

Choosing the primary key for a table is one of the most important decisions you can make when creating a table. A common debate is whether you should use a surrogate or a natural key.
What is the difference?
A natural key is a column or columns already in your data that can uniquely identify the row. For example, if you have a table called HR.Employee, which lists one employee per row, you could use social security number as a primary key. This would be a natural key.
A surrogate key is a key which you create for the purpose of being a primary key. It has no other meaning. The most common surrogate keys are identity or uniqueidentifier columns.
Storage space
A natural key is already in your data, so it doesn’t require any extra data to store it. A surrogate key must be added. That could range anywhere from 1 byte, for a tinyint column, to 16 bytes, for a uniqueidentifier column, per row for the most common applications.
So far, the natural key is taking up less space, but don’t forget related tables. Any table with a foreign key relationship to this table will take up space too. Let’s say that you have a table, called HR.Timeclock, which has clock-in and clock-out records for each employee in the HR.Employee table. The HR.Employee table has 100 rows, but the HR.Timeclock table has 730,000 rows. The HR.Timeclock table must reference the HR.Employee table by its primary key. The Social Security Number is a char(9) type because some foreign employees have codes with letters in them. That means the HR.Timeclock table must store 9 bytes of data per row for 730,000 rows for a total of about 6.3 MB of storage. Now, if the HR.Employee table uses a surrogate key of type smallint instead, then you save 7 bytes per row for a total savings of 3.5 MB.
Indexes also take space. It is very common to reference the primary key in an index, and it is also very common to use the primary key as the clustered index of the table. Every index on a table will internally reference the key of the clustered index in order to locate each row. Even when the primary key is not used to cluster the table, it is common to reference the primary key in indexes in order to make them unique. Calculating index storage size is complex and outside the scope of this article, but it can clearly be a significant amount of space in situations like these.
As seen here, it is very common for the addition of a surrogate key to actually reduce the total size.
An Example
Consider the following example. These two databases come from Microsoft’s sample AdventureWorks database. They are identical apart from a change where I removed BusinessEntityID as the natural key database in all tables, keys, and indexes. I used the NationalIDNumber instead. Looking at only the HumanResources.Employee table, you can already see a space savings without even considering the related tables.

Read performance
In the above example, the table referencing the surrogate key uses less space on disk. This will help reduce IO pressure when reading from that table.
Any index referencing a column with space savings can expect improved performance as well. In addition to the reduced IO of the actual field, any index using the column as a key column will have fewer leaf pages and result in faster searches.
In these example queries, the only difference is the use of a surrogate vs natural key.

