

Introduction
In this article I'll be demonstrating three methods that can be used to eliminate the SORT operator, in this case, when performing a SELECT statement with an ORDER BY clause. These tips can be especially useful when the SORT operation is the main performance culprit of a SELECT query.
For some people, these methods are pretty obvious after thinking about them, and most probably some of us will never have even thought specifically about them but have been using them throughout their development.
There is no magic answer in that one method will work better than the other or even that any one of these methods would work satisfactorily for your scenario, the issue being that each method has got both pros and cons as further highlighted at the end of this article.
Test Scenario
For these tests, I'll be using the Adventure Works database. The table which I'll be using is the Production.Product table which has a Clustered Primary Key defined on the ProductID and three other indexes. I'll be disabling the AK_Product_ProductNumber index not to interfere with the results.
I'll be running four tests which are:
Test 1) Sorting the data on retrieval.
Basically, in this test, an ORDER BY is specified in the SELECT statement and the data is sorted on executing the SQL Statement. This is the 'benchmark' test against which I'll compare the other three tests.
Test 2) Using an INDEXED VIEW created on the source table.
In this test, I've created a view on the source table and created a clustered index (on the ProductNumber) on the view. Then I've run my select statement against the Indexed view. Basically, an indexed view will physically save the data in a permanent state in the database and is updated automatically on updating its source tables.
Test 3) Using a CLUSTERED INDEX on the source table.
In this test, the CLUSTERED INDEX definition is removed from the Primary Key and specified on other columns, in this case, the column that we'll want to sort by.
Note: I've created a replica of the source Product table for this test, not to modify the original table, which can later be dropped after the tests
Test 4) Using a NON-CLUSTERED Index.
In this test a NON-CLUSTERED index is created on the source table, having the sort columns as the Index columns while the remainder of the columns defined as 'Included columns'.
Comparing Results
A few notes on the results.
- The results may not be identical to the ones which I got due to different hardware or different version of the AdventureWorks DB, but will still give a good indication of whether the query performed better or worse.
- I've used both the execution plan output and the STATISTICS IO and STATISTICS TIME output to compare performance since the execution plan costs are based on estimates which may not be 100% accurate!
- Since the number of records in the Production table is comparable small (~500 records), I could not get repeatable accurate TIME statistics (CPU time)! However, I've tested all three methods on a 200,000 record table and I did notice a reproducible tenfold CPU time performance improvement.
- DBCC DROPCLEANBUFFERS was used before every test to clear the data from the buffer pool.
- DBCC FREEPROCCACHE was used to clear the plan cache.
Test Results
I've started by disabling the existing non-clustered Index 'AK_Product_ProductNumber' not to interfere with the tests.
ALTER INDEX AK_Product_ProductNumber ON Production.Product Disable;
Test 1
Below is the SQL Statement used to retrieve all products sorted by the ProductNumber.
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE Set statistics IO,TIME ON SELECT *
FROM [AdventureWorks].[Production].[Product]
ORDER BY [ProductNumber] Set statistics IO,TIME OFF
And here is the actual execution plan. As expected, the optimizer selected a Clustered Index Scan on the PK_Product_Product_ID Index. Note the SORT operator which was utilized to order the data set. In my case, the SORT operator cost is 59% of the total query cost. Note that if the data set is large, the SORT operator will carry a larger portion of the total query cost.
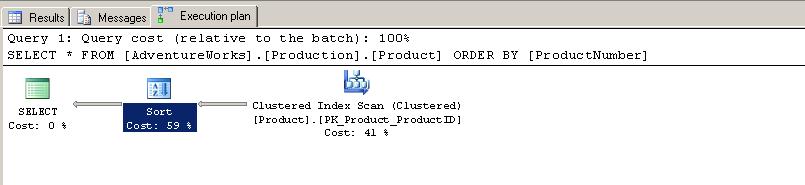
Below is the properties page for the SORT operator. The estimated cost for this operator is 0.018.

