

Let's blow it up!
It's a wonderful thing to have a playpen where you can create and destroy at will. I have that here, making it quite easy to blow up replication and to fix it, over and over. However, please know that some of this experience was gained at 3:00AM on a Sunday with production down and angry C-Level executives wanting to know why our customer-facing systems were offline.
Should Peer-to-Peer Transactional Replication (PPTR) fit into your needs, perhaps my late nights can translate into helpful advice to turn my 12 hours into your three minutes.
Let's Engineer the Disaster
To give context, I'm using the replication topology created in Part 2 of this series: Two databases named Tinker1 and Tinker 2. One table named foobar. Foobar has an Identity PK that has different ranges per node, set by DBCC CHECKIDENT. It also has a natural primary key with an unique nonclustered index.
Sowing the Seeds of Disaster
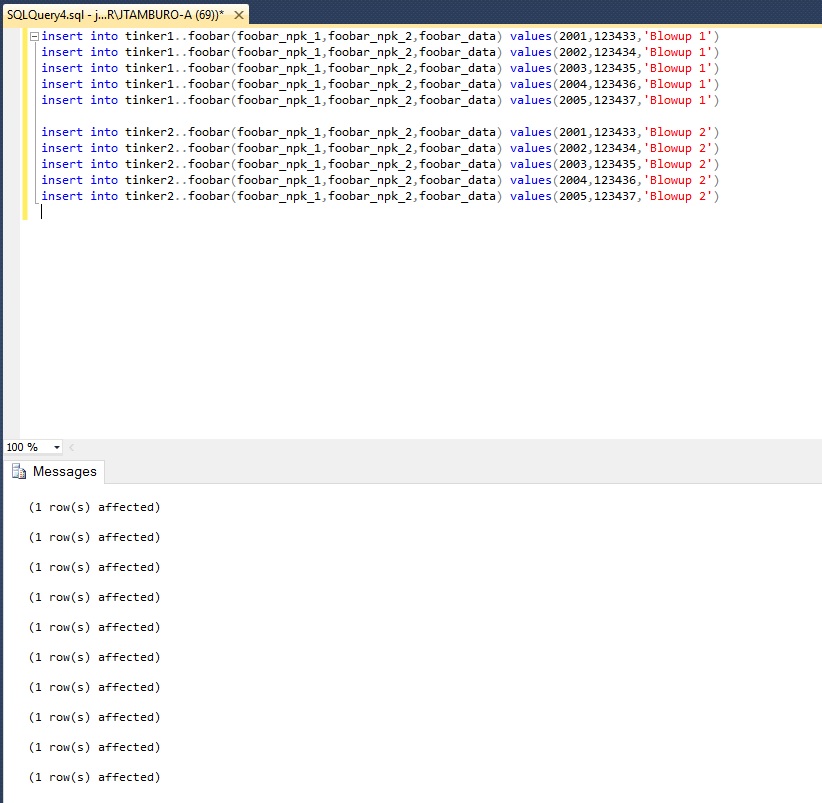
We will now add rows with duplicate primary keys into the foobar table on each rapidly, so that replication does not have a chance to deliver the changes to the other node:
Diagnosis
This set of inserts goes as expected. Now let's go to Replication Monitor and view the details on each node's subscription:
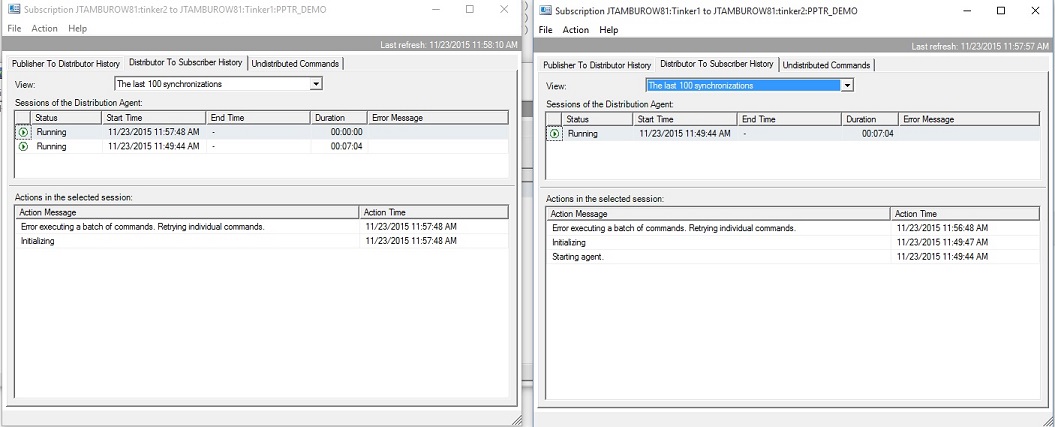
Unfortunately, the agent profile gives us little to understand what happened. So, we go to "Verbose agent profile" for each distribution agent and restart. That is also unhelpful:
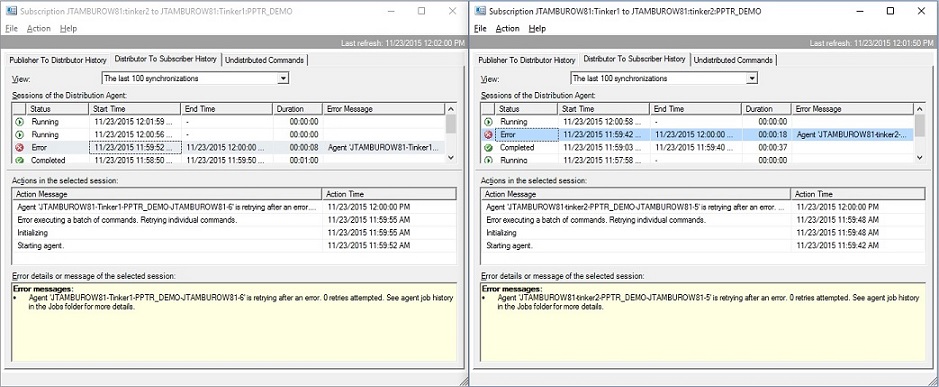
All we get are requests to go into the job history of the agent. When we do, we get a little warmer, as we look at the last entry before the retry:
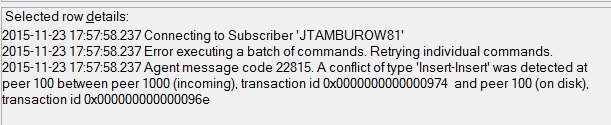
We now know that the error is an insert collision and are given the exact IDs of the offending command. But we still have no other useful information.
Let's stop all of the agents and look at the publication properties then choose Subscription Options on one node:
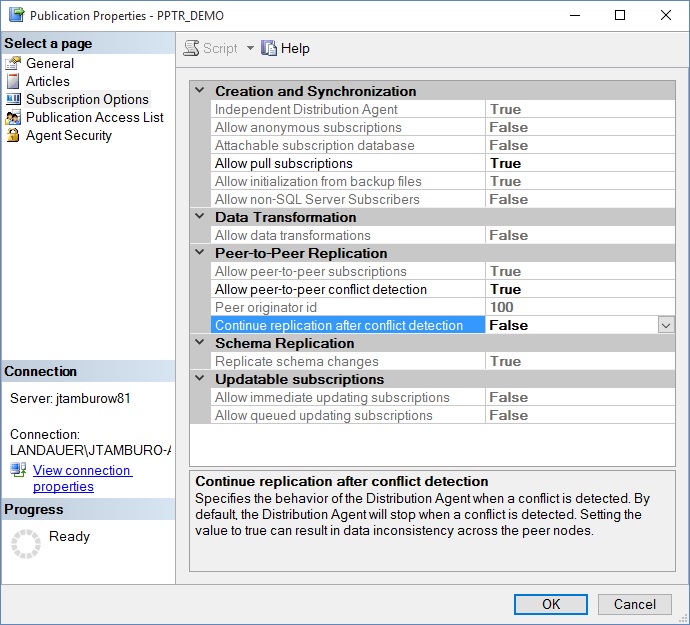
We have two options that may help. The first is: Allow peer-to-peer conflict detection, which is set to TRUE by default. I do not recommend setting this to FALSE for any reason whatsoever.
The next option is Continue replication after conflict detection. This option comes with a scary warning at the bottom of the window: "Setting the value to true can result in data inconsistency across the peer nodes." While it may sound counterintuitive, we will set this option to true at all PPTR nodes and then restart all agents.
