

The OVER() clause can be used in a variety of situations. Here, we’ll see how it can help us to remove duplicate rows from a heap table with no primary key or unique identifier.
The Problem
Once upon a time I was consulting for an insurance company. The usual kind of thing…build a database to handle policies, fix issues with the existing system, import data into the new system from the old and so on. They used Tableau for statistical purposes. This meant data sources were required to allow Tableau to access SQL Server.
At the time, Tableau didn’t support stored procedures, so the approach was to develop views, which could be queried straight from Tableau. The development team created a number of flat tables, which housed the data needed by each individual Tableau view. So far, so good. Unfortunately, somebody (it wasn’t me!) accidentally set up duplicate schedules in SQL Agent…resulting in data being imported twice! Obviously this knocked our statistics out. How to remove the duplicates? Well, there are lots of ways of handling this, but we went with the OVER() clause. Read on to see how it can be done…
The Data
The script below gives a simplified view of one of the tables we needed to fix.
CREATE TABLE dbo.InsurancePolicy ( PolicyId INT, FirstName VARCHAR(100), Surname VARCHAR(100), PolicyStartDate DATE, PolicyEndDate DATE );
Here’s an example of the data this table contained (all names have been changed to protect the innocent – if you’re in here you’re either famous, I know you, or you were in AdventureWorks!).
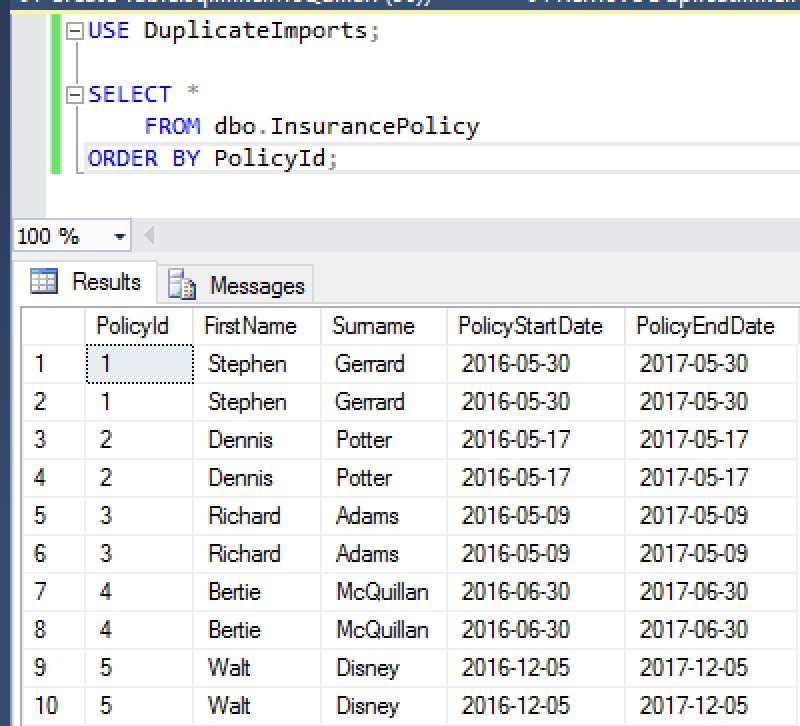
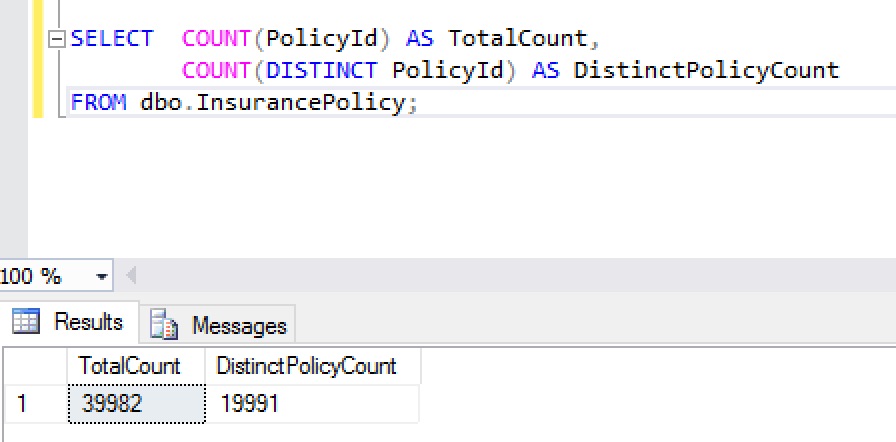
Oh dear…two of everybody! We can confirm this by running a couple of counts.
Removing the Duplicates
If we had a primary key, removing the duplicates would be easy. Each row would have a unique identifier and we could use that to identify duplicates. We don’t have that luxury here, so we’ll use OVER() with ROW_NUMBER() to give each row an ID. We’ll split the data up by PolicyId, FirstName, Surname, PolicyStartDate and PolicyEndDate (i.e. we’ll partition using all columns). We can then just keep rows with a row number of 1. The full process is:
- Dump the data into a temp table, with a row number assigned
- Each row should have a row number of either 1 or 2 (because we’ve partitioned using all columns)
- Remove all rows where row number > 1
- Empty the target table
- Insert the rows from the temp table
The Clean-up Script
The full script to remove the duplicates isn’t particularly big.
