to increase the horsepower for that particular SQL Server by simply adding a physical node to the existing SQL Server VM cluster. Again, downtime would be a minute or so.
Conclusion
In this article, we took a look at a brief look at what clustering is and what the potential benefits can be. I hope along the way, I’ve made at least a good run at getting you to consider clustering for most, if not all of your SQL Server installs.
In my next article, I'll look at the “perfect” couple: FCI & AG together.
Additional References
Books Online - Windows Server Failover Clustering (WSFC): http://msdn.microsoft.com/en-us/library/hh270278.aspx
Always On Failover Cluster Instances (SQL Server): http://technet.microsoft.com/en-us/library/ms189134.aspx
