

Before the invention of shortcuts in Microsoft Fabric, big data engineers had to create pipelines to read data from external sources such as Amazon Web Services (AWS) S3 buckets and write into Azure Data Lake Storage. This duplication of data is at risk of becoming stale over time. Additionally, computing power might be wasted on bringing over data that is used one time. With today’s companies being comprised of mergers and acquisitions over time, your company’s data landscape might exist in multiple cloud vendors. How can we virtualize the data stored in S3 buckets in our Microsoft Fabric Lakehouse design?
Business Problem
Our manager has asked us to create a virtualized data lake using AWS S3 buckets and Microsoft Fabric Lakehouse. The new shortcut feature will be used to link to both files and delta tables. Most of the article will be centered around setting up an AWS trial account, loading data into S3 buckets, and creating a service account to access those buckets. Once the data is linked, a little work will be needed to either create a managed delta table or test linked delta tables. At the end of this article, the big data engineer will be comfortable with Microsoft Fabric Shortcuts using AWS S3 buckets as a source.
Register For AWS Trial
Since I do not have an existing AWS account, I need to register for a trial account. Please use this link to get started.
There are many different sections to fill out before the account is ready to use: enter user email, validate user email, enter phone number, validate phone number, supply a credit card and choose a support contract. I am going to just show you a couple screens.
The above image shows the account that is associated with the root user. This is very important information since it controls the whole account. The image below shows the support contracts. Since I am an experienced developer, I do not want help at this time.
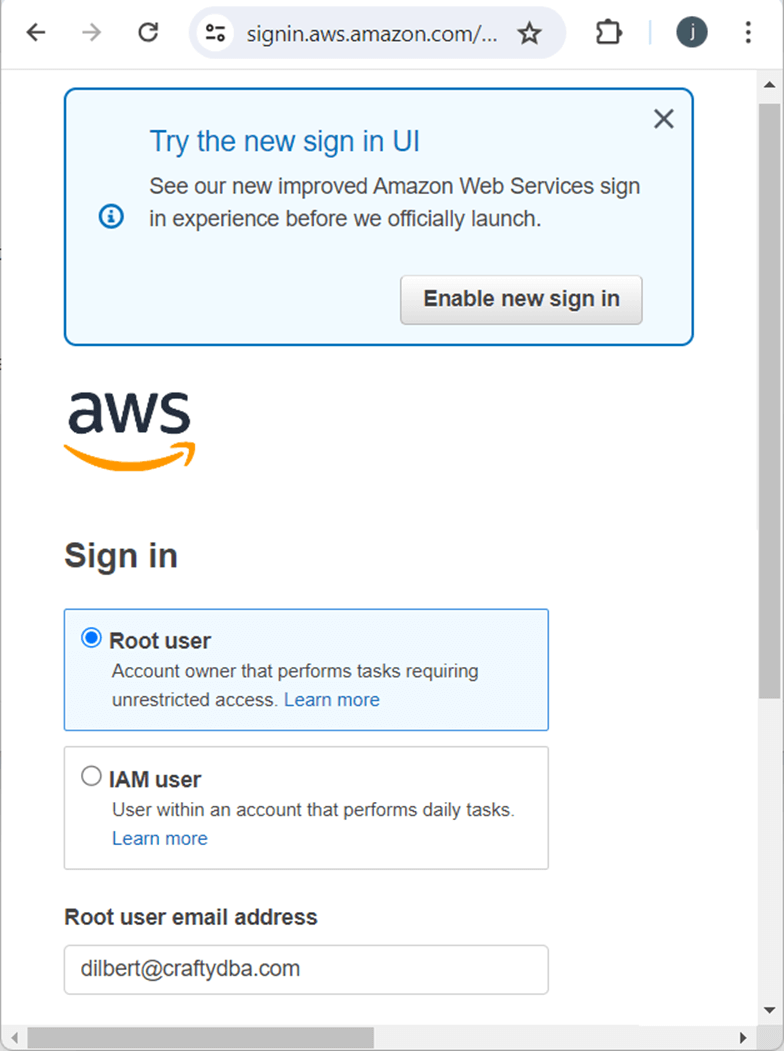
Use the root account to sign into the AWS console right now.
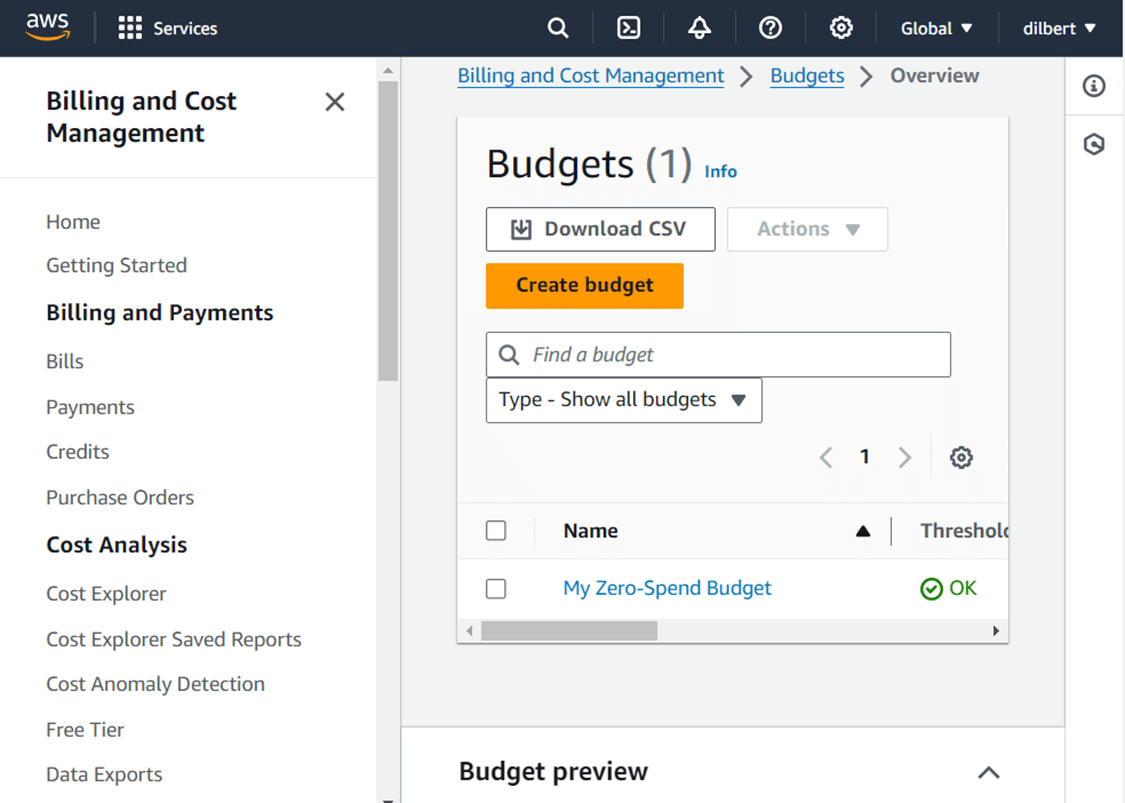
Since my credit card is backing this trial account, I want to set up a budget so that I am notified if any charges are incurred over the free trial period.
Now that we have an account, it is time to upload some data to an S3 bucket and create a service user to access the bucket. These topics will be covered in the upcoming sections.
Create a Storage Bucket
Please deploy a S3 Storage Bucket in the US East Region number 1 using the General Purpose tier.