USE DuplicateImports; DECLARE @TargetRowCount INT, @ActualRowCount INT; -- Figure out how many rows we expect to have at the end of the import -- As each row has been imported twice, we can simply divide the row count by 2 IF EXISTS (SELECT 1 FROM dbo.InsurancePolicy) BEGIN; SELECT @TargetRowCount = COUNT(1) / 2 FROM dbo.InsurancePolicy; END; -- Dump data into temp table, assigning a row number to identify duplicates SELECT ROW_NUMBER() OVER (PARTITION BY PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate ORDER BY PolicyId) AS RowNumber, PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate INTO #allpolicy FROM dbo.InsurancePolicy; -- Clear out duplicates from temp table DELETE FROM #allpolicy WHERE RowNumber > 1; IF (@TargetRowCount > 0 AND EXISTS(SELECT 1 FROM #allpolicy)) BEGIN; BEGIN TRANSACTION; TRUNCATE TABLE dbo.InsurancePolicy; INSERT INTO dbo.InsurancePolicy (PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate) SELECT PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate FROM #allpolicy; SELECT @ActualRowCount = COUNT(1) FROM dbo.InsurancePolicy; IF (@TargetRowCount = @ActualRowCount) BEGIN; COMMIT TRANSACTION; PRINT 'Update successful. Duplicates removed.'; END; ELSE BEGIN; ROLLBACK TRANSACTION; PRINT 'Update failed - target row count does not match actual row count after processing.'; END; DROP TABLE #allpolicy; END;
Let’s work through this. We begin by declaring a couple of variables, one to hold the row count we expect to hit at the end of the process (@TargetRowCount), and another to store the actual number of rows the target table contains after the update completes (@ActualRowCount). We can use these to check if we need to roll back or commit the change.
DECLARE @TargetRowCount INT, @ActualRowCount INT; -- Figure out how many rows we expect to have at the end of the import -- As each row has been imported twice, we can simply divide the row count by 2 IF EXISTS (SELECT 1 FROM dbo.InsurancePolicy) BEGIN; SELECT @TargetRowCount = COUNT(1) / 2 FROM dbo.InsurancePolicy; END;
We only set the @TargetRowCount if some data exists in the InsurancePolicy table. We figure out the @TargetRowCount by dividing the table count by 2.
Now we need to dump the data into a temp table. This is where our OVER() clause comes in.
-- Dump data into temp table, assigning a row number to identify duplicates SELECT ROW_NUMBER() OVER (PARTITION BY PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate ORDER BY PolicyId) AS RowNumber, PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate INTO #allpolicy FROM dbo.InsurancePolicy;
We put the rows into a temporary table called #allpolicy. The key part of this statement is the OVER() clause:
ROW_NUMBER() OVER (PARTITION BY PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate ORDER BY PolicyId) AS RowNumber,
ROW_NUMBER() assigns an individual row number to each row. The PARTITION BY command splits the rows into sub-sections. We’re partitioning on all columns in the table. Here’s how the rows we looked at earlier will be partitioned.

We’ll see how this looks in the temp table in a moment. From this point on, the script is pretty self-explanatory (but I’ll explain it anyway!). We firstly remove all rows where the row number is greater than 1:
-- Clear out duplicates from temp table DELETE FROM #allpolicy WHERE RowNumber > 1;
If there is something to process, we start up a transaction, empty the target table, and insert the data from the temp table.
IF (@TargetRowCount > 0 AND EXISTS(SELECT 1 FROM #allpolicy)) BEGIN; BEGIN TRANSACTION; TRUNCATE TABLE dbo.InsurancePolicy; INSERT INTO dbo.InsurancePolicy (PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate) SELECT PolicyId, FirstName, Surname, PolicyStartDate, PolicyEndDate FROM #allpolicy; SELECT @ActualRowCount = COUNT(1) FROM dbo.InsurancePolicy; IF (@TargetRowCount = @ActualRowCount) BEGIN; COMMIT TRANSACTION; PRINT 'Update successful. Duplicates removed.'; END; ELSE BEGIN; ROLLBACK TRANSACTION; PRINT 'Update failed - target row count does not match actual row count after processing.'; END; DROP TABLE #allpolicy; END;
Running the Script
As I mentioned earlier, the script will create a temp table and populate that table with all of the data, assigning a row number to each matching pair of records. Let’s take a look at some of the data in that temp table.
