

I recently had an experience which I think people might benefit from. The Reporting team in my firm complained that their scheduled daily reports on Business Objects were failing due to a timeout error. The timeout had been set to 10 minutes on the Business Objects server and the Remote Query Execution timeout on SQL Server was also 10 minutes.
Previously these reports were running fine, but now, the database had grown to more than 300 GB. In my investigations, I found a lot of unused/rarely used indexes, 99 % fragmentation on the drive containing the MDF file (see fig 1) and a very large table (over 160 GB), which the queries referenced.
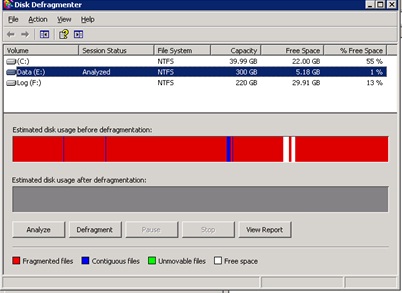
Fig. 1 State of Disk Before Deframentation
Here is a summary of the scenario:
Original Database Size | ~ 295 GB | ||
| Database Size After Index Defrag (After First Defrag Attempt) | ~ 425 GB | ||
| Table Size During the Period | ~ 170 GB | ||
| Original Data Volume Size | 300 GB | ||
| Volume Size During First Defrag Attempt (Failure) | 450 GB | ||
| Volume Size On Second Defrag Attempt (Success) | 900 GB |
My first plan was to defragment the drive and then rebuild indexes that needed to be rebuilt. But the first attempt to defragment the drive failed because there was not enough space to move the 300+ GB MDF file, which had over 400 fragments. I proceeded to rebuild ALL indexes on the large table which turned out to be a bad move because the database now grew to almost 450GB eating up almost all the additional 150GB that had been added to do the defragmentation.
I then attempted something I now know to be a very bad idea: shrink the database so as to reclaim the almost 45% free space been reported. Various attempts to do this simply failed. The disk was just in a bad shape and the database was actively being used since we couldn’t really afford a downtime for the amount of time it would take to reclaim space from a 450GB database sitting on a 99% fragmented volume. The following week, the reports could not run at all. Ouch!
In order to proceed, we extended the disk by 450 GB, thus having a total of 900GB for the data file drive. When we did the defragmentation of the drive again, it took just over 3 hours and the drive was clean as new. Windows more or less moved the entire data file to the end of the volume (which had just been extended by 100% (see Fig 2).
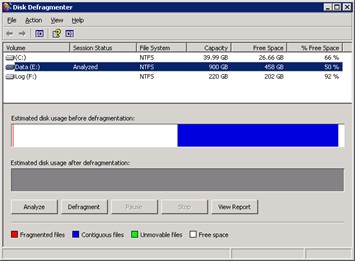
Fig. 2 State of Disk After Defragmentation
After this, the reports started running in less than 10 minutes again and asides a few exceptions, things were OK. The PAGEIOLATCH_EX and _SH waits I had noticed had dropped lower in the list of wait_stats output. The disk statistics from perfmon had also improved (I noticed this reflected after a while not immediately).
Next time I want to defragment my drive, I will definitely consider how big the largest file in in the drive is.