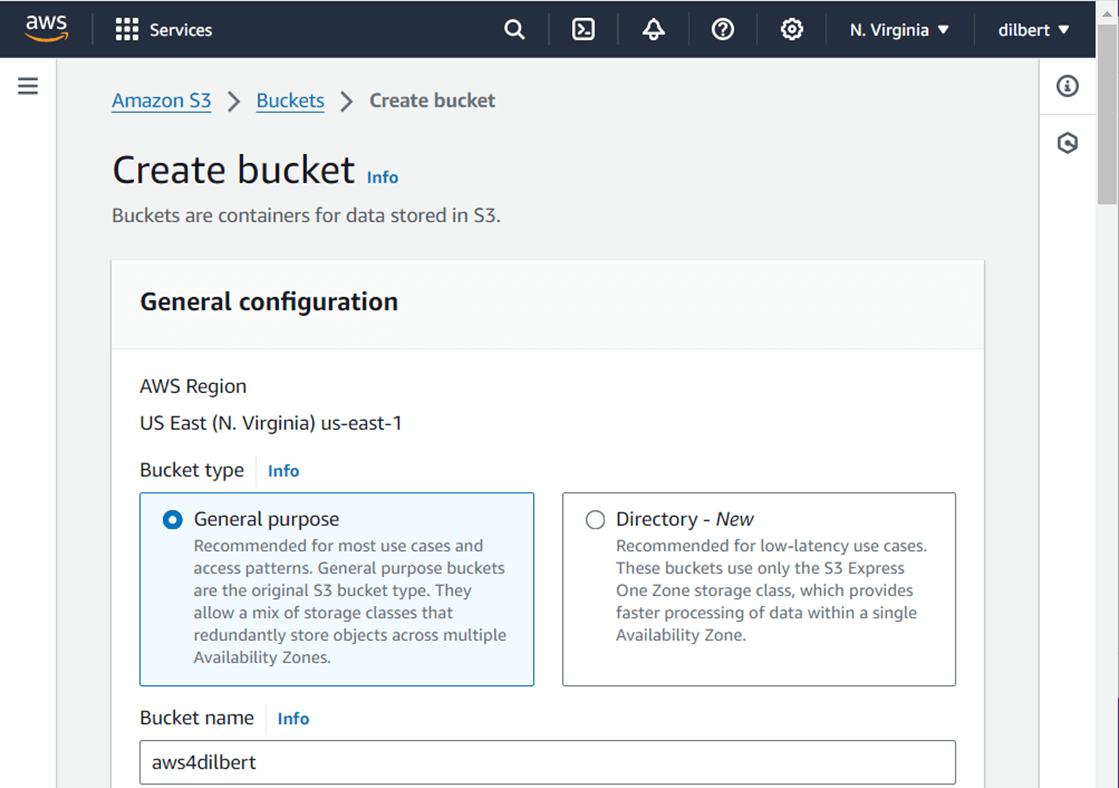
The image below shows the successful deployment of the bucket named “aws4dilbert”.
Use the upload button for folders to load data files for the years 2013 (508 files) and 2014 (506 files).
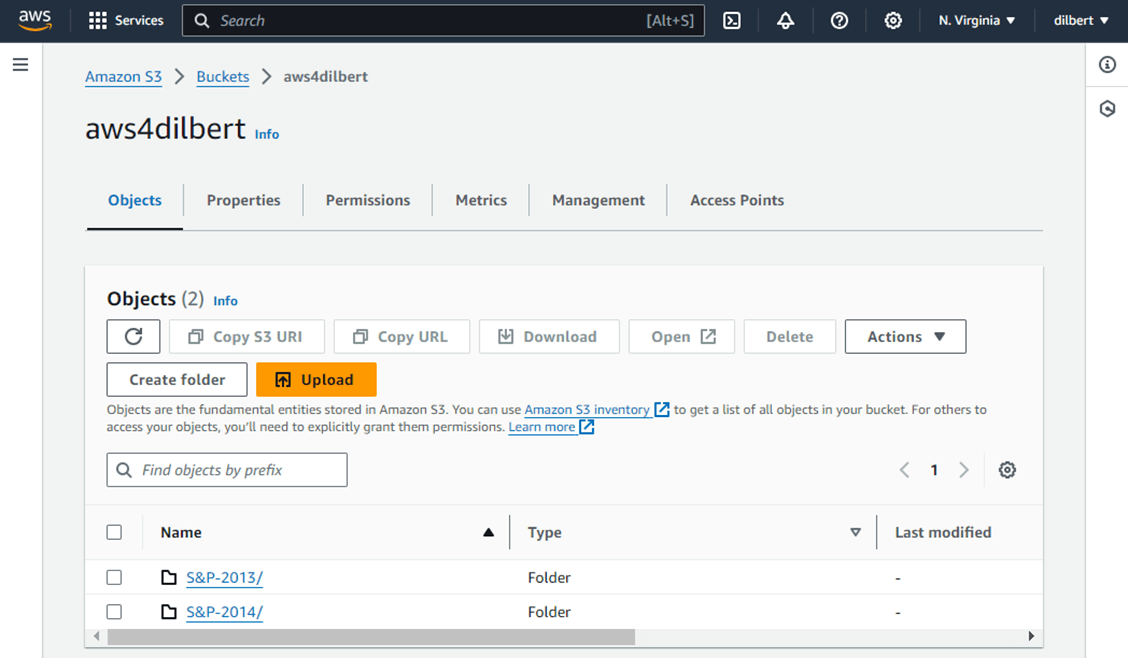
We now have two directories (folders) in which we can create shortcuts to using Microsoft Fabric. In Microsoft Azure, we typically create a service principle for this type of application connection. In the next section, we will learn how AWS creates service users.
Create a User Account
Amazon Web Services has two IAM services. One is for creating identities for users and setting up Multi Factor Authentication (MFA) which is usually assigned to a region and another IAM service is global and controls access to services. We want to create a user named “fabricshortcuts” that does not have console access then setup access keys after we deploy the user.