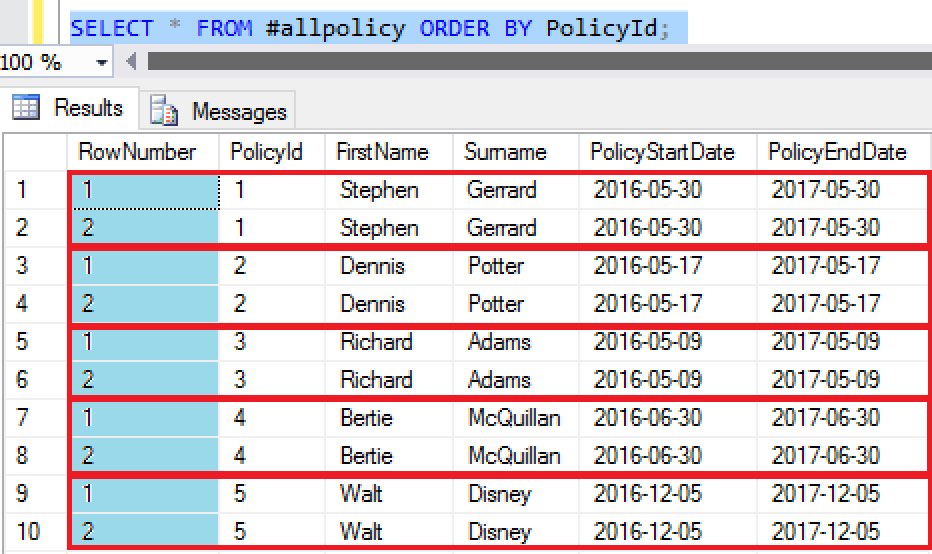
The red lines clearly show our individual recordsets. Look at the first column, which is highlighted. It’s the RowNumber column, and each record in each set has either 1 or 2 as the RowNumber value. The OVER() clause did this, with the help of ROW_NUMBER() and its PARTITION BY component.
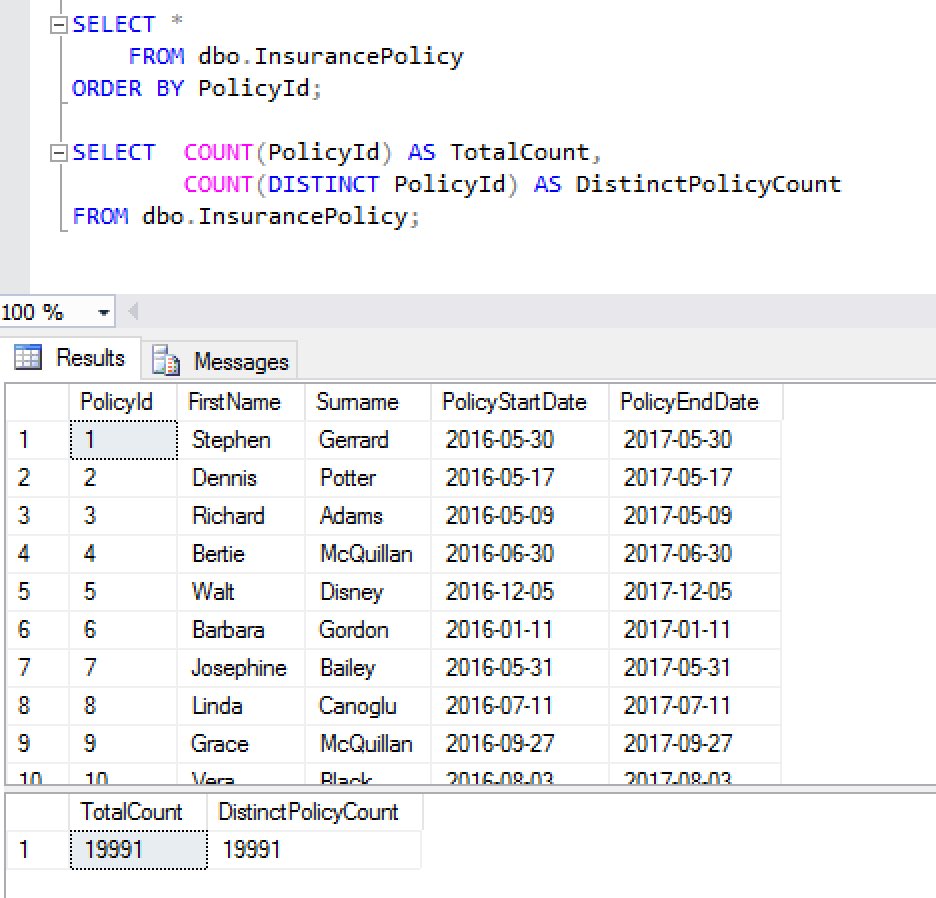
From here, it’s a home run. The DELETE line clears out all rows with a RowNumber value greater than 1, leaving us with one copy of each individual row. We then check the row counts – if they match, we wipe out everything in the target table (dbo.InsurancePolicy), then insert everything that’s left in the temp table. Which leaves us with a perfect data set (well, a data set that doesn’t contain duplicates, anyway).
Summary
The OVER() clause provides some very elegant solutions for what could, without it, be difficult problems. The PARTITION BY component allows us to create mini groups of data, which allows us to isolate duplicates and weed them out.
There are many ways OVER() can help you, so take some time to read up on it at MSDN – it might save your bacon one day!