When we come up, we see that all seems well:
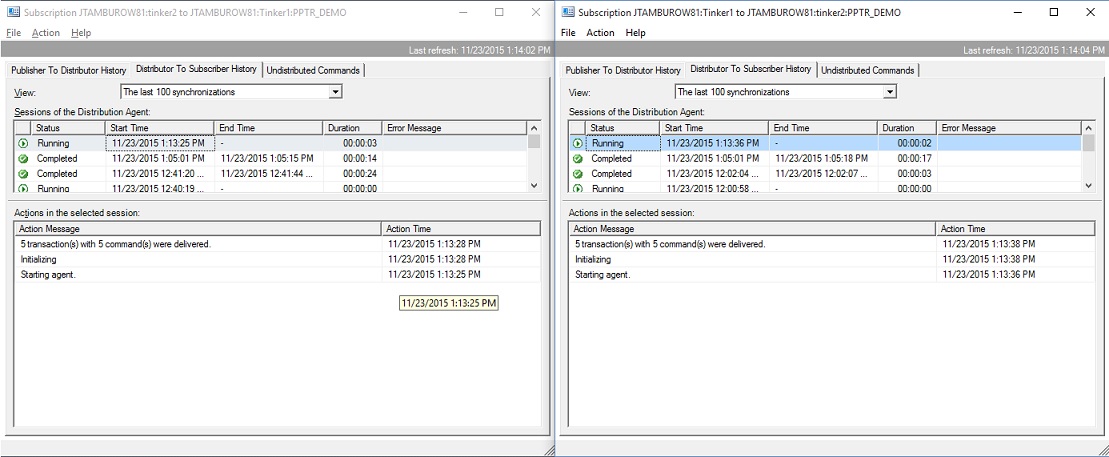
All of the commands were delivered, but what do we have in the tables? Are we consistent or inconsistent? Let's look:
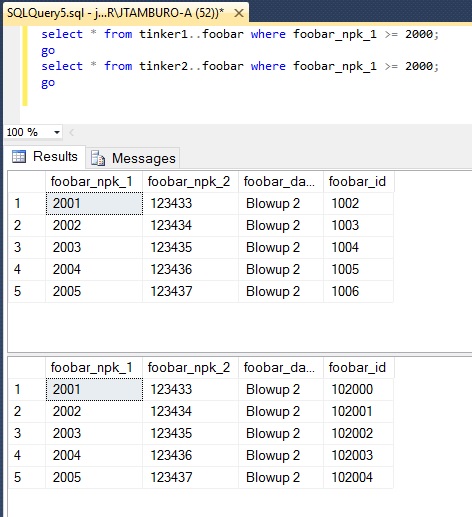
We are inconsistent on the foobar_id column; the key-violation rows were not replicated to the other peer. In this instance, we know what rows were not replicated, but what about in production?
SQL Server creates a table in each node named conflict_[schema]_[tablename], and you can examine that for more details. Here's what we see:
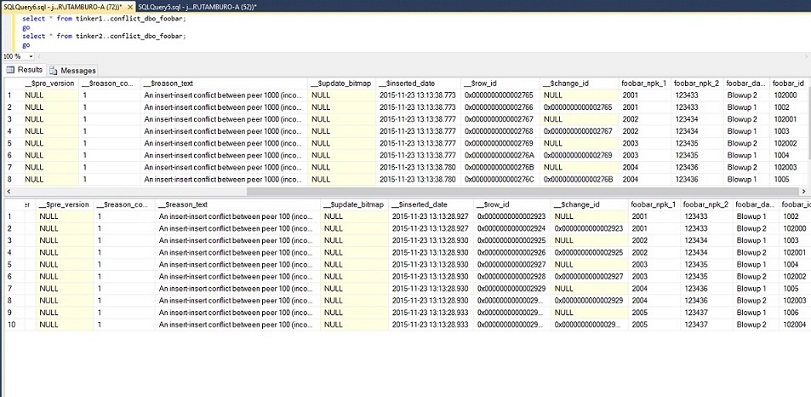
We see the exact rows that were dealt with on each node, with all columns.
Now, let's expand the _$reason_text column and read:
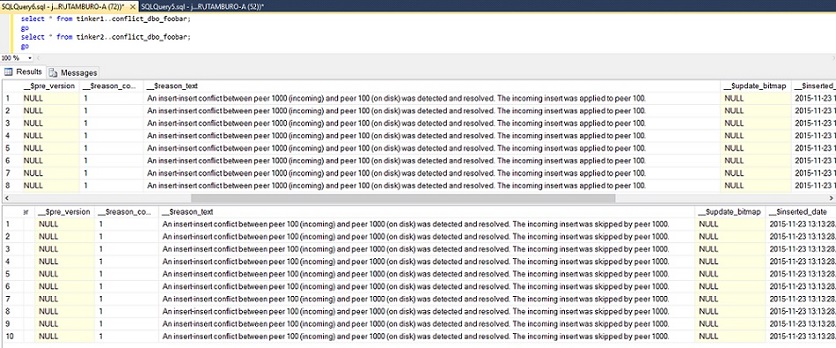
The updates at the higher numbered node were applied, and the updates at the lower numbered node were skipped. This resolves your problem in the short term and you are up and running. In the above case, we lost nothing in the way of relevant data, since the only difference is the identity column.
In production, however, we have a higher likelihood of losing data. If there are differences in the non-unique column(s), the differences offered by the lower-numbered peer node are shuffled off to the conflict table and lost to the production table. That is the risk. Microsoft's scary warning was quite accurate.
We've looked at triage, diagnosis and a quick-fix. In Part 4 (advanced Peer-to-Peer Transactional Replication), we will examine risks and remediations. We will look at other production scenarios and solutions, and conclude this series with checklists for implementation, problem triage and remediation.
-------
John F. Tamburo is the Chief Database Administrator for Landauer, Inc., the world's leading authority on radiation measurement, physics and education. John can be found at @SQLBlimp on Twitter. John also blogs at www.sqlblimp.com.
