

Introduction
I was tasked with the data transmission, synchronization and balancing for a large project at work, so I began scrutinizing the data sources and noticed that several of our sources did not have any mechanism to signify when a row had been modified.
This presented the problem of how to effectively determine when a row had changed. Some of the staging tables would be hundreds of columns wide and inevitably some hand-coded field comparisons would be missed, duplicated or otherwise mangled due to NULL comparisons – all which would then lead to synchronicity issues.
It was distasteful to me, but I began with the knee-jerk approach of performing column-by-column comparisons, and in the process I wondered if I could somehow leverage the EXCEPT statement.
The EXCEPT Statement
In the simplest sense, the EXCEPT statement is used to compare the differences between two sets of data. As long as the number of columns are the same, order, data types and nullability, it quickly returns all rows from the first set of data that do not lie within the second.
Common examples look similar to the following:
SELECT [t1].[ID]
, [t1].[Col1]
, [t1].[Col2]
FROM [table1] [t1]
EXCEPT
SELECT [t2].[ID]
, [t2].[Col1]
, [t2].[Col2]
FROM [table2] [t2];Which as stated, would return all rows from table1 that do not have an exact match in table2.
Perhaps the most attractive quality about the EXCEPT statement is the fact that it treats null values as equal to each other. Typically this is not the case and this means that they must be handled with special logic on a column-by-column basis to perform a comparison and can impose logic issues when handled inadequately.
Comparing Row Differences
The EXCEPT statement had a lot going for it: I would not have to specify a comparison for each column, it handled null values desirably and, as long as its rules are met there was nothing complicated that would yield unexpected results.
This really did not help me with the task at hand though, and in mulling the problem over I realized that a slight change in approach would let me leverage the EXCEPT statement.
If we constrain the keys between the two sets to be equal, then any product from the EXCEPT statement will be rows where at least one of the other columns is different between them.
In other words, by joining the two datasets together by their keys, we no longer have the dataset differences between them, but the row differences.
Applying this slight modification to the example above, we have the following:
SELECT [t1].[ID]
, [t1].[Col1]
, [t1].[Col2]
FROM [table1] [t1]
INNER JOIN [table2] [t2]
ON [t1].[ID] = [t2].[ID]
EXCEPT
SELECT [t2].[ID]
, [t2].[Col1]
, [t2].[Col2]
FROM [table2] [t2]
INNER JOIN [table1] [t1]
ON [t2].[ID] = [t1].[ID];This will cause the EXCEPT statement to compare each equivalent row between the two sets.
A Demonstration
In order to set up the scenario, we will create two temporary tables that have the imaginative names of #Source and #Target and identical column definitions (with the noted difference of an identity attribute on the source table’s primary key.)
CREATE TABLE [#Source]
(
[ID] INT NOT NULL
PRIMARY KEY
IDENTITY(1, 1)
, [Item] VARCHAR(100) NOT NULL
UNIQUE
, [Price] MONEY NOT NULL
, [OrderDate] DATE NOT NULL
, [Units] NUMERIC(10, 4) NULL
, [ShipmentDate] DATE NULL
);
CREATE TABLE [#Target]
(
[ID] INT NOT NULL
PRIMARY KEY
, [Item] VARCHAR(100) NOT NULL
UNIQUE
, [Price] MONEY NOT NULL
, [OrderDate] DATE NOT NULL
, [Units] NUMERIC(10, 4) NULL
, [ShipmentDate] DATE NULL
);Let’s insert some initial values into our source table to set up our scenario. We will then duplicate the data by bulk-copying them to our target so that we can start with equivalent datasets.
INSERT INTO [#Source]
( [Item], [Price], [OrderDate], [Units], [ShipmentDate] )
VALUES ( 'Apple', 2.49, '1/1/2001', NULL, '1/02/2001' )
, ( 'Coconut', 0.99, '3/3/2003', 1.35, '3/4/2003' )
, ( 'Eggplant', 1.19, '5/5/2005', NULL, '5/6/2005' )
, ( 'Fig', 0.49, '6/6/2006', NULL, '6/7/2006' )
, ( 'Kiwi', 0.69, '11/11/2011', NULL, '11/12/2011' )
, ( 'Lychee', 0.29, '12/12/2012', NULL, '12/14/2012' );
INSERT INTO [#Target]
( [ID]
, [Item]
, [Price]
, [OrderDate]
, [Units]
, [ShipmentDate]
)
SELECT .[ID]
, .[Item]
, .[Price]
, .[OrderDate]
, .[Units]
, .[ShipmentDate]
FROM [#Source] ;We will need to test: setting a value to a null, modifying a value to another value, and finally setting a null value to a value.
UPDATE [#Source]
SET [ShipmentDate] = NULL
WHERE [Item] = 'Coconut';
UPDATE [#Source]
SET [Price] = 22.44
WHERE [Item] = 'Eggplant';
UPDATE [#Source]
SET [Units] = 1000.55
WHERE [Item] = 'Lychee';After we have run our updates, we can now run the modified EXCEPT statement query against our source and target tables.
SELECT .[ID]
, .[Item]
, .[Price]
, .[OrderDate]
, .[Units]
, .[ShipmentDate]
FROM [#Source]
INNER JOIN [#Target] [T]
ON .[ID] = [T].[ID]
EXCEPT
SELECT [T].[ID]
, [T].[Item]
, [T].[Price]
, [T].[OrderDate]
, [T].[Units]
, [T].[ShipmentDate]
FROM [#Target] [T]
INNER JOIN [#Source]
ON [T].[ID] = .[ID]; 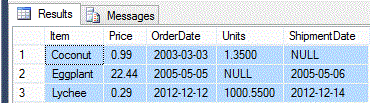
Conclusion
By joining two datasets together by their common keys, we cause the EXCEPT statement to compare the remaining columns. This approach to check row differences can reduce errors by removing the tedious hand-coding of column-by-column comparisons as well as required null-handling logic.