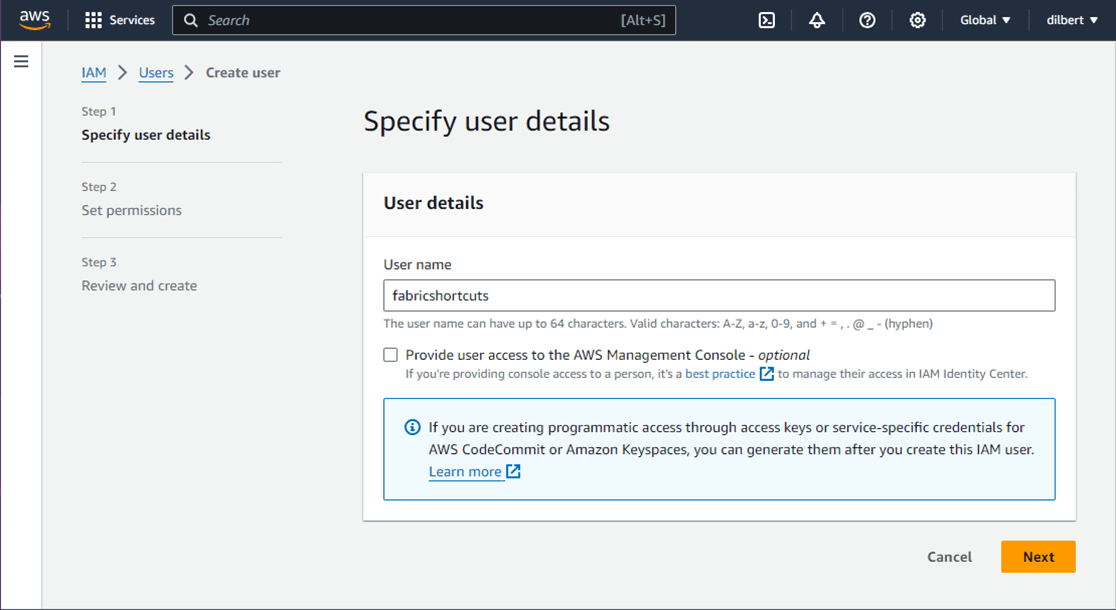
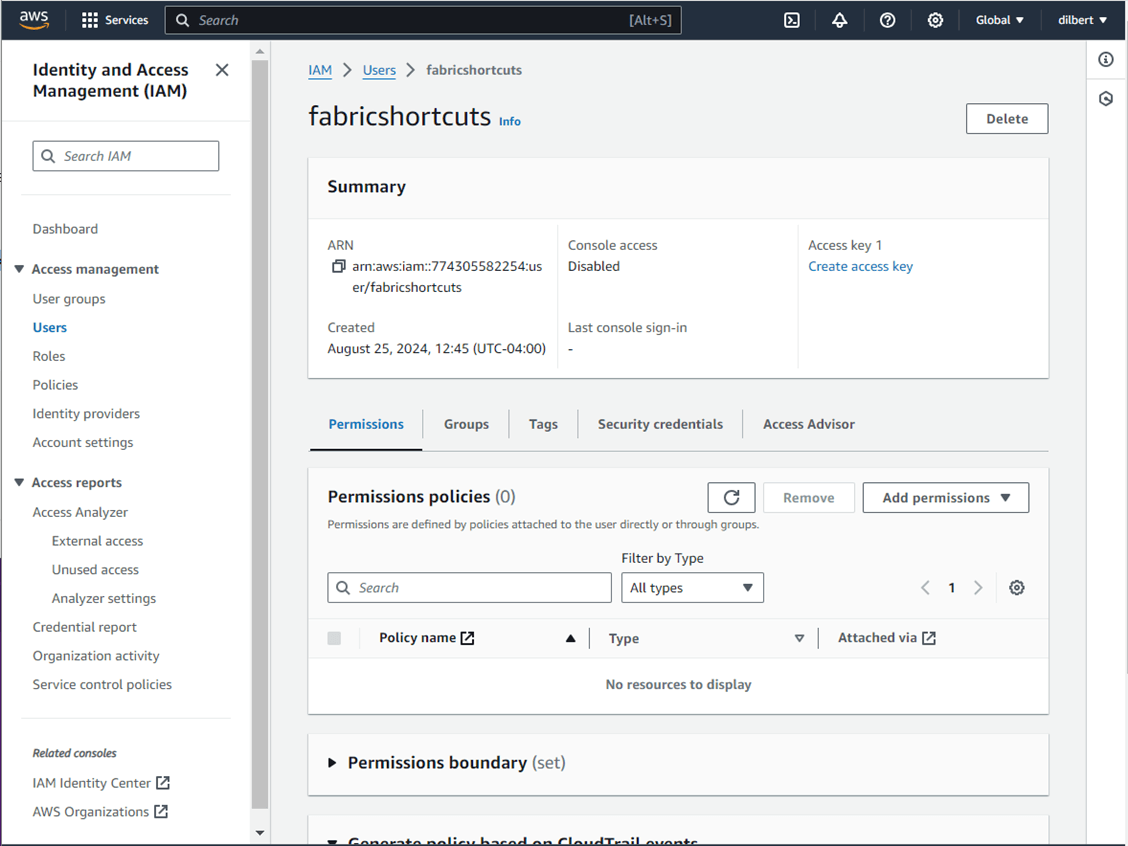
I found that setting permissions after deploying the user is easier than the wizard. The image below shows the new user. Let us create an access key at this time.
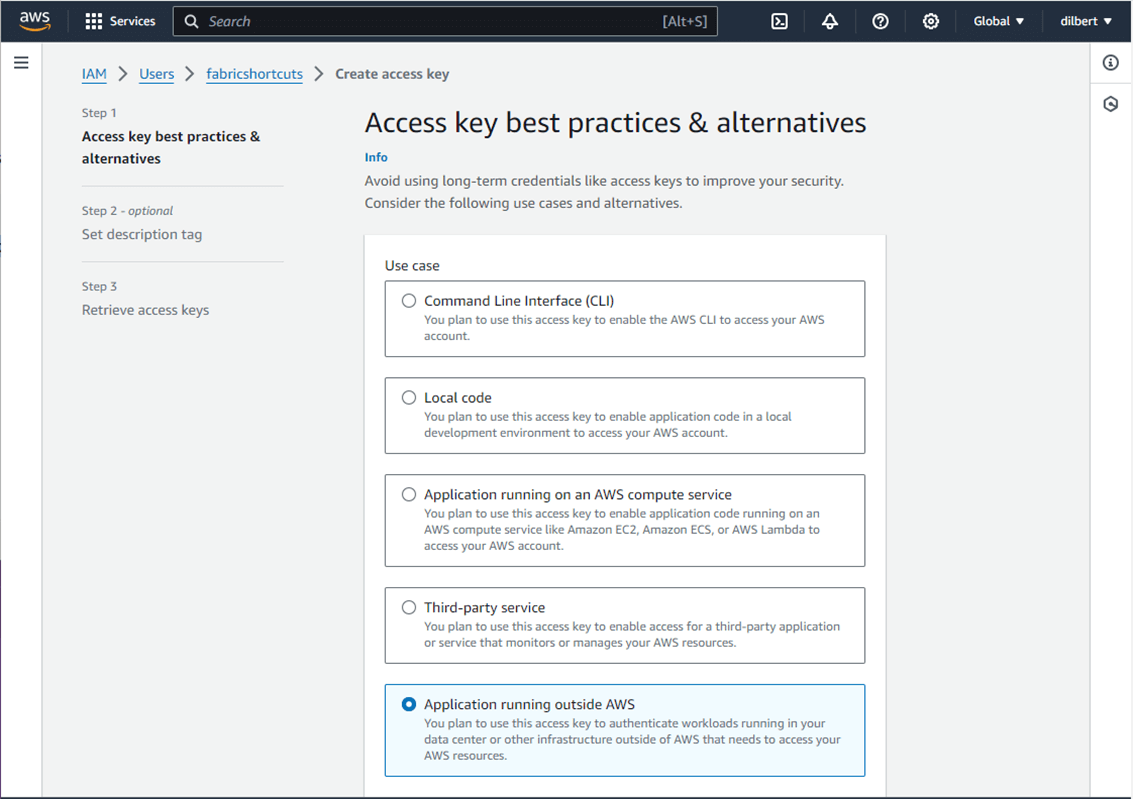
Amazon Web Services will complain about static access keys for an application (Software as a Service) such as Microsoft Fabric. However, it is fine if we restrict the surface area for possible attacks.
The secret for the access key is only viewable one time. Please capture this information at this time.