And below is the total estimated cost for the query; 0.03

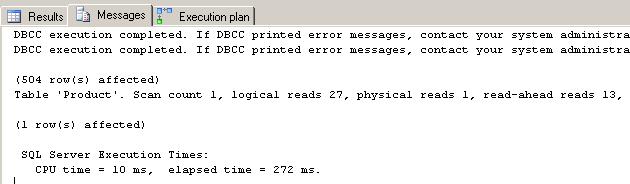
Results from the IO and TIME STATISTICS. 27 logical reads were needed to retrieve, sort and output the data set.
Test 2
First I'll create the view with all the source table columns. Notice also the WITH SCHEMABINDING option which is needed to create an Indexed view. After that, a clustered index was created on ProductNumber column of the view.
-- Create the View CREATE VIEW v_Products
WITH SCHEMABINDING
AS
SELECT [Production].[Product].[ProductID]
,[Production].[Product].[Name]
,[Production].[Product].[ProductNumber]
,[Production].[Product].[MakeFlag]
,[Production].[Product].[FinishedGoodsFlag]
,[Production].[Product].[Color]
,[Production].[Product].[SafetyStockLevel]
,[Production].[Product].[ReorderPoint]
,[Production].[Product].[StandardCost]
,[Production].[Product].[ListPrice]
,[Production].[Product].[Size]
,[Production].[Product].[SizeUnitMeasureCode]
,[Production].[Product].[WeightUnitMeasureCode]
,[Production].[Product].[Weight]
,[Production].[Product].[DaysToManufacture]
,[Production].[Product].[ProductLine]
,[Production].[Product].[Class]
,[Production].[Product].[Style]
,[Production].[Product].[ProductSubcategoryID]
,[Production].[Product].[ProductModelID]
,[Production].[Product].[SellStartDate]
,[Production].[Product].[SellEndDate]
,[Production].[Product].[DiscontinuedDate]
,[Production].[Product].[rowguid]
,[Production].[Product].[ModifiedDate]
FROM[Production].[Product] GO -- Create a clustered index on the view CREATE UNIQUE CLUSTERED INDEX TMP_INDX ON v_Products(ProductNumber)
And below is the SQL used to retrieve all products but this time from the Indexed view. I've specified the NOEXPAND table hint to make sure that the optimzer selects the data directly from the Indexed view as opposed to the base table.
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE Set statistics IO,TIME ON SELECT *
FROM [AdventureWorks].[dbo].[v_Products] WITH (NOEXPAND)
ORDER BY [ProductNumber] Set statistics IO,TIME OFF
Below is the actual execution plan generated. Notice that this time we don't have a SORT operator since the data was already sorted in the view and therefore all the cost is towards the Clustered Index scan from the view.
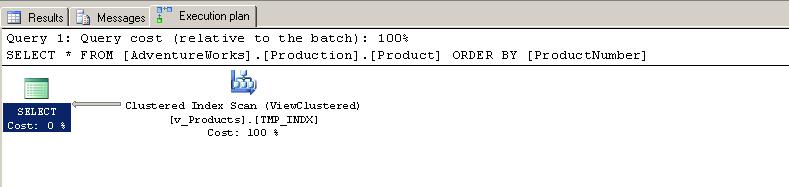
Below is the total estimated cost for the query: 0.012 which is faster than the first test!
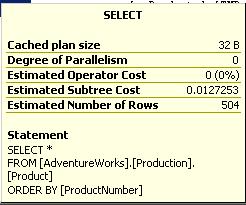
and the results from the STATISTICS displayed below. Notice that the logical reads went down from 27 to 15 pages.
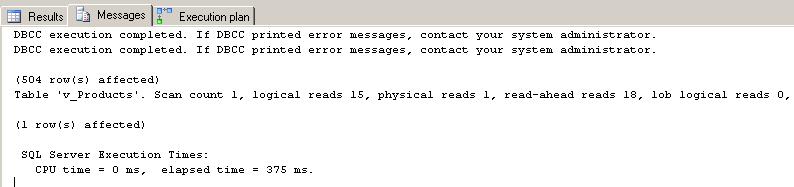
Test 3
Create a replica of the Product Table calling it New_Product and specify a NON CLUSTERED Primary key on the ProductID while define a CLUSTERED Index on the ProductNumber.
-- Create a new table SELECT *
INTO [Production].[New_Product]
FROM Production.Product -- Create a CLUSTERED INDEX on the ProductNumber Column. CREATE UNIQUE CLUSTERED INDEX TMP_INDXX ON [Production].[New_Product](ProductNumber) -- Create the Primary Key on the ProductID. ALTER TABLE [Production].New_Product
ADD CONSTRAINT pk_products_ppn PRIMARY KEY(ProductID)
Once the table has been successfully created, run the below SELECT statement
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE Set statistics IO,TIME ON SELECT *
FROM [Production].New_Product
ORDER BY ProductNumber Set statistics IO,TIME OFF
Same as test 2, no SORT operator was introduced by the optimizer since the source table is already sorted by the ProductNumber thanks to the CLUSTERED Index.
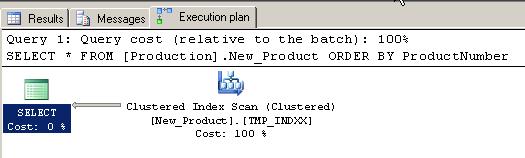
Below is the query estimated cost for this test; 0.012 which is also faster than the first test!

