

Have you ever needed to combine data from two different tables or queries in SQL Server? Maybe you’ve got similar data sitting in different places and you want to see all the unique values, or maybe you want to see everything, even the repeats. UNION and UNION ALL come into play here. Both are handy tools for stacking the results of two or more SELECT statements on top of each other, but they handle repeats differently.
In this article, we’ll walk through what makes them different, using simple examples to keep things clear and easy to follow. Let’s dive in with some sample data and see them in action.
To get started, we’ll set up a couple of temporary tables to play with. Imagine we’ve got two stores, each with a list of fruits they sell. We’ll call these tables #FruitsA and #FruitsB, and toss in some fruit names and the store they come from.
CREATE TABLE #FruitsA (Fruit VARCHAR(50), Store VARCHAR(50));
INSERT INTO #FruitsA (Fruit, Store) VALUES ('Apple', 'StoreA'), ('Banana', 'StoreA'), ('Orange', 'StoreA');
CREATE TABLE #FruitsB (Fruit VARCHAR(50), Store VARCHAR(50));
INSERT INTO #FruitsB (Fruit, Store) VALUES ('Banana', 'StoreB'), ('Orange', 'StoreB'), ('Pear', 'StoreB');There we go—#FruitsA has Apple, Banana, and Orange from StoreA, and #FruitsB has Banana, Orange, and Pear from StoreB. Notice that Banana and Orange show up in both tables. This overlap is perfect for showing how UNION and UNION ALL behave.
Let’s say we want to get a single list of all the different fruits sold across both stores, without any repeats. That’s a job for UNION. Check out this query:
SELECT Fruit FROM #FruitsA UNION SELECT Fruit FROM #FruitsB;
When we run this, here’s what we get:
Apple Banana Orange Pear
Pretty straightforward, right? Even though Banana and Orange are in both tables, they only show up once each in the results. UNION takes the output from both SELECT statements, stacks them together, and then tosses out any duplicate rows. We end up with just the unique fruits: Apple, Banana, Orange, and Pear.
Now, what if we don’t care about removing repeats? Maybe we want to see every fruit from both stores, including the ones that show up more than once. That’s where UNION ALL comes in. Let’s try this:
SELECT Fruit FROM #FruitsA UNION ALL SELECT Fruit FROM #FruitsB;
Here’s the output:
Apple Banana Orange Banana Orange Pear
This time, we get all the fruits from #FruitsA followed by all the fruits from #FruitsB. Banana and Orange appear twice because they’re in both tables, and UNION ALL doesn’t bother checking for duplicates—it just piles everything together as is. So we see Apple, Banana, and Orange from StoreA, then Banana, Orange, and Pear from StoreB.
One thing to keep in mind is that the order of the rows isn’t set in stone unless we tell SQL Server how to sort them. If we want these fruits in alphabetical order, we can slap an ORDER BY on the end like this:
SELECT Fruit FROM #FruitsA UNION ALL SELECT Fruit FROM #FruitsB ORDER BY Fruit;
Running that would sort everything nicely, duplicates and all. With UNION, we could do the same thing:
SELECT Fruit FROM #FruitsA UNION SELECT Fruit FROM #FruitsB ORDER BY Fruit;
That would give us the unique fruits—Apple, Banana, Orange, Pear—in order. The ORDER BY applies to the whole result, not just one part, which is why it goes at the end.
So, when would you pick UNION over UNION ALL, or the other way around?
If you’re after a clean list with no repeats—like all the unique fruits sold across both stores—UNION is your go-to. But if you want every single row, repeats included—say you’re tracking total inventory or combining log entries—then UNION ALL is the way to go. UNION ALL can also be a bit quicker since it doesn’t have to spend time looking for duplicates, though the main thing to think about is what you want your results to look like.
Both UNION and UNION ALL have a couple of rules to follow. The SELECT statements you’re combining need to have the same number of columns, and the data types have to match up—or at least be close enough that SQL Server can figure it out. For example, you can’t mix a query with one column and another with two. Also, the column names in the final result come from the first SELECT. Check this out:
SELECT Fruit AS Produce FROM #FruitsA UNION SELECT Fruit FROM #FruitsB;
The output column will be called “Produce,” not “Fruit,”

because the first SELECT sets the name. It’s a small detail, but good to know.
Let’s mix things up a bit and pull in the Store column too. Here’s what happens with UNION:
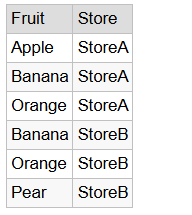
SELECT Fruit, Store FROM #FruitsA UNION SELECT Fruit, Store FROM #FruitsB;
The result looks like this:

Since each row includes both the fruit and the store, every combination here is unique—Banana from StoreA is different from Banana from StoreB. UNION only removes rows that are exactly the same across all columns, so all six rows show up. If #FruitsB also had (‘Apple’, ‘StoreA’), UNION would drop one of those because they’d match perfectly.
Now let’s try that with UNION ALL:
SELECT Fruit, Store FROM #FruitsA UNION ALL SELECT Fruit, Store FROM #FruitsB;
We’d get the same six rows,
but if there were identical rows in both tables, UNION ALL would keep them all. It doesn’t care about repeats—it just stacks everything together.
Sometimes you might want to tag each row with where it came from. With UNION ALL, since it keeps every row, you can add a little marker like this:
SELECT Fruit, 'StoreA' AS Source FROM #FruitsA UNION ALL SELECT Fruit, 'StoreB' AS Source FROM #FruitsB;
The output would be:
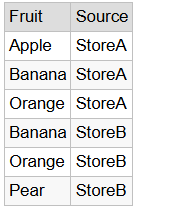
Now each row has a “Source” column telling us which store it’s from. If you tried this with UNION, it’d still keep rows distinct based on all columns—so (‘Banana’, ‘StoreA’) and (‘Banana’, ‘StoreB’) would both stay because the Source makes them different.
You can also chain more than two queries together. Say we had a third table, #FruitsC, with more fruits. We could do:
SELECT Fruit FROM #FruitsA UNION SELECT Fruit FROM #FruitsB UNION SELECT Fruit FROM #FruitsC;
That’d combine all three, keeping only unique fruits. With UNION ALL, you’d get every fruit from every table, repeats and all. Just make sure all the SELECTs have the same number of columns and matching data types.
Another neat trick is using UNION or UNION ALL with filters or other tables. For example, if we only wanted fruits starting with ‘A’ or ‘B’ from one store and everything from the other:
SELECT Fruit FROM #FruitsA WHERE Fruit LIKE '[A-B]%' UNION SELECT Fruit FROM #FruitsB;
That’d give us Apple and Banana from #FruitsA (since they start with A or B), plus Banana, Orange, and Pear from #FruitsB, with duplicates removed. Switch to UNION ALL, and you’d keep all matching rows without trimming anything.
So basically, UNION and UNION ALL are both great for combining data, but they fit their different needs. UNION is pretty good when you want a tidy list with no repeats, like unique fruits across stores. UNION ALL is the choice when you need every row, duplicates included, like when you’re merging full inventories or logs. UNION ALL might save a little time since it skips the duplicate check, but focus on what your output should be. Play around with these on your own data—it’s the best way to see how they work for you.
Hope this clears things up a bit!