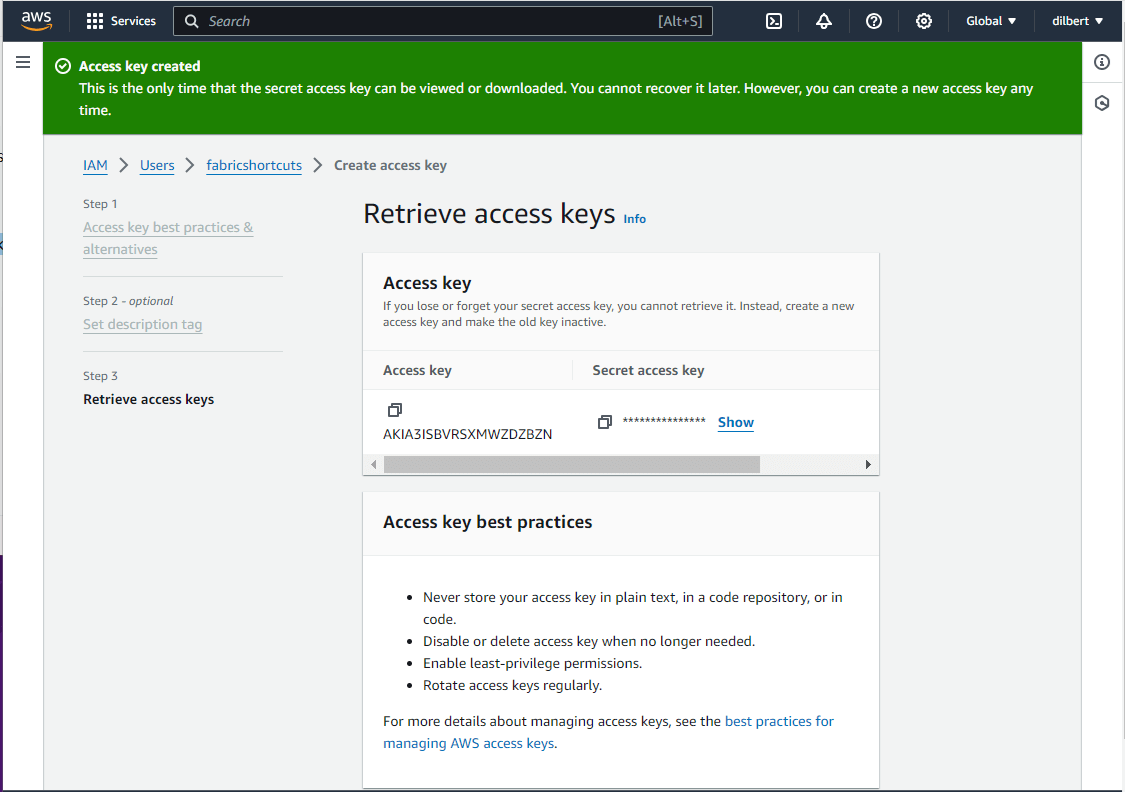
I was confused by AWS’s terms of permission boundary vs permission policy. The boundary is the maximum permissions a user can have, and a policy is the permissions that are actually granted. We want the service user to have full access to S3 buckets.
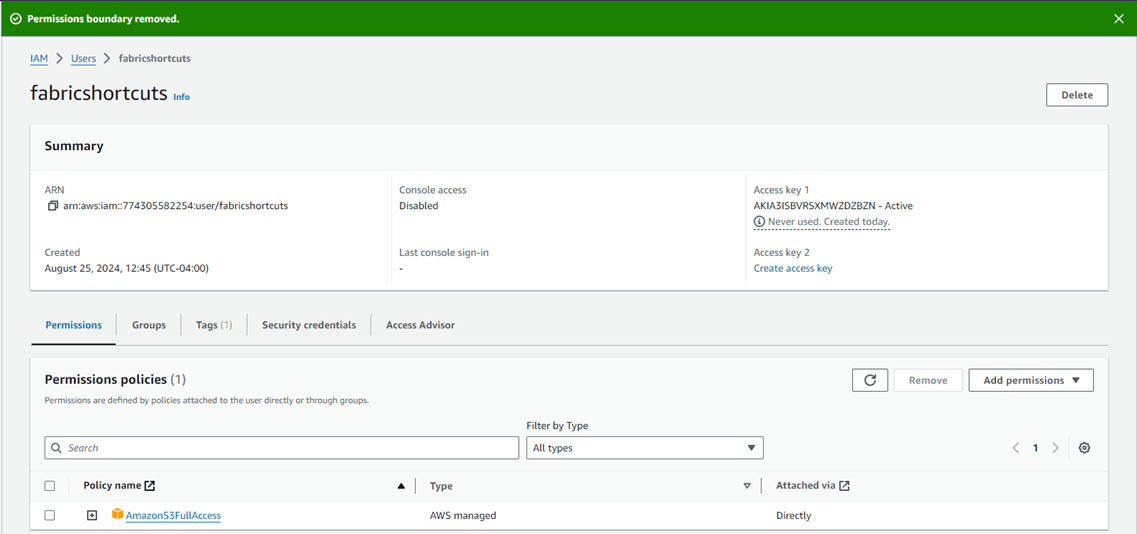
To recap, an access key can be made for the root directory user. This is bad practice since that account has full access. The IAM Identity Center reminds me of Active Directory (Entra Id). You can create users, assign MFA, manage groups and assign policies. These policies are chosen when a user signs in and at that time, there was an Access Key, Access Secret, and Access Token. However, these are short lived credentials that disappear after the session times out or user logs out. The best practice is to create a user that does not have console access and has the correctly assigned privileges.
Test the Access Key/Secret
Microsoft Power Shell is installed on all windows operating systems. I am choosing the newest version that can be configured with VS Code and is cross platform capable. Please see the documentation on installation of the pstools for AWS.
# ******************************************************
# *
# * Name: aws-s3-bucket.ps1
# *
# * Design Phase:
# * Author: John Miner
# * Date: 08-25-2024
# * Purpose: Download files from AWS S3 bucket.
# *
# ******************************************************/
# Install-Module -name AWSPowerShell.NetCore
# load module
Import-Module AWSPowerShell.NetCore
#
# Allow small packets to go
#
# Turn off this algorithm
[System.Net.ServicePointManager]::UseNagleAlgorithm = $false
# save credential
Write-Host "save credential"
$profile='my-credentials'
Set-AWSCredential -AccessKey 'AKIA3ISBVRSXMWZDZBZN' -SecretKey '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' -StoreAs $profile
# get credential
Write-Host "get credential"
Get-AWSCredential -ProfileName $profile
# get file list
Write-Host "get file list"
$list = Get-S3Bucket -ProfileName $profile | `
? { $_.BucketName -like '*aws4dilbert*' } | `
Get-S3Object -ProfileName $profile | `
? { $_.Key -like '*MSFT*.CSV' }
# show file list
$list
# download files
Write-Host "download files"
$list | Read-S3Object -ProfileName $profile -Folder 'C:\aws-s3-test'
The Set-AWSCredential cmdlet stores our key and secret in local storage. The Get-AWSCredential cmdlet retrieves this information for use in the current session. The Get-S3Bucket cmdlet returns an array of buckets and the Get-S3Object cmdlet returns an array files. We are using filtering to bring back only Microsoft Stock Files from our named storage account. The image below shows the two files that match the filtering.