The results as outputted from the STATISTICS command also reveal that the logical reads went down to 15 from 27 pages.
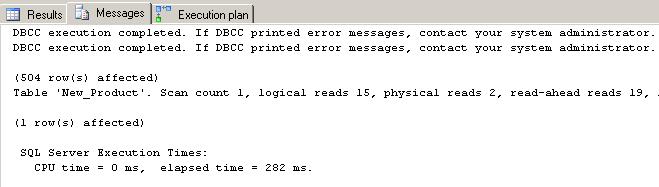
Test 4
I've created a non-clustered index on the ProductNumber column with all columns defined as 'Included'.
Note: In this test, I've included all the table columns to be part of the Index. In real world scenarios, only the required columns which will be selected need to be 'Included' in the index.
CREATE INDEX TMP_INDX_NONCLUSTERED ON
[AdventureWorks].[Production].[Product] (ProductNumber)
INCLUDE ( [Name]
,[MakeFlag]
,[FinishedGoodsFlag]
,[Color]
,[SafetyStockLevel]
,[ReorderPoint]
,[StandardCost]
,[ListPrice]
,[Size]
,[SizeUnitMeasureCode]
,[WeightUnitMeasureCode]
,[Weight]
,[DaysToManufacture]
,[ProductLine]
,[Class]
,[Style]
,[ProductSubcategoryID]
,[ProductModelID]
,[SellStartDate]
,[SellEndDate]
,[DiscontinuedDate]
,[rowguid]
,[ModifiedDate])
Once the Index has been successfully created, run the below SELECT statement
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE Set statistics IO,TIME ON SELECT *
FROM [AdventureWorks].[Production].[Product]
ORDER BY [ProductNumber] Set statistics IO,TIME OFF
Same as test 2 and test 3, no SORT operator was introduced by the optimizer since all the data was read from the already sorted non-clustered Index - TMP_INDX_NONCLUSTERED.
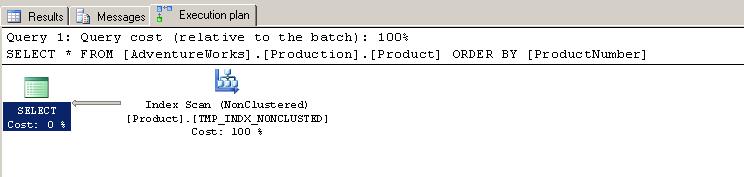
Below is the query cost for this test: 0.012.

The STATISTICS output also shows a decrease in the number of logical reads.

What about UPDATES?
Well, this article would be incomplete without a quick look at the performance penalty when applying any of the three methods on the DML statements, specifically UPDATES (since that's what I tested).
| Test Number | SELECT Query estimated Cost | UPDATE Query estimated Cost | Test type |
|---|---|---|---|
| 1 | 0.03 | 0.148 | SELECT Statement doing ORDERING |
| 2 | 0.012 | 0.327 | SELECT on an Indexed View |
| 3 | 0.012 | 0.375 | New CLUSTERED Index |
| 4 | 0.012 | 0.319 | New NON CLUSTERED Index |
| Test Number | SELECT Query IO results | UPDATE Query IO Results | Test Type |
|---|---|---|---|
| 1 | 24 | 2072 | SELECT Statement doing ORDERING |
| 2 | 15 | 6463 | SELECT on an Indexed View |
| 3 | 15 | 3222 | New CLUSTERED Index |
| 4 | 15 | 4113 | New NON CLUSTERED Index |
As shown above, using any of these methods will have a negative effect on DML statements.
Pros & Cons
As mentioned in the introduction, there is no one solution which will work better than the other in all circumstances since there are both advantages and disadvantages on applying one method over another
Test 1) Sorting the data on retrieval.
Advantages
- No changes to the DB structure
- INSERTS, UPDATES and DELETE performance is not effected.
Disadvantages
- The sorting is done on retrieval, hence the introduction of the SORT operator and the larger query cost.
Test 2) Using an INDEXED VIEW created against the source table.
Advantages
- Sorting is faster since the data is selected from an already sorted source.
- No changes to the original table design.
Disadvantages
- It's not always possible to make changes to the DB.
- DML statements will run slower since the SQL engine will have to update two places now, the source table and the Indexed view.
- More Hard Disk space is required to store the extra Indexed View.
Test 3) Using a CLUSTERED INDEX on the source table.
Advantages
- Sorting is faster since the data is selected from an already sorted source.
Disadvantages
- It's not always possible to make changes to the DB.
- If the Clustered Index column changes frequently, DML statements will be slower due to the continued updates of the CLUSTERED Index, more page splits are expected and therefore more IO. (The FILL FACTOR option might be considered in this scenario).
Test 4) Using a NON-CLUSTERED index on the source table
Advantages
- Sorting is faster since the data is selected from an already sorted source, i.e the Index.
- No changes to the original table design.
Disadvantages
- It's not always possible to make changes to the DB.
- DML statements will get slower since the SQL engine will have to update two places now, the source table and the extra Index.
- More Hard Disk space is required to store the extra Index.
Conclusion
As demonstrated above, there is no one solution which will always work better than the other. Although the proposed solutions do retrieve the data sorted faster, they all have a DML penalty and therefore my answer to these type of scenarios is 'it depends' and the best solution will only emerge after proper testing.
In a transactional system (OLTP) it might not be acceptable the extra cost of DML statements and therefore all methods should be discarded. On the other hand, if the performance gained on selecting the data outperforms the update cost penalty, then it's worth considering all three options.
In a Data Warehouse system, it might be acceptable to slow down DML statements, such as during the ETL process and therefore, all methods might be considered.