When you look at the execution plan below, you can see that selecting from the query using a surrogate key is significantly cheaper.
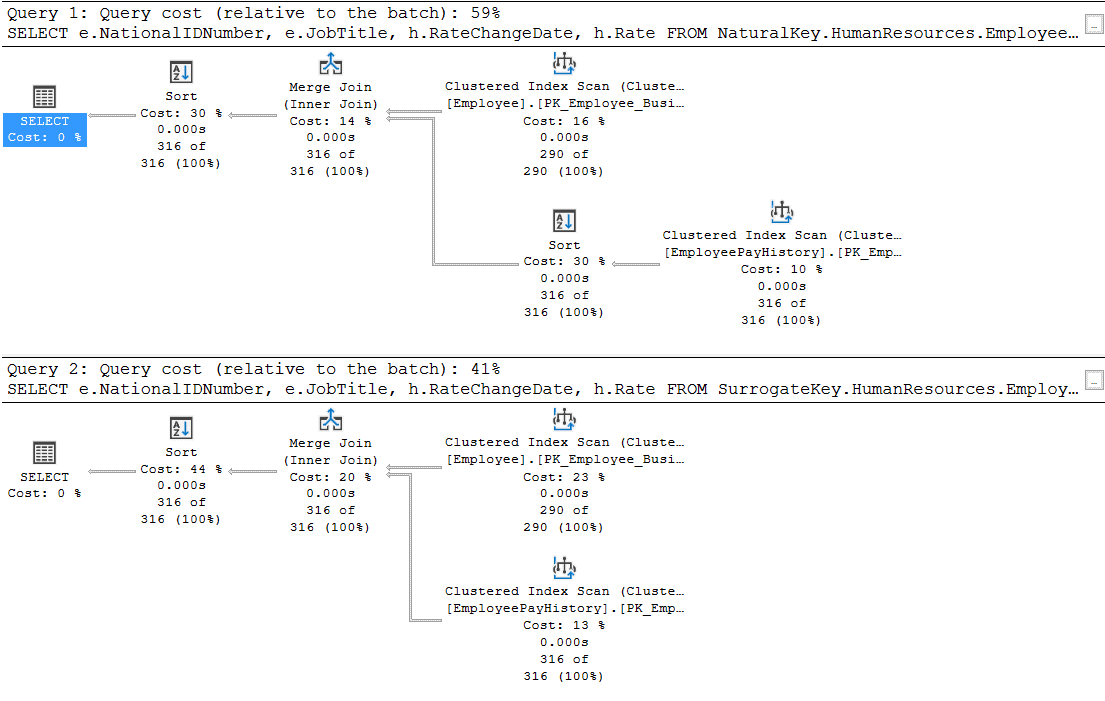
Insert costs
Whenever you insert into a table, the clustered index will determine where to place the new record(s). The database must updated the indexes as well. It will also verify any constraints on the table.
When using a natural key, you are more likely for inserts to be non-sequential. This is important when the primary key is also the clustered index. With the HumanResources.Employee table, you can assume that records inserted could have any social security number, thus being non-sequential. This will result in fragmentation of the clustered index for the table.
Surrogate keys are more likely to be sequential, if they are defined as using identity or NEWSEQUENTIALID(). Inserts with sequential values will avoid fragmentation problems by always inserting data at the end of the table. Some natural keys, such as time stamps can also be sequential. Some surrogate keys, like ones using NEWID(), are non-sequential. There are also situations where randomized inserts can actually perform better because with high end disk arrays, they can prevent hot spots when writing to a specific disk.
Below you can see the fragmentation properties of the clustered index after an insert to each version. The natural key version has increased in its fragmentation, while the surrogate key version is unaffected. Note that I modified the BusinessEntityID field in the surrogate key version to be an identity column in order to illustrate a simple relational model.
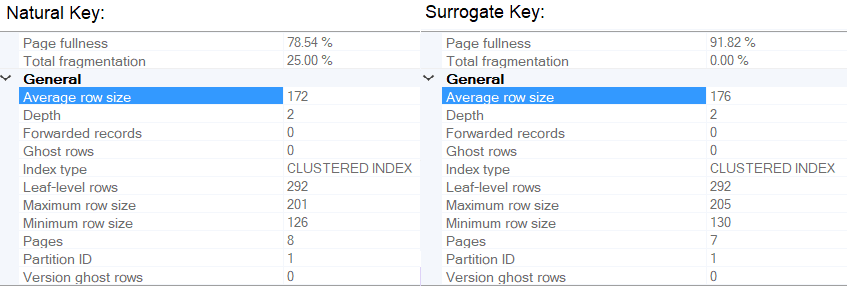
Update costs
Updating a primary key value can have significant costs involved. Doing so will likely involve fragmenting the clustered index. It will also cause the need to cascade updates to any tables referencing the value in a foreign key.
Surrogate keys have no meaning outside identifying a row, so it is rare to have any need to update them. They can usually avoid this situation entirely.
Conclusions
In most cases, using a surrogate key will take less space on disk and result in both faster reads and writes. There are exceptions, but for the above reasons, my default assumption is that a surrogate key will be better when designing a new database.
Some exceptions might include situations where no other table references this primary key, the rows referencing the primary key are fewer than in the table with the primary key itself, there is a natural key with similar space requirements to the surrogate key, or you are dealing with a temporary table.
On a personal note, I like surrogate keys, because they can be hidden from the end user. A primary key is an important programming object. I don’t want end users to care or even know about my programming objects. Using an abstract key like this frees me to make programming choices for programming reasons rather than business or user-experience reasons.