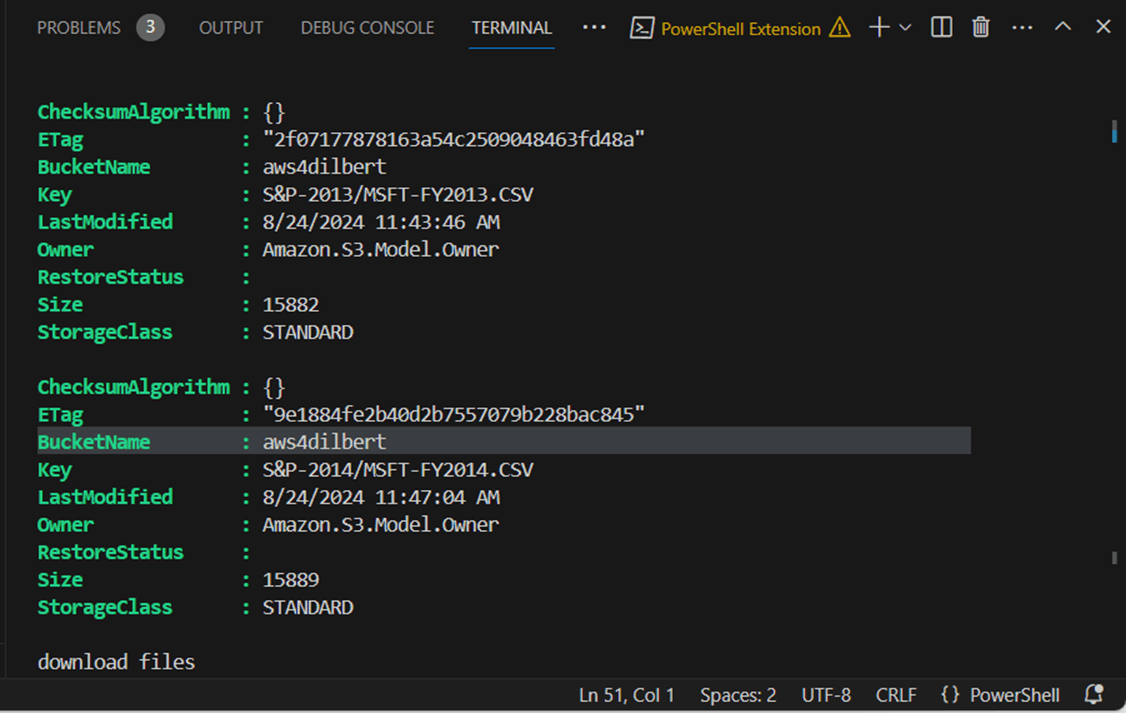
The Read-S3Object cmdlet downloads the files to local storage while preserving directory structures in the cloud. The results are stored in a directory called “aws-s3-test” on the C drive.
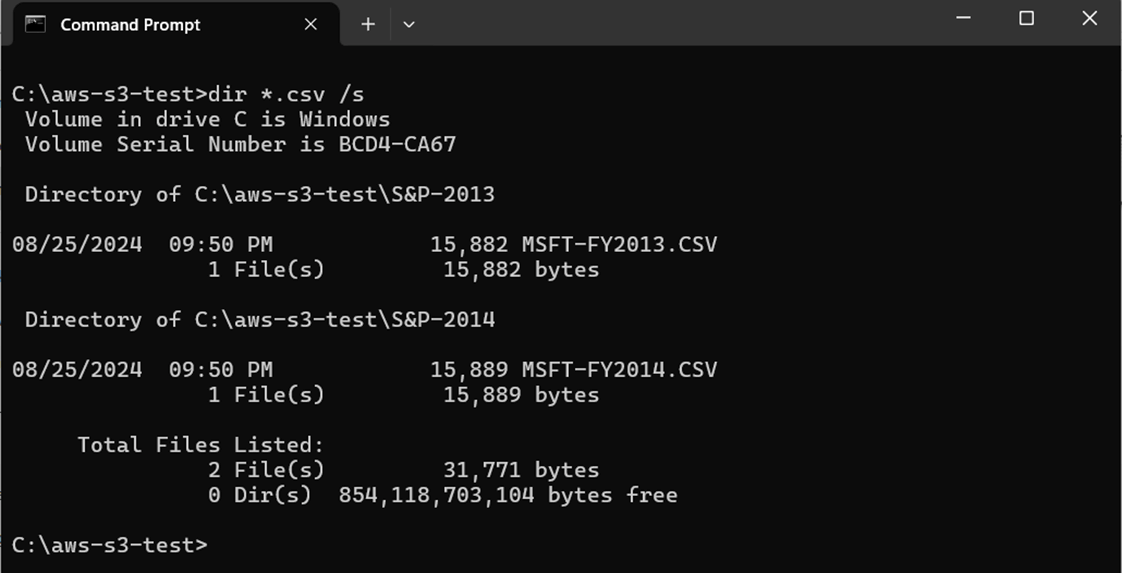
I was disappointed in the download speed supported by AWS S3 buckets using the Power Tools for Power Shell. There is a line in the above script that turns the naggle algorithm on/off. In the past, I have had luck speeding up performance by using this code. However, it had no effect with AWS. In short, we have validated the access key and secret.
File Shortcuts
The Fabric Lakehouse has a section for storing files. Right click the ellipsis and select create shortcut. See image below for details.
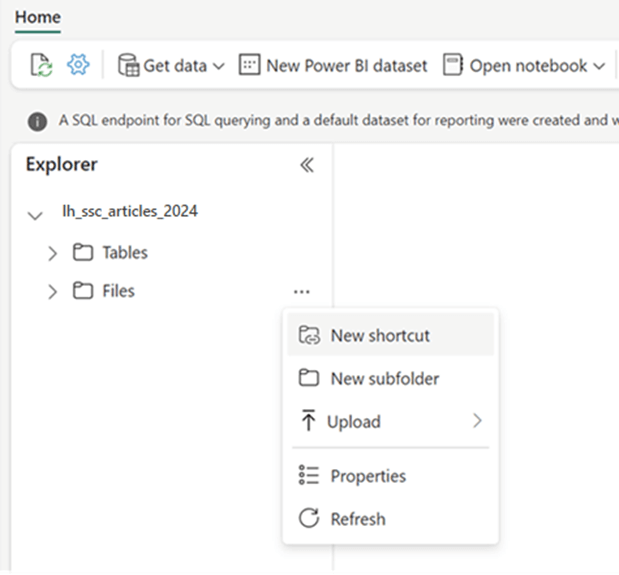
The first step is to create an Amazon S3 short cut by supplying the following information: URL for bucket, Access Key and Access Secret.
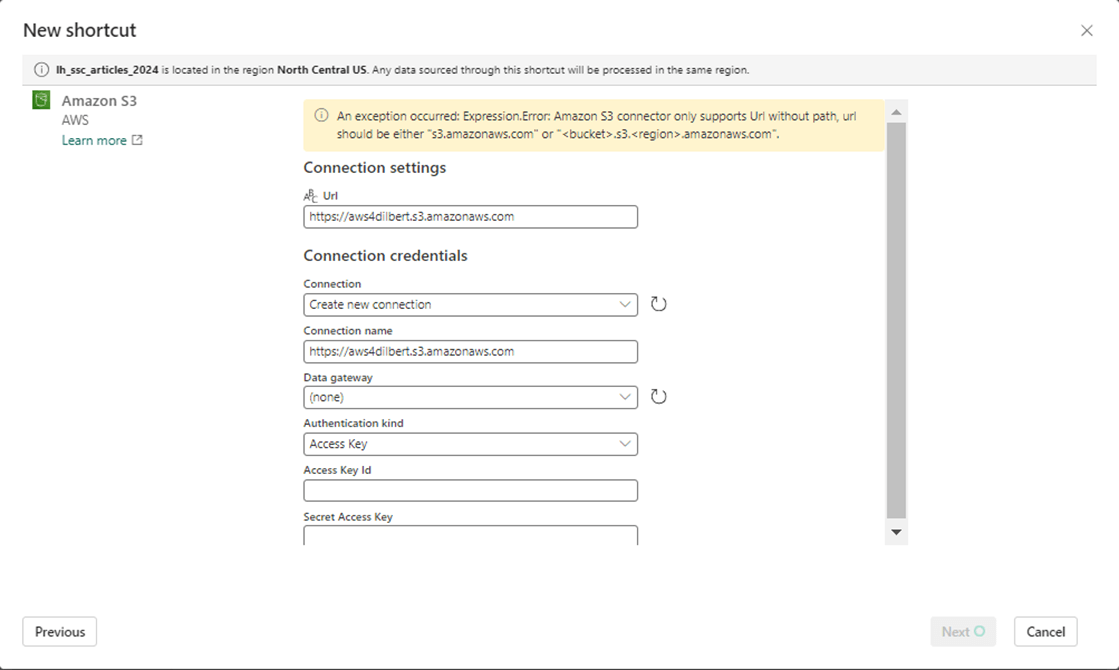
We want the links to be at the subdirectory level. Thus, the 2013 and 2014 folders are exposed to the developer. They look like normal folders.
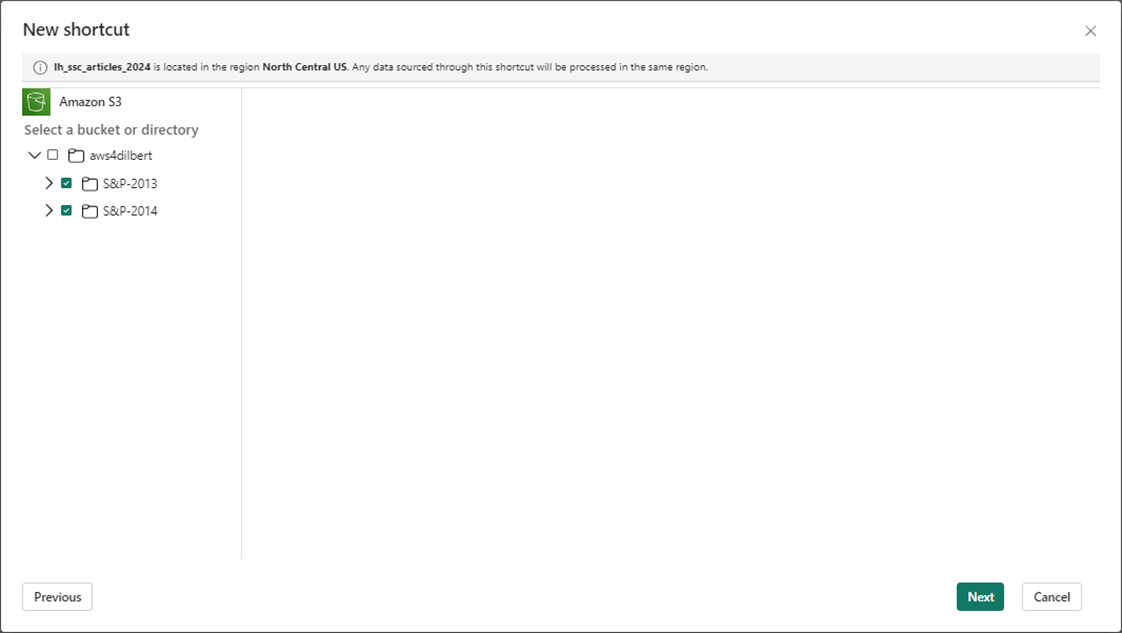
Of course, the user interface in Fabric is prompting us to confirm our actions.
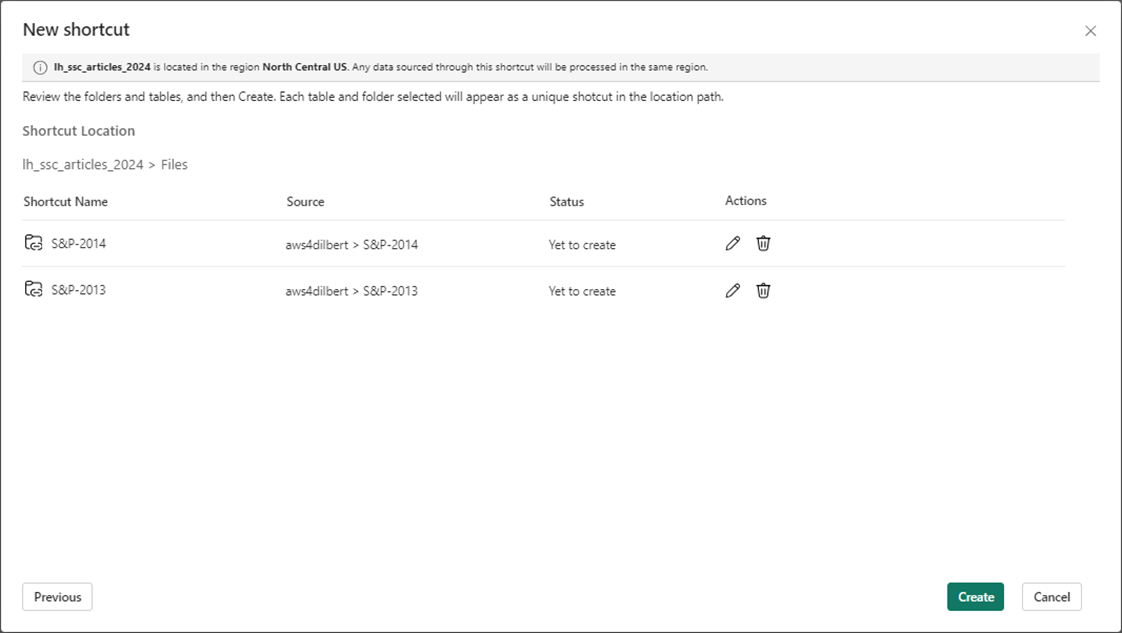
Because the short cut is only a virtual link to the files in the S3 bucket, we need to read in both Microsoft files, combine the files into one dataframe, and write the dataframe out as a managed table.
Here is the code to read 2013 data file.
#
# Read 2013 data file
#
df1 = spark.read.option("header","true").format("csv").load("Files/S&P-2013/MSFT-FY2013.CSV")
cnt1 = df1.count()
print (f"The number of trading days in 2013 is {cnt1}.")
Here is the code to read 2014 data file.
#
# Read 2014 data file
#
df2 = spark.read.option("header","true").format("csv").load("Files/S&P-2014/MSFT-FY2014.CSV")
cnt2 = df2.count()
print (f"The number of trading days in 2014 is {cnt2}.")This is the code to union dataframes and write managed delta table.
#
# Write local delta table - combine dfs
#
# del tbl
stmt = "drop table if exists msft_stock_data"
spark.sql(stmt)
# add tbl
df3 = df1.union(df2)
df3.write.saveAsTable("msft_stock_data")
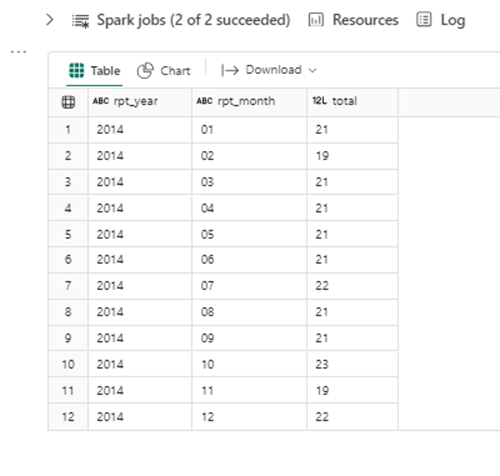
We always want to test our code. The Spark SQL below summarizes the number of trading days by month. Volumes with zero values are dividends that we paid to customers.
-- -- Summarize msft stock data -- select substr(date, 7, 4) as rpt_year, substr(date, 1, 2) as rpt_month, count(*) as total from msft_stock_data where volume <> 0 AND substr(date, 7, 4) = 2014 group by substr(date, 7, 4), substr(date, 1, 2) order BY 2
The image below shows the summarized results. A typical month has between 19 and 23 days of stock trading.
As an end user, one might wonder if we can write to a shortcut? The code below uses the put method of the file system class within the mssparkutils library.
# # Short cuts are read only # path = "Files/S&P-2014/SSC-ARTICLE" contents = "Working with AWS S3 buckets. Shortcuts are read only." mssparkutils.fs.put(path, contents, True)
Of course, the code errors out since short cuts are read only.

Behind the scenes, shortcuts cache any file less than 1 Gigabytes in Microsoft Fabric for 24 hours. The retention period is reset each time they are accessed. If you create a Files shortcut, you should consume the data into managed tables. In the next section, we will discuss how remote delta tables appear as tables when shortcuts are created under the Tables section.
Table Shortcuts
The first step is to load some data into our S3 bucket. I dumped the tables from the Microsoft Fabric Warehouse into delta tables within a Lakehouse. Next, I used Azure Storage Explorer to save these files to my local disk. The next step is to load the delta tables for the pubs database into a S3 bucket in AWS.
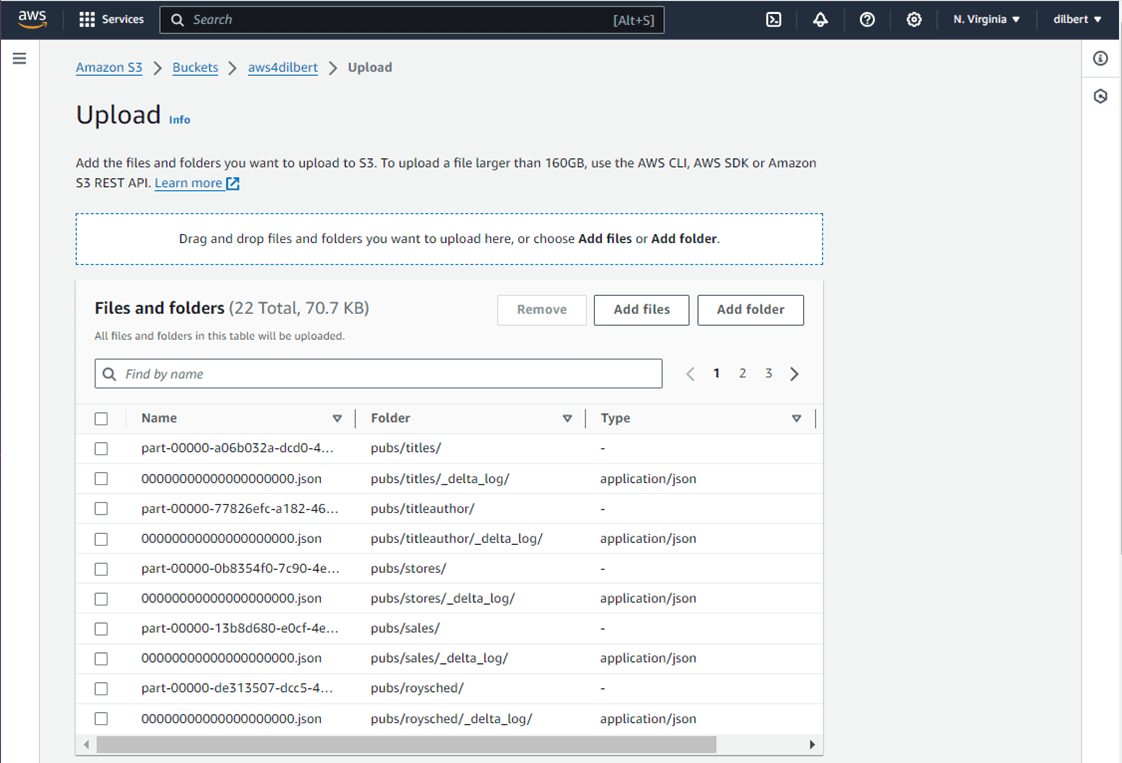
Again, make the folder selection at the bottom leaves of the directory structure. There are a total of eleven delta tables.
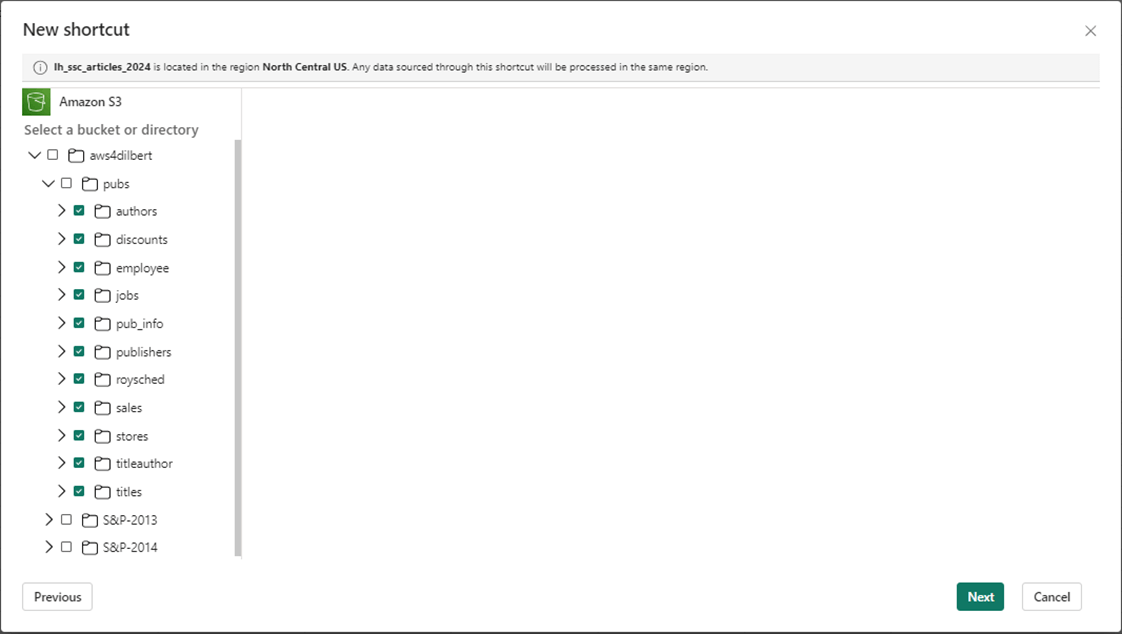
Microsoft Fabric will ask you to confirm the shortcut creation. Select create to finish this task.
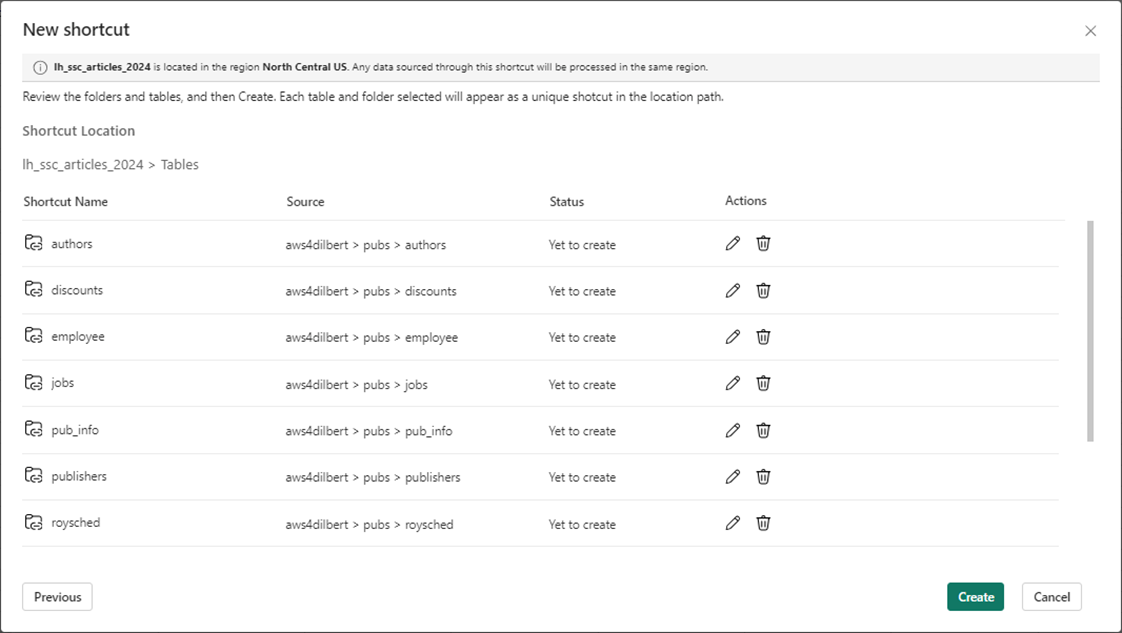
The image below shows I am multi-tasking between the Microsoft Fabric and Amazon Web Services consoles. Please see the preview feature of the authors table has returned data. Notice that shortcuts have a link icon in the image. This appears on both the table and file shortcuts.
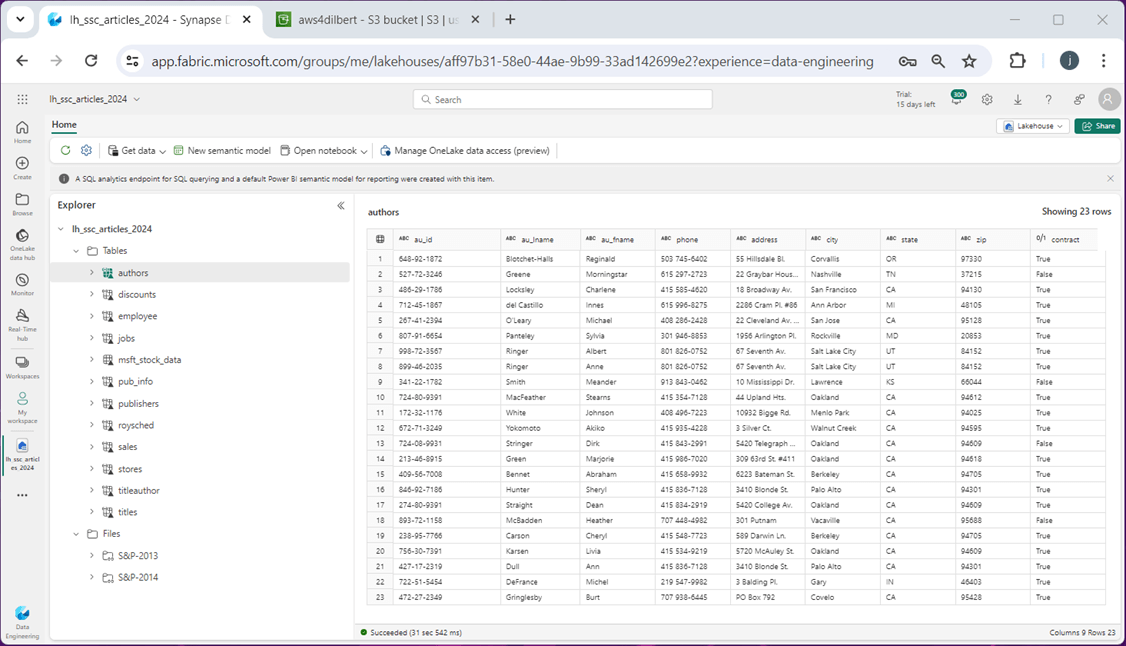
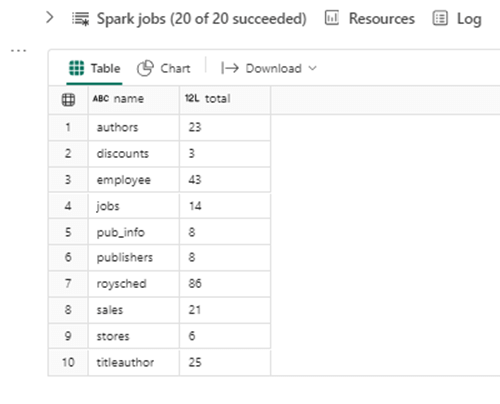
One way to test all the table shortcuts is to write a big Spark SQL query. The query below unions the row counts in each shortcut table.
%%sql -- table #1 select "authors" as name, count(*) as total from authors -- table #2 union select "discounts" as name, count(*) as total from discounts -- table #3 union select "employee" as name, count(*) as total from employee -- table #4 union select "jobs" as name, count(*) as total from jobs -- table #5 union select "pub_info" as name, count(*) as total from pub_info -- table #6 union select "publishers" as name, count(*) as total from publishers -- table #7 union select "roysched" as name, count(*) as total from roysched -- table #8 union select "sales" as name, count(*) as total from sales -- table #9 union select "stores" as name, count(*) as total from stores -- table #10 union select "titleauthor" as name, count(*) as total from titleauthor
The expected output is shown below. Table shortcuts are a great way to get data virtually into your lakehouse.
Summary
The creation of the AWS resources was the hardest part of this article. When creating shortcuts to an S3 bucket, you need to create a user that does not have access to the console. Give the user rights to the S3 buckets and create an Access Key. Microsoft PowerShell can be used to valid the authenticity of the credentials.
There are two types of shortcuts. File shortcuts point to folders in the S3 bucket. The files in these buckets can be of any type that the Spark Engine can read. By themselves, these files are not useful. Use the Spark Engine to read, translate and write the information to a delta table. Managed delta tables are where you want to be. One Lake shortcuts or shortcuts to Tables require the source data to be in a delta file format. Selecting the lowest level folder in the directory structure makes each folder look like a table. Up to 50 shortcuts can be created at one time using the graphical user interface within the Fabric console.
To summarize, shortcuts are read only pointers to tables and files. The tables can stand by themselves since they are in the delta file format. The files have to be ingested into your local One Lake to be of any reporting value. I really like shortcuts and will be exploring the other two cloud vendors in the future.